文 |AI藍媒匯 作者|陶然,編輯|魏曉
國內最頂尖的這些大模型初創公司,現在站到了該做取舍的十字路口。
十月初,市場中傳出訊息,稱智譜AI、零一萬物、MiniMax、百川智能、月之暗面、階躍星辰這六家被稱為「AI六小虎」的中國大模型獨角獸中,有兩家公司已經決定逐步放棄預訓練模型,縮減了預訓練演算法團隊人數,業務重心轉向AI套用。
所謂預訓練,一般指的是利用大規模數據對模型進行無特定任務的初步訓練,讓模型學習到通用的語言模式、知識和特征等。
好比是給一個還不太懂事的孩子(模型)看大量資料(大規模數據),讓他在這個過程中不斷學習各種知識、認識各種事物的樣子和規律(通用的語言模式、知識和特征)。
雖然這個孩子一開始並不知道具體要做什麽任務,但透過廣泛學習,會形成相對全面的知識儲備。
之後,如果要讓這個孩子去完成特定的任務,比如寫作文、做數學題等,就可以針對這些具體任務專門最佳化適配。
但問題是,這種籠統的大規模訓練往往價格不菲,且過程多有不確定性,每次基礎模型叠代的訓練成本動輒就會達到百萬、千萬甚至數億美金這個量級。
在討論AI行業現狀的播客中,Anthropic創始人 Dario Amodei 與挪威銀行首席執行Nicolai Tangen曾談到,雖然目前許多模型的訓練成本為 1 億美元,但「當今正在訓練的」一些模型的成本接近 10 億美元,且這個數碼未來還會上漲。
Amodei 表示,人工智能訓練成本將在「2025 年、2026 年,也許還有 2027 年」達到 100 億美元至 1000 億美元大關,他再次預測,100 億美元的模型可能會在明年的某個時候開始出現。
一向激進的馬斯克為了讓自家 xAI的Grok系列模型後來居上, 更是大手筆屯集了10萬張昂貴的GPU卡。
對於這些不缺資源的頭部玩家來說,預訓練是一個必選項。
但對「AI六小虎」而言,中間過程的黑箱特質,疊加投入產出比的壓力,讓預訓練的「做與不做」,成了擺在眼前的一個現實問題。
預訓練,是模型地基,更是大模型公司技術試金石
預訓練的好處顯而易見——模型可以獲得更廣泛的語言理解能力和基礎的智能表現,為後續針對特定任務的微調提供良好的基礎。它可以是後續產品研發和套用設計的強大起點,縮短開發周期,適應不同需求。
當年GPT-3橫空出世,預訓練過程為其後續在各種自然語言處理任務中的出色表現奠定了堅實基礎。在預訓練階段,GPT-3 使用了海量的互聯網文本數據,透過無監督學習的方式讓模型學習語言的統計規律和語意知識。例如,在問答任務中,經過預訓練的 GPT-3 能夠理解問題的含義,並根據其在預訓練中學習到的知識生成準確的答案。
但相對應的,預訓練也需要用到大量的算力資源和高質素數據,以及復雜的演算法和技術。
簡言之,預訓練的效果取決於兩方面:能力和資源。前者對應演算法的先進性、數據的質素和規模以及工程師的技術水平等因素,決定了模型能夠學習到多少知識和技能;後者對應計算資源的投入、數據采集和處理的成本、人才等,決定了預訓練能夠進行到何種程度和規模。
OpenAI團隊在預訓練GPT-3和GPT-4過程中消耗了大量的算力資源和高質素數據。為了訓練GPT-3,OpenAI使用了微軟提供的超級電腦系統,該系統擁有超285,000個CPU核心和10,000個GPU,訓練一次的費用高達460萬美元,總成本約1200萬美元。
GPT-3的訓練消耗了約3640 PF-days的算力,使用了45TB的預訓練數據,包括CommonCrawl、網絡文本、維基百科等。
而在訓練GPT-4時,OpenAI使用了混合專家模型(MoE),包含1.8萬億參數,透過16個專家模型來控制成本。每次前向傳播使用約2800億參數和560 TFLOPs。
據史丹佛HAI研究所釋出的AI Index報告顯示,OpenAI的GPT-4訓練成本約為7800萬美元。
模型架構和算力需求使得其訓練和部署需要大量的高效能計算資源,也就是來自輝達的A100或p00 GPU。
o1釋出之後,很多人開始大談後訓練的重要性。後訓練可以顯著提升模型在特定任務上的效能,但是它無法改變模型在預訓練階段學到的基礎特征表示。換句話說,預訓練很大程度上影響著模型效能的基準線和潛在的上限。
LlaMa 67B 與LlaMa 3.1 70B 的模型後訓練上限是不同的。同理,如果一個公司能夠在預訓練階段訓練出優於LlaMa的自有模型,那麽與在LlaMa基礎上後訓練的公司相比,前者就具備了技術上的天然優勢。
這種優勢的建立,需要技術能力,也需要算力資源—— 能力和資源 ,成為了大模型預訓練的兩個門檻。
誰放棄?誰掉隊?
這裏的能力,並非跟自家的上一代模型相比,而是跟行業現有公開成果相比,也就是那些頭部的開源大模型。
像是由Meta推出、被廣泛呼叫的LlaMa系列、馬斯克旗下xAI公司的Grok-1,以及國內阿裏雲開源的部份Qwen系列模型,都已經具備相當優秀且全面的基礎能力。
而資源,自然指向的是訓練結果的投入產出比:如果一家公司花費大量資源去做預訓練,得來的成果卻比不上那些開源的模型,那繼續堅持做預訓練就沒什麽必要了。那麽這種訓練就純粹的浪費資源,毫無價值可言。這裏的資源既包含算力、資金,也包含技術人才。
眾所周知,國內大模型「小虎」有六七家公司,智譜AI、MiniMax、零一萬物、月之暗面、百川智能、階躍星辰、DeepSeek。在大模型預訓練上,各家面臨的難題各不相同,現狀不一。或許我們可以從基座模型成績上「窺一斑而知全豹」。
由LMSYS組織的全球大模型競技場(ChatBot Arena)是全球頭部大模型企業同台競技的權威盲測平台。在最新一期的榜單上,依次出現了零一萬物的Yi-Lightning、智譜 AI 的GLM-4-Plus以及DeepSeek V2.5,這些模型都在榜單上取得了出色的成績。
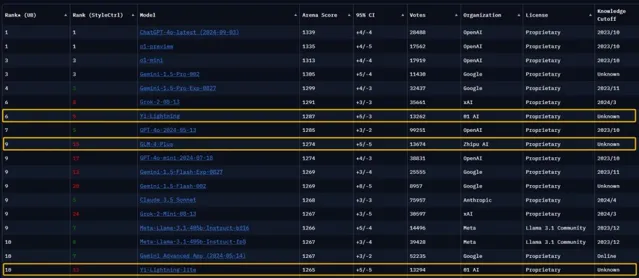
智譜 AI 一向有著「清華系國家隊」的稱號,背後的主導人物唐傑也是中國在人工智能和大模型領域頗具話語權和聲量的學術領軍人物,找融資找算力不在話下;零一萬物創始人李開復同樣在AI領域深耕多年,公司早早布局AI Infra,近期也宣布了新融資,資金算力都不成問題;DeepSeek背靠幻方量化,坐擁上萬張GPU,也沒有道理在算力充盈的情況下,放棄預訓練。
相比之下,另外幾位玩家的現狀就顯得有些「模糊」:
月之暗面從成立第一天起便亮明了ToC的決心,也由此成為多家巨頭青睞的物件,目前也是大模型初創中估值最高的企業。但除首次釋出會上釋出Moonshot大模型(後改名為Kimi大模型)、並宣布聚焦長文本能力之外,月之暗面再未對外透露更多基座模型的訊息。業內更有聲音傳出,月之暗面的基座模型是在已有模型基礎上微調得來的,縫合了多種工程模組後才達到了目前的效果。
而實際上,大模型預訓練除長文本之外,還有諸多技術點同樣值得攻堅:MoE(Mixture of Experts,混合專家模型)模型架構、多模態、RAG(Retrieval-augmented Generation,檢索增強生成)、SSM(Structured State Space Models,結構化狀態空間序列模型)、o1的COT(Chain of Thought,思維鏈) tokens、RL(Reinforcement Learning,強化學習)。這些都需要真金白銀與技術人才的投入,對於發力ToC套用、選擇在行銷獲客方面大量投入的月之暗面而言,繼續去做大模型預訓練,投入產出比似乎並不高。
背靠上海國投的階躍星辰、MiniMax同樣不缺資源。據上觀新聞報道,上海國投已經與階躍星辰、MiniMax簽署了戰略合作協定。
但單就預訓練階段來說,MiniMax似乎面臨著與月之暗面同樣的尷尬局面。MiniMax的海外套用矩陣中,Talkie已成為頭部出海產品,海螺引起全球矚目,但ABAB大模型很久未有新進展,也沒有在LMSYS等平台上出現。
在諸位「小虎」中最晚亮相的階躍星辰則急於證明自己的技術實力,年中密集地釋出了千億參數Step-1和萬億參數Step-2。在階躍星辰的宣發中,Step-2 萬億參數語言大模型的模型效能逼近 GPT-4,但在LiveBench、Arena-Hard、MT-Bench等國際權威Benchmark上成績仍弱於GPT-4-1107。
越發活躍的階躍星辰的另一面,則是技術低調的百川智能。從2023年8個月釋出8款模型,到2024年僅釋出3款模型,百川智能在基座模型上的腳步在不斷降速。最新一代基座大模型Baichuan 4選擇打榜國內商業化榜單SuperCLUE,如LMSYS ChatBot Arena、AlpacaEval 等有學術背景、相對公正的國際權威榜單上,Baichuan大模型卻未上榜或未獲好成績。
其實,對於預訓練「知難而退」,並非一種難以啟齒的消極行為。甚至,在當前的大環境下,對於某些公司來說,是一個極為理智的選擇。
當前行業基礎模型過剩卻少有破圈套用產品湧現。錘子多而釘子少。利用行業中頭部資源、開源大模型去做調優,出套用產品,務實的選擇才更能在大模型的紅海中找到適合自己身份,節省資源同時創造價值。
只是在選擇放棄預訓練的同時,也意味著走下了AGI的牌桌, 將自家模型和套用的上限拱手讓於開源模型。
至此,什麽樣的玩家,可以留在AI預訓練這場豪賭的牌桌,答案日漸清晰。
預訓練成大模型公司靈魂考驗,人才流動頻繁
從尖端芯片到美元投資,中美之間在科技領域的競爭會愈演愈烈。LlaMa、Mixtral等開源模型系列未來前景如何仍未可知。根據美國政府最新釋出的資訊,美國即將出台限制某些針對中國人工智能投資的新規,相關規則目前正在最終稽核階段,預計會在一周內釋出。
掌握預訓練能力,才能保證自己不下全球大模型競爭的牌桌。隨著中美科技角力的加劇,頂尖人才資源的爭奪戰已然成為焦點,一場圍繞人才的戰略較量早已爆發。
有多位長期關註AI領域的獵頭反饋稱,自ChatGPT爆火之後,國內對於AI領域的頂級研發人才的需求持續走高。
國內的人才爭奪同樣激烈。如阿裏通義千問大模型技術負責人周暢近期被曝出離職訊息;曾任職於曠視研究院的周昕宇選擇加盟月之暗面;秦禹嘉被曝從面壁智能離職後,2024年初創立序智科技,數月後加入字節跳動大模型研究院。
原滴滴出行AI Labs首席演算法工程師李先剛更是被曝在一年多時間內從貝殼跳槽到零一萬物、百川智能兩家「AI小虎」公司,前陣子被曝又回到貝殼。「獵頭圈爆料,他先從貝殼到零一萬物,再到百川智能,又回貝殼,每家公司都只待了幾個月。」
2023年初時曾傳出「字節跳動以140萬美元年薪從OpenAI挖人」的傳聞。2024年6月,李開復也曾在接受媒體采訪時表示,自己已經化身世界上最大的AI獵頭招攬世界上最優秀的人才。隨後零一萬物便公開表態,已有多位負責模型訓練、AI Infra、多模態和產品的國際大咖於數月前加盟。
人才資源的投入在模型預訓練方面立竿見影。字節跳動自研豆包大模型一經釋出便在業內以高性價比聞名。零一萬物也被傳團隊調整,但並未影響到模型進展——僅用了2000張GPU、1個半月時間就訓練出了超越GPT-4o(5月份版本)的Yi-Lightning,這也是目前中國大模型公司在LMSYS榜單上的歷史最佳成績。
一位資深大模型從業者告訴筆者,預訓練人才在頂尖公司之間互相流動是非常正常的現象,OpenAI、Google、微軟、Meta、xAI之間也是如此。
「一個模型效能要做到世界第一梯隊,而且又快又便宜,讓使用者都用得好用得起,需要這個大模型公司的模型訓練團隊、AI Infra團隊都具備世界頂尖水準,而且要深度共建共創,才能‘多快好省’地做出頂尖模型。」上述從業者說, 「隨著競爭壁壘越來越高,‘單靠挖一位演算法負責人就能搞定一切’,這是非常不切實際的想法。」
在這方面,國內頭部大模型公司也是「八仙過海、各顯神通」。阿裏巴巴、字節跳動本身具備豐富的算力資源, DeepSeek背後的幻方量化也曾豪擲千金購置了上萬張GPU。零一萬物則選擇從Day 1起「模基共建」,邀請來自阿裏、華為等大廠的高管、骨幹加盟組建AI Infra核心團隊。
英國【金融時報】近期報道給出了一份「第一陣營名單」,初創「小虎」零一萬物、DeepSeek透過MoE模型架構和推理最佳化,大廠阿裏巴巴、字節跳動等憑借著技術、資源訓練出了具備國際競爭力的模型,阿裏的Qwen、字節的Doubao、零一的Yi、DeepSeek系列模型即便在海外同樣享有極高知名度。
從模型效能的角度來說,堅持預訓練不僅將模型上限掌握在了自己手中,同時也牢牢把握住了推理成本的最佳化空間。只有從頭到尾走過預訓練的路,才能夠深入了解模型架構,與AI Infra團隊深度共建,以軟硬件協同逼近理論上的最低推理成本。
從套用落地的角度來講,一個關鍵點除了成本,還有安全性——模型是否自主可控。 與接入開源模型相比,走過從0到1整個過程的自研預訓練模型無疑是更加安全可控的。對於企業級和政府級客戶而言,這一點尤為關鍵,因為這直接關系到他們的核心利益和關切。
換言之,無論是從基座模型的角度,還是從套用落地的角度,預訓練能力都是大模型企業的「壓艙石」。而對於預訓練本身,經過能力和資源兩道門檻的區隔之後,註定會是一場玩家不多的遊戲。因為高手,本就應該不多。
阿裏巴巴、字節跳動等大廠入局之後,大模型初創公司在資源方面的劣勢一覽無遺。也正因如此,能力方面的重要性得以凸顯,如何以各家技術實力追平資源差距是每家大模型初創公司都需要思考的問題。
LlaMa 3.1 405B、Qwen-Max等頂尖開源模型的釋出像是一次次的警鐘,催促著大模型初創公司盡早做出選擇。
演算法、AI Infra能力強,能夠以各種方式降低訓模成本和推理成本;資源整合能力強,能夠支撐公司不斷在模型預訓練上作出新嘗試。
能力與資源並舉,才是大模型時代能全域掌控的「硬指標」。中國大模型「小虎」們道路已經出現分野,從預訓練開始,技術領先者已經脫穎而出。有人下牌桌、有人走新路。
只是,掉隊後再趕上的難度,會越來越高。











