
▲頭圖由AI生成
作者 | 三北
編輯 | 漠影
城市大模型正處於爆發前夕,數據很可能成為一只「攔路虎」。
當下,北京、上海、深圳等多地都推出了AI新政策,提出「在城市大腦建設中套用大模型」、「構建開放式城市大模型服務平台」等明確指示。 沈睡的城市數據 成為大模型的「養料」,同時 數量巨大、種類異構等特征也加大了大模型落地的難度 。
數據儲存 是數據價值挖掘的第一關口, 大模型正倒逼產業前進演化 。過去一年多,包括 曙光、華為等基礎設施龍頭,以及阿裏雲、騰訊雲、百度智能雲等雲廠商都面向大模型進行了數據儲存產品最佳化,動輒達數倍模型訓練效率提升。
曙光儲存營運總監石靜 告訴智東西:「從過去一年多次與客戶的溝通情況來看,大家從早期直接要PB級的 儲存容量 ,到咨詢儲存如何 讓GPU發揮更大效能 ,到現在則更加關註 契合套用需求的變化 ,這都推動曙光儲存產品不斷前進演化。」
據悉,目前, 曙光ParaStor分布式儲存產品 能將AI整體表現提升 超 20倍 ,已落地了北京、泉州、中國移動等多個AI智能化專案,並在大模型、具身智能機器人、自動駕駛、智算中心等各個領域落地,打造了AI大模型套用標桿案例。

▲曙光ParaStor分布式全閃系列產品
隨著算力、模型的價格降低, 數據成為AI產業落地的「牛鼻子」 。 如何挖掘城市中的海量數據價值,讓AI助力城市智能化發展,進而滲透到千行百業?從儲存環節來看,整個AI落地的成本壓縮邏輯是什麽樣的?
透過對話曙光儲存營運總監石靜,沿著曙光AI數據儲存落地的足跡,我們對這些問題有了深入了解。
一、AI城市大腦前進演化時,向數據儲存要成本和效率
當下,城市已成為AI落地的第一站,數據儲存成為不容忽視的短板環節。
北京、上海、廣東等一線城市及省份均釋出了將大模型與城市治理相結合的相關政策。 比如【北京市推動「人工智能+」行動計劃(2024-2025年)】提出「構建開放式城市大模型服務平台,打造智慧城市大腦」;【廣東省加快數碼政府領域通用人工智能套用工作方案】提出「探索人工智能與城市大腦等場景創新」。各地都在加速推動AI與城市智能化建設融合發展,落地城市治理、數碼政務、智慧交通、智能制造、商業等各個領域。





▲城市智能化領域AI及大模型部份核心政策(智東西梳理)
石靜告訴智東西, 在AI時代,城市智能化建設發生了較大變化。
此前,「城市大腦」更側重抓取城市數據去做智能分析,現在更主要的是 借助大模型去輔助城市決策和管理 ;此前很多專案用CPU算力就行了,現在則更多考慮 異構算力 ,GPU等AI算力占比投入大大提升。
以泉州聯合曙光推進的智慧城市專案為例 ,專案涉及圖片、語音、影片等多種業務數據,要將這些數據匯聚接入AI大模型,不僅對儲存效能和安全可靠提出更高要求,對異構數據的納管能力要求也很高。其在方案中兼顧了這些多方面需求,從而實作城市數據快速互聯,支持城市大腦中樞決策。
再以智慧交通場景為例 ,此前各地主要是將數據匯聚後來做簡單分析,現在則是透過交通垂直大模型輔助決策。曙光儲存也跟業界專門做交通大模型的廠商做了相關適配,以提供整個城市交通態勢掌控、更科學的交通調配等更多服務。
在這一過程中,忽略儲存是比較要命的。
石靜說:「算力越來越快,如果儲存跟不上,這很可能導致 GPU算力空轉或等待 ,從而使資源效率難以發揮;如果忽略儲存,一些數據質素問題的出現,也可能導致 大模型效果出現偏差 。」
具體來說,當下城市智能化行程對數據儲存提出了以下 新要求 :
1、儲存效能要更極致。 只有足夠快的儲存,才能匹配上足夠快的GPU或者AI芯片。 2、儲存更加契合使用者業務。 從通用大模型到行業生產大模型需要針對性調優,要求儲存具有一定的可客製化能力。 3、數據安全要求更高。 大模型訓練若出現中斷往往損失慘重,保障數據安全可靠尤為關鍵。 4、更強異構數據的納管能力。 面向大模型,非結構化數據的采集、匯聚、分析、處理能力提升。
「百模大戰」快速發展一年, 得益於數據儲存技術進步,城市智能化專案的計算效率大幅提升 。
石靜告訴智東西, 在頻寬指標方面 ,曙光儲存ParaStor分布式全閃單個節點已經做到最高150GB/s頻寬,也就是一秒鐘可為使用者提供150G的數據吞吐,這個指標還在快速提升中,早在兩個月前還是130GB/s。
在IOPS指標方面 ,智存ParaStor產品可以提供320萬IOPS/s,也就是一秒鐘可以處理320萬個I/O請求,相較於以前有了 十倍以上 的提升。而同樣的硬件配置下,當前市場主流產品的單節點頻寬能力普遍在100GB/s以內,單節點的IOPS能力基本在200萬以下。

▲曙光ParaStor分布式全閃在相關指標情況
二、從城市體到千行百業,數據成AI落地的「牛鼻子」
眾所周知,AI大模型落地,受到算力、演算法和數據「三駕馬車」牽引。
石靜談道,在前期大家更多關心模型、算力如何,但隨著AI的發展,數據應該排到更靠前的位置。 大模型能否很好地指導各行各業的發展?儲存所承載的數據質素非常關鍵。
今年1月4日,國家數據局等17部門聯合印發【「數據要素×」三年行動計劃(2024—2026年)】(簡稱:行動計劃),提出選取工業制造、現代農業、商貿流通、交通運輸、金融服務等12個行業和領域,推動發揮數據要素乘數效應,釋放數據要素價值。
從城市到千行百業,新一代智存技術已經在促進「數據要素x」發展。
在熱門的具身智能領域 ,「天才少年」稚輝君創辦的 智元機器人 剛剛在8月釋出了第一代具身智能機器人遠征A1,號稱達200TOPS算力。基於曙光ParaStor分布式全快閃記憶體儲提供與算力匹配的高效能儲存池,智元機器人在大模型訓練中實作了 儲存的低延時、高IO吞吐 ,從而 釋放了強大的AI算力 。
在自動駕駛領域 ,國內知名 造車新勢力 透過模型模擬仿真,加速新車型從量產走向市場,曙光在2022~2024年連續為其提供 超百PB的儲存資源 ,包括透過NVMe全閃產品提供單節點45GB/s頻寬和百萬級IOPS,最大化提升自動駕駛模型訓練效率;3天內幫助使用者從幾十個節點擴充套件到200+節點,應對擴充套件中的數據挑戰;儲存負載率長期維持在 85%以上 ,保障數據的完整性和可靠性。
在智算中心領域 , 中國移動 在2022年啟動了 全球營運商最大單體智算中心 ,針對中心所需的海量非結構化數據承載、多協定互融等儲存需求,曙光ParaStor滿足了其對儲存靈活性的需求,順暢完成 全域統一排程與管理 ,為專案未來超大規模模型跨地域、多中心並列訓練提供了存力保障。
而聚焦AI大模型生產本身 ,曙光ParaStor分布式全快閃記憶體儲支持 某AI大模型廠商 億級檔數據訓練及推理,相比原系統提效 50% ,最終相隔兩月內即釋出上線大模型新版本;支持某科技大模型廠商整體訓練效率提升 50%以上 。
可以看到,從城市體到千行百業都在加速智能化,當模型和算力價格降低,數據正成為AI落地新的「牛鼻子」。

▲曙光儲存產品全家福
三、強者恒存,曙光儲存跑出中國AI加速度
AI大模型飛速發展,也反過來倒逼儲存產業升級。
在過去一年多時間裏,包括曙光、華為等基礎設施龍頭企業,以及阿裏雲、騰訊雲、百度智能雲等雲廠商,都針對AI大模型研發與落地的全流程,對儲存產品進行了效能最佳化。 各大廠商的儲存產品的最佳化方向具有一致性 ,都強調 高效能、多協定、可客製、高安全 等提升。
其中,作為深耕AI儲存多年的頭部玩家, 曙光ParaStor分布式全快閃記憶體儲 將AI整體表現提升了 超20倍 。這是如何實作的?
石靜告訴智東西,曙光是從 兩大核心 去解決的,可以總結成: 最強的數據底座、最佳的AI套用加速套件 。
在數據底座方面 ,儲存就是要去發揮極致的硬件效能,軟件要把CPU、記憶體、網絡和硬碟介質的效能發揮出來。在AI方面,現在大家都在透過高速網絡,加上NVMe SSD快閃記憶體介質去實作,儲存軟件把高速網絡跟NVMe介質的協同發揮出來,實作最高效能。
在AI套用加速套件方面 ,這需要結合AI方向特殊的一些套用模式做最佳化。曙光有 五大加速技術方案 ,能夠透過分析AI整個的流程去盡量縮短整個I/O流程,讓GPU更加靠近儲存,或者說讓儲存更加靠近於視訊記憶體。
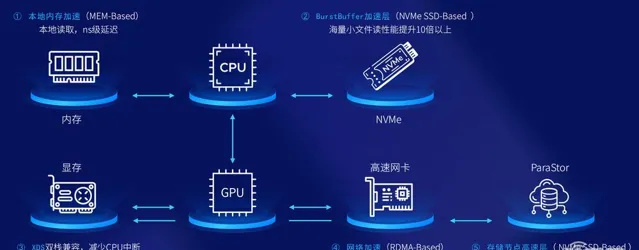
▲曙光AI套用加速套件五級加速
具體展開這五級加速,覆蓋了數據流動到GPU伺服器、網絡和儲存的整個階段:
1、本地記憶體加速。 首先把計算節點本身的CPU對應記憶體利用起來,將一些關鍵的數據緩存在那裏,做第一層加速層,延時降至納秒級別。
2、BurstBuffer加速層。 進一步把GPU伺服器原生的NVMe盤利用起來,它相較本地記憶體容量大很多,把這些數據緩存起來以後,就能夠保證海量數據不用跨網絡存取儲存,把讀取效能提高幾倍甚至十倍以上。本地記憶體加速和BurstBuffer都是聚焦計算節點本身。
3、XDS雙棧相容,減少CPU中斷。 讓GPU去直通存取儲存,縮短整個I/O通路;不光實作GPU跟儲存的直接互動,還透過儲存技術讓AI智能芯片跟儲存直接打交道,從而減少CPU本身的損耗,降低延時。
4、網絡加速(RDMA-Based)。 在網絡層,用RDMA技術等技術,不管是IB網絡還是在乙太網路裏,RDMA或RoCE都能夠把網絡頻寬給跑滿,實作第三層加速。
5、儲存節點高速層( NVMe SSD-Based )。 最後是儲存本身,當下在AI套用最多的主要是NVMe全快閃記憶體,把全快閃記憶體本身的效能充分發揮出來。
深耕儲存領域20年,曙光不僅在技術前進演化方面緊跟市場需求發展,還不斷推進 儲存產業開放生態建設 。
石靜稱,目前,曙光儲存在國產和非國產硬件上都充分開放,透過軟硬件一體形態支持客戶搭建數據底座;儲存與多種前端套用計算節點平台相容,支持國內外AI芯片直通儲存;儲存相容更多AI套用,透過智能I/O分析工具輔助其儲存更好地契合套用,做到套用開放。
強者恒存,曙光正跑出中國AI的加速度。
可以看到, 大模型發展不僅推動國產儲存廠家不斷實作技術突破,還以更加開放的心態推動軟硬件相容、計算平台相容及套用相容,從而強化AI落地。
結語:從曙光的AI足跡,看到數碼山河間的中國速度
隨著大模型落地各行各業,加速已成為AI數據儲存的核心需求。從曙光城市智能化到各行各業的AI落地案例來看,其儲存方案透過縮短數據讀寫時間,大大提升了AI大模型的訓練效率,減少算力的空轉等待時間,從而降低AI成本。
20年篳路藍縷,曙光儲存伴隨著中國資訊化、數碼化和智能化轉型一路發展。當下,大模型成為全球科技競賽的主賽場,以曙光為代表的國產ICT龍頭正透過更精尖的技術、更貼近場景的服務、更開放的生態助力國內大模型產業發展,跑出數碼山河間的中國速度。










