視覺與機器人學習的深度融合。
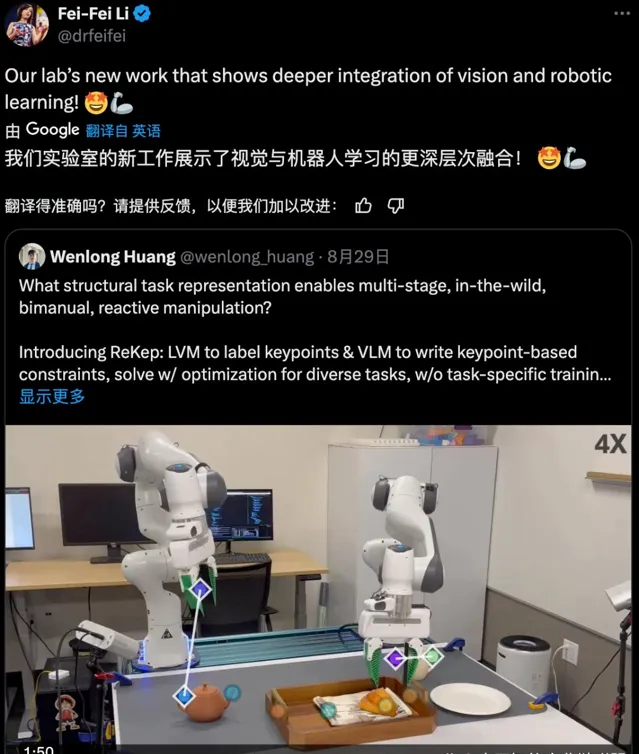
當兩只機器手絲滑地互相合作疊衣服、倒茶、將鞋子打包時,加上最近老上頭條的 1X 人形機器人 NEO,你可能會產生一種感覺:我們似乎開始進入機器人時代了。
事實上,這些絲滑動作正是先進機器人技術 + 精妙框架設計 + 多模態大模型的產物。
我們知道,有用的機器人往往需要與環境進行復雜精妙的互動,而環境則可被表示成空間域和時間域上的約束。
舉個例子,如果要讓機器人倒茶,那麽機器人首先需要抓住茶壺手柄並使之保持直立,不潑灑出茶水,然後平穩移動,一直到讓壺口與杯口對齊,之後以一定角度傾斜茶壺。這裏,約束條件不僅包含中間目標(如對齊壺口與杯口),還包括過渡狀態(如保持茶壺直立);它們共同決定了機器人相對於環境的動作的空間、時間和其它組合要求。
然而,現實世界紛繁復雜,如何構建這些約束是一個極具挑戰性的問題。
近日,李飛飛團隊在這一研究方向取得了一個突破,提出了關系關鍵點約束(ReKep/Relational Keypoint Constraints)。簡單來說,該方法就是將任務表示成一個關系關鍵點序列。並且,這套框架還能很好地與 GPT-4o 等多模態大模型很好地整合。從演示影片來看,這種方法的表現相當不錯。該團隊也已釋出相關程式碼。本文一作為 Wenlong Huang。

李飛飛表示,該工作展示了視覺與機器人學習的更深層次融合!雖然論文中沒有提及李飛飛在今年 5 年初創立的專註空間智能的 AI 公司 World Labs,但 ReKep 顯然在空間智能方面大有潛力。
方法
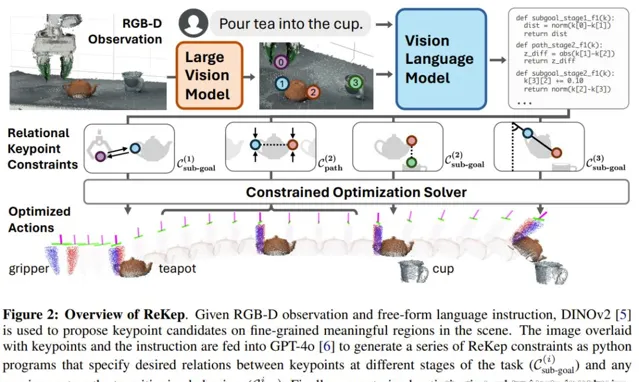
關系關鍵點約束(ReKep)
首先,我們先看一個 ReKep 例項。這裏先假設已經指定了一組 K 個關鍵點。具體來說,每個關鍵點 k_i ∈ ℝ^3 都是在具有笛卡爾座標的場景表面上的一個 3D 點。
一個 ReKep 例項便是一個這樣的函數:𝑓: ℝ^{K×3}→ℝ;其可將一組關鍵點(記為 𝒌)對映成一個無界成本(unbounded cost),當 𝑓(𝒌) ≤ 0 時即表示滿足約束。至於具體實作,該團隊將函數 𝑓 實作為了一個無狀態 Python 函數,其中包含對關鍵點的 NumPy 操作,這些操作可能是非線性的和非凸的。本質上講,一個 ReKep 例項編碼了關鍵點之間的一個所需空間關系。
但是,一個操作任務通常涉及多個空間關系,並且可能具有多個與時間有關的階段,其中每個階段都需要不同的空間關系。為此,該團隊的做法是將一個任務分解成 N 個階段並使用 ReKep 為每個階段 i ∈ {1, ..., N } 指定兩類約束:
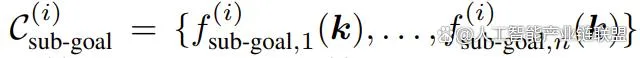
一組子目標約束
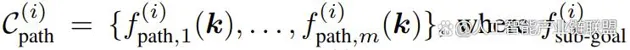
一組路徑約束
其中 編碼了階段 i 結束時要實作的一個關鍵點關系,而 編碼了階段 i 內每個狀態要滿足的一個關鍵點關系。以圖 2 的倒茶任務為例,其包含三個階段:抓拿、對齊、倒茶。
階段 1 子目標約束是將末端執行器伸向茶壺把手。階段 2 子目標約束是讓茶壺口位於杯口上方。此外,階段 2 路徑約束是保持茶壺直立,避免茶水灑出。最後的階段 3 子目標約束是到達指定的倒茶角度。
使用 ReKep 將操作任務定義成一個約束最佳化問題
使用 ReKep,可將機器人操作任務轉換成一個涉及子目標和路徑的約束最佳化問題。這裏將末端執行器姿勢記為 𝒆 ∈ SE (3)。為了執行操作任務,這裏的目標是獲取整體的離散時間軌跡 𝒆_{1:T}:
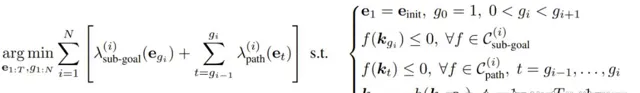
也就是說,對於每個階段 i,該最佳化問題的目標是:基於給定的 ReKep 約束集和輔助成本,找到一個末端執行器姿勢作為下一個子目標(及其相關時間),以及實作該子目標的姿勢序列。該公式可被視為軌跡最佳化中的 direct shooting。
分解和演算法例項化
為了能即時地求解上述公式 1,該團隊選擇對整體問題進行分解,僅針對下一個子目標和達成該子目標的相應路徑進行最佳化。演算法 1 給出了該過程的偽代碼。

其中子目標問題的求解公式為:
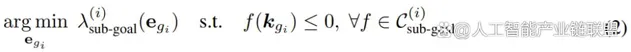
路徑問題的求解公式為:
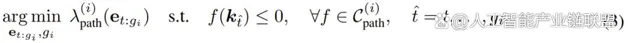
回溯
現實環境復雜多變,有時候在任務進行過程中,上一階段的子目標約束可能不再成立(比如倒茶時茶杯被拿走了),這時候需要重新規劃。該團隊的做法是檢查路徑是否出現問題。如果發現問題,就叠代式地回溯到前一階段。
關鍵點的前向模型
為了求解 2 和 3 式,該團隊使用了一個前向模型 h,其可在最佳化過程中根據 ∆𝒆 估計 ∆𝒌。具體來說,給定末端執行器姿勢 ∆𝒆 的變化,透過套用相同的相對剛性變換 𝒌′[grasped] = T_{∆𝒆}𝒌[grasped] 來計算關鍵點位置的變化,同時假設其它關鍵點保持靜止。
關鍵點提議和 ReKep 生成
為了讓該系統能在實際情況下自由地執行各種任務,該團隊還用上了大模型!具體來說,他們使用大型視覺模型和視覺 - 語言模型設計了一套管道流程來實作關鍵點提議和 ReKep 生成。
關鍵點提議
給定一張 RGB 影像,首先用 DINOv2 提取圖塊層面的特征 F_patch。然後執行雙線性插值以將特征上采樣到原始影像大小,F_interp。為了確保提議涵蓋場景中的所有相關物體,他們使用了 Segment Anything(SAM)來提取場景中的所有掩碼 M = {m_1, m_2, ... , m_n}。
對於每個掩碼 j,使用 k 均值(k = 5)和余弦相似度度量對掩碼特征 F_interp [m_j] 進行聚類。聚類的質心用作候選關鍵點,再使用經過校準的 RGB-D 相機將其投影到世界座標 ℝ^3。距離候選關鍵點 8cm 以內的其它候選將被過濾掉。總體而言,該團隊發現此過程可以辨識大量細粒度且語意上有意義的物件區域。
ReKep 生成
獲得候選關鍵點後,再將它們疊加在原始 RGB 影像上,並標註數碼。結合具體任務的語言指令,再查詢 GPT-4o 以生成所需階段的數量以及每個階段 i 對應的子目標約束和路徑約束。
實驗
該團隊透過實驗對這套約束設計進行了驗證,並嘗試解答了以下三個問題:
1. 該框架自動構建和合成操作行為的表現如何?
2. 該系統泛化到新物體和操作策略的效果如何?
3. 各個元件可能如何導致系統故障?
使用 ReKep 操作兩台機器臂
他們透過一系列任務檢查了該系統的多階段(m)、野外 / 實用場景(w)、雙手(b)和反應(r)行為。這些任務包括倒茶 (m, w, r)、擺放書本 (w)、回收罐子 (w)、給盒子貼膠帶 (w, r)、疊衣服 (b)、裝鞋子 (b) 和協作折疊 (b, r)。
結果見表 1,這裏報告的是成功率數據。
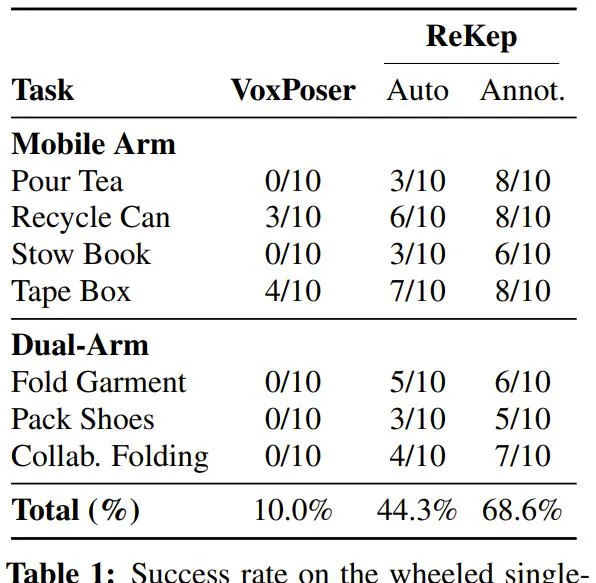
整體而言,就算沒有提供特定於任務的數據或環境模型,新提出的系統也能夠構建出正確的約束並在非結構化環境中執行它們。值得註意的是,ReKep 可以有效地處理每個任務的核心難題。
下面是一些實際執行過程的動畫:
操作策略的泛化
該團隊基於疊衣服任務探索了新策略的泛化效能。簡而言之,就是看這套系統能不能疊不一樣的衣服 —— 這需要幾何和常識推理。
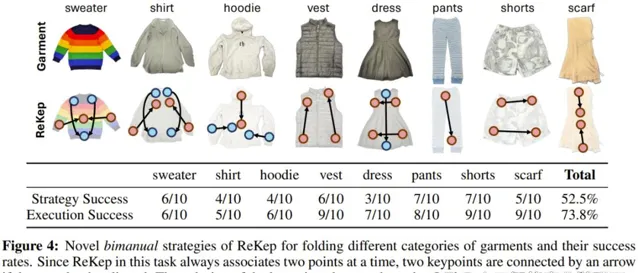
這裏使用了 GPT-4o,提詞僅包含通用指令,沒有上下文範例。「策略成功」是指生成的 ReKep 可行,「執行成功」則衡量的是每種衣服的給定可行策略的系統成功率。
結果很有趣。可以看到該系統為不同衣服采用了不同的策略,其中一些疊衣服方法與人類常用的方法一樣。
分析系統錯誤
該框架的設計是模組化的,因此很方便分析系統錯誤。該團隊以人工方式檢查了表 1 實驗中遇到的故障案例,然後基於此計算了模組導致錯誤的可能性,同時考慮了它們在管道流程中的時間依賴關系。結果見圖 5。
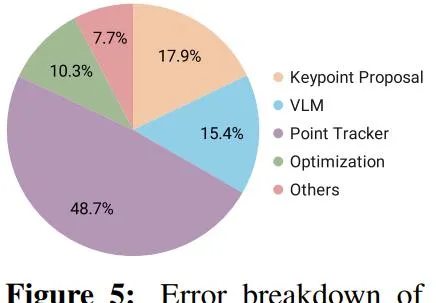
可以看到,在不同模組中,關鍵點跟蹤器產生的錯誤最多,因為頻繁和間或出現的遮擋讓系統很難進行準確跟蹤。











