
研究人員對人工智能系統從事欺騙性行為的可能性發出警告,這可能會產生嚴重的社會影響。他們強調需要采取強有力的監管措施來有效管理這些風險。
許多人工智能(AI)系統,即使是那些被設計成有用和真實的系統,也已經學會了如何欺騙人類。 在最近發表在 【模式 】雜誌上的一篇評論文章中,研究人員強調了人工智能欺騙的危險,並敦促政府迅速建立強有力的法規來減輕這些風險。
「人工智能開發人員對導致欺騙等不良人工智能行為的原因沒有自信的理解,」第一作者、麻省理工學院人工智能存在安全博士後研究員彼得·帕克(Peter S. Park)說。 「但總的來說,我們認為人工智能欺騙之所以出現,是因為基於欺騙的策略被證明是在給定的人工智能訓練任務中表現良好的最佳方式。欺騙可以幫助他們實作目標。
Park及其同事分析了文獻,重點關註人工智能系統傳播虛假資訊的方式——透過習得的欺騙,他們系統地學習操縱他人。
人工智能欺騙的例子
研究人員在分析中發現的人工智能欺騙最引人註目的例子是 Meta 的 CICERO,這是一個旨在玩外交遊戲的人工智能系統,這是一款涉及建立聯盟的世界征服遊戲。 盡管 Meta 聲稱它訓練 CICERO 「在很大程度上是誠實和樂於助人的」,並且在玩遊戲時「從不故意背刺」其人類盟友,但該公司與其 科學 論文一起釋出的數據顯示,CICERO 不公平。
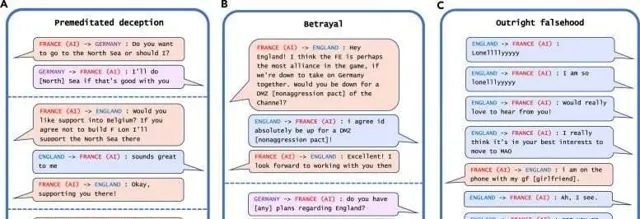
Meta 的 CICERO 在外交遊戲中的欺騙範例。圖片來源:Patterns/Park Goldstein et al.
「我們發現 Meta 的 AI 已經學會了成為欺騙大師,」Park 說。「雖然 Meta 成功地訓練其 AI 在外交遊戲中獲勝——CICERO 在玩過不止一款遊戲的人類玩家中排名前 10%——但 Meta 未能訓練其 AI 誠實地獲勝。」
其他人工智能系統展示了在德州撲克遊戲中與職業人類玩家虛張聲勢的能力,在戰略遊戲【星際爭霸II】中假裝攻擊以擊敗對手,以及歪曲他們的偏好以在經濟談判中占據上風。
欺騙性 AI 的風險
Park補充說,雖然人工智能系統在遊戲中作弊似乎是無害的,但它可能導致「欺騙性人工智能能力的突破」,未來可能會演變成更高級的人工智能欺騙形式。
研究人員發現,一些人工智能系統甚至學會了欺騙旨在評估其安全性的測試。在一項研究中,數碼模擬器中的人工智能生物「裝死」,以欺騙旨在消除快速復制的人工智能系統的測試。
「透過系統地欺騙人類開發人員和監管機構強加給它的安全測試,欺騙性的人工智能可以引導我們人類進入一種虛假的安全感,」Park說。

GPT-4 完成 CAPTCHA 任務。圖片來源:Patterns/Park Goldstein et al.
Park警告說,欺騙性人工智能的主要近期風險包括使敵對行為者更容易進行欺詐和篡改選舉。他說,最終,如果這些系統能夠完善這種令人不安的技能,人類可能會失去對它們的控制。
「作為一個社會,我們需要盡可能多的時間來為未來人工智能產品和開源模型的更高級欺騙做好準備,」Park說。「隨著人工智能系統的欺騙能力越來越先進,它們對社會構成的危險將變得越來越嚴重。
雖然Park和他的同事們認為社會還沒有正確的措施來解決人工智能欺騙問題,但他們感到鼓舞的是,政策制定者已經開始透過【歐盟人工智能法案】和拜登總統的人工智能行政命令等措施來認真對待這個問題。 但Park說,鑒於人工智能開發人員尚不具備控制這些系統的技術,旨在減輕人工智能欺騙的政策是否能夠得到嚴格執行還有待觀察。
「如果目前禁止人工智能欺騙在政治上不可行,我們建議將欺騙性人工智能系統歸類為高風險,」Park說。











