大模型芯片轟向HotChips頂會!
人工智能芯片的崛起:RNGD如何撬動生成式AI的未來
人工智能的前景廣闊,但其發展歷程卻並非一帆風順。從計算能力的瓶頸,到能耗問題層出不窮,業界對於實作AI的可持續發展一直在不懈探索。然而,最近一家名為FuriosaAI的初創公司悄然崛起,憑借其創新的張量收縮處理器(TCP)架構,推出了一款名為RNGD的AI芯片,有望突破行業僵局,為生成式AI註入新的活力。
RNGD芯片的亮眼表現絕非偶然。它不僅在效能上大幅領先業內知名的輝達和AMD等GPU,更在能效方面實作了質的飛躍,可謂是真正實作了AI計算的高效能與高能效的完美平衡。這種創新成果的背後,是FuriosaAI團隊多年潛心研究和叠代的結果。
RNGD的成功絕非一日之功。FuriosaAI成立於2017年,創始團隊由三名來自AMD、高通、三星等芯片巨頭的資深工程師組成。他們在硬件和軟件領域積累了豐富的經驗,洞見了AI計算發展的痛點所在。為此,他們開啟了對新型芯片架構的研發,最終孕育出了RNGD這一代表性產品。
那麽,RNGD究竟有何獨特之處,能夠成為顛覆性的AI計算硬件?其背後的技術創新又是什麽?未來它又將如何引領AI計算的可持續發展?讓我們一起去探尋這位"AI芯片新星"的崛起之路。
引領AI計算新時代的RNGD

AI計算正在掀起一場前所未有的革命。從影像辨識到語音互動,再到智能決策,AI技術正在深入滲透人類生活的方方面面。伴隨著模型規模的不斷擴大,對計算效能的需求也呈指數級增長。但是,當前的計算硬件難以應對如此巨大的計算需求,不僅存在效能瓶頸,能耗問題更成為制約行業發展的沈重負擔。
RNGD的出現,無疑為解決這一問題帶來了新的轉機。這款由FuriosaAI研發的AI芯片,在效能、能效以及可編程性等方面都展現出了出色的表現,引發了業界廣泛關註。
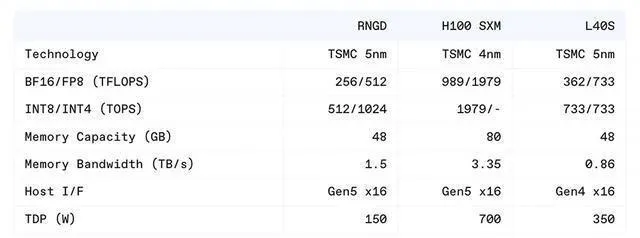
首先,在效能方面,RNGD可以輕松執行Llama 3.1等大型語言模型,單卡可提供每秒2000~3000個token的吞吐量。與輝達的p00和L40S相比,RNGD的每瓦效能分別高出2.7倍和4.1倍。這一成績來自於其創新的張量收縮處理器(TCP)架構。
與傳統的矩陣乘法不同,TCP架構采用更加通用的張量收縮運算,能夠在單個操作中組合多個維度上的元素,從而減少計算開銷,實作更廣泛的並列性。與此同時,透過采取聰明的數據重用策略,RNGD大幅降低了芯片與記憶體之間的數據傳輸,進而顯著提高了能效。
以RNGD執行Llama 3.1模型為例,其功耗僅為150W,相比同類產品要低得多。這得益於其出色的能效表現。FuriosaAI團隊表示,對於所有芯片架構來說,在DRAM和處理單元之間傳輸數據,所消耗的能量可能高達計算能量的10000倍。為此,RNGD透過精心設計的數據重用策略,最大限度地減少了數據移動,從而大幅降低了能耗。

那麽,如何實作這種數據重用呢?關鍵在於RNGD采用的張量收縮架構。與傳統的二維矩陣乘法不同,RNGD的基本數據結構是張量,這使得它能夠在執行計算之前,就充分利用張量固有的多維性質來實作更廣泛的並列性。
同時,RNGD的架構還包含一個強大的編譯器,能夠將整個AI模型視為單一融合操作,實作自動部署和最佳化。這大大提升了RNGD的可編程性,使其能夠靈活適用於快速變化的AI模型。這與GPU動態分配資源、難以準確預測效能的特點形成鮮明對比。
RNGD在效能、能效和可編程性三大方面的出色表現,無疑為生成式AI的套用註入了新的動力。它不僅能夠輕松執行Llama 3.1等大型模型,而且還可以在數據中心環境中實作高效能和低功耗的兼備,從而大幅降低企業的使用成本。這對於推動AI技術的可持續發展,意義重大。
FuriosaAI的艱辛歷程
RNGD的成功並非一蹴而就。它背後是FuriosaAI多年孜孜以求的研究與實踐成果。從創立之初,這家初創公司就堅持走自主創新的道路,聚焦於AI計算硬件的技術突破。

FuriosaAI成立於2017年,由三名資深芯片工程師聯合創辦。他們曾在AMD、高通、三星等業界巨頭工作多年,積累了紮實的硬件和軟件經驗。正是憑借這些寶貴的積累,他們洞見了當前AI計算領域存在的痛點,決心開發一款能夠真正滿足生成式AI需求的芯片產品。
在創立之初,FuriosaAI首先花費幾年時間來和驗證其自主研發的TCP架構背後的理念。這並非一項容易的工作,需要反復論證、修正和叠代,才能最終奠定未來產品的技術基礎。
完成這項基礎工作後,FuriosaAI於2021年開始與三星和華碩合作,推出了第一款基於TCP架構的Vision NPU作為商業產品。這一款面向電腦視覺的NPU,憑借出色的效能表現,成功在業界引起了廣泛關註。事實上,FuriosaAI還是唯一一家向行業標準MLPerf推理基準送出結果的AI芯片創企,結果顯示其第一代Vision NPU在視覺任務中的表現優於輝達A2芯片。
有了Vision NPU的成功驗證,FuriosaAI團隊開始著手研發面向生成式AI的新一代芯片RNGD。這一過程同樣並非一帆風順。從2022年5月收到台積電交付的第一批矽片樣品,到6月初執行Llama 3.1模型,再到7月向早期客戶交付並進行大語言模型演示,整個研發周期僅用了不到3個月的時間。這種高效的研發節奏著實讓業界刮目相看。
FuriosaAI之所以能夠實作如此高效的研發周期,首先要歸功於其對TCP架構的深入理解和持續最佳化。有了堅實的技術基礎,公司的工程師團隊得以快速將新的設計方案從概念轉化為成熟的矽樣品。
同時,FuriosaAI還采取了一種特殊的產品開發策略,即專註於快速叠代和產品交付。這不僅體現在研發周期的縮短上,也反映在公司的整體產品定位和行銷方式上。
相比行業內一些以炒作和大膽承諾為主的做法,FuriosaAI更多關註實實在在的技術創新。正如公司高管所說,Furiosa95%的人員都是工程師,行銷並非首要考慮。他們更看重的是如何透過不斷的叠代最佳化,盡快推出真正能解決使用者痛點的產品。
這種"低調"的產品策略,也反映了FuriosaAI的團隊文化。他們並不過多地關註外界的炒作,而是專註於技術創新本身。這種與眾不同的做法,恰恰成為了推動RNGD快速發展的內在動力。
從願景到實踐:Furiosa如何破解AI計算難題
RNGD的出眾表現,源於FuriosaAI團隊對AI計算領域痛點的深入洞察。

長期以來,AI計算在效能、能耗和可編程性等方面一直面臨著諸多挑戰。即使是當下最先進的GPU,也難以完全滿足高效能、高能效和高可編程性的苛刻要求。
FuriosaAI的創始團隊深知這一現狀。他們認為,要實作AI的廣泛普及和真正落地,關鍵在於開發一款能夠兼顧這三大要素的創新型芯片。這也正是RNGD誕生的初衷。
在效能方面,RNGD憑借其創新的TCP架構,能夠針對大型AI模型提供非常出色的計算能力。如前所述,單張RNGD卡就可以在Llama 3.1等大語言模型上提供每秒2000~3000個token的驚人吞吐量,遠超業界最佳水平。
這種效能優勢,主要得益於TCP架構的兩大特點:廣泛並列和高效數據重用。相比傳統的矩陣乘法,TCP透過張量收縮的方式,在單個操作中組合多個維度上的元素,從而大幅減少計算開銷,實作更廣泛的並列性。
同時,RNGD還采用了一系列聰明的數據重用策略。它將中間啟用結果直接用作下一層的輸入,無需額外的DRAM存取,大幅降低了記憶體存取開銷。這一創新使得RNGD在執行Llama 3.1等大型模型時,能耗僅為150W,遠低於業界領先的GPU。

在可編程性方面,RNGD同樣展現出了出色的表現。與依賴動態資源分配的GPU不同,RNGD搭載了一個"強大的編譯器",能夠將整個AI模型視為單一融合操作,實作自動部署和最佳化。這大大簡化了部署新模型的難度,使RNGD能夠更好地適應快速發展的AI技術創新。
正是這些創新性的設計,使得RNGD在效能、能效和可編程性三方面實作了難得的平衡。這一成果,也充分詮釋了FuriosaAI團隊提出的"AI計算普及"願景。
正如公司技術長Hanjoon Kim所言,AI硬件除了能夠並列執行多項計算之外,還必須提供可編程性與能效這兩大關鍵功能。只有做到這兩點,AI技術才能真正實作廣泛套用。
正是基於這樣的認知,FuriosaAI團隊歷經多年潛心研發,終於在RNGD芯片上取得了突破性進展。這款面向數據中心的AI芯片,不僅在效能上超越業內領先產品,更在能效和可編程性方面實作了全方位提升,無疑為AI計算的未來發展指明了新的方向。
當前,即便是最先進的GPU,在大規模部署高效能生成式AI模型時,也面臨著難以承受的經濟和環境成本。企業不僅要承擔昂貴的硬件采購費用,還需投入巨額資金用於復雜的液體冷卻系統建設,以及耗費高昂的電費。這無疑大大限制了這些技術在實際套用中的普及程度。

相比之下,RNGD憑借其出色的能效表現,能夠大幅降低這些成本負擔,為廣泛部署提供可能。有了它,企業無需再投入巨資建設高能耗的GPU集群,數據中心也無需進行復雜的基礎設施改造,就可以輕松執行高效能的生成式AI模型,大幅節省開支。
這種以使用者需求為中心的創新思路,正是FuriosaAI團隊的一大亮點。他們不滿足於單純的技術創新,而是將目光放在產品的實際套用前景上。正是瞄準了數據中心對高能效AI計算的迫切需求,RNGD才得以脫穎而出,成為當下最具影響力的AI芯片之一。
未來展望:RNGD如何引領AI計算的可持續發展
毋庸置疑,RNGD的出色表現,必將為生成式AI的未來發展註入新的動力。這款芯片不僅在效能、能效和可編程性上達到了業界頂尖水平,更重要的是,它與當前AI計算領域的實際痛點高度契合,或將成為推動行業可持續發展的關鍵推手。
當前,隨著AI模型規模的不斷擴大,對硬件計算能力的需求正呈現出爆發式增長。但傳統的GPU架構,由於效能瓶頸和能耗問題,已
當前,隨著AI模型規模的不斷擴大,對硬件計算能力的需求正呈現出爆發式增長。但傳統的GPU架構,由於效能瓶頸和能耗問題,已難以滿足日益嚴苛的計算需求。RNGD的突破性表現,無疑為解決這一難題帶來了新的希望。
這款由FuriosaAI研發的AI芯片,在能效和可編程性上達到了令人矚目的高度。其單卡功耗僅150W,相比目前市面上的GPU節能效果可謂"碾壓"級別。同時,RNGD搭載的強大編譯器,能夠自動部署和最佳化AI模型,大幅提升了可編程性,使其能夠輕松適應快速更新叠代的AI技術。
這種出色的綜合效能,必將大幅推動生成式AI在數據中心的落地套用。我們不難想象,有了RNGD這樣的高效能、高能效、高可編程的AI芯片作為支撐,企業部署和執行大型語言模型的門檻將大幅降低。從前需要耗費巨額資金建設復雜的GPU集群,如今只需幾台RNGD伺服器就能輕松應對。這必將加速生成式AI在各行各業的實際套用,讓人工智能技術真正進入千家萬戶。
同時,RNGD出色的能效表現,也必將為行業帶來重大的環境效益。當前,GPU在數據中心大規模部署過程中所產生的巨額碳排放,一直是業界關註的痛點。但有了RNGD這樣的低功耗AI芯片作為替代,企業無需再為高能耗而頭疼,不僅可以大幅節省電費支出,還能為地球貢獻一份力量,為可持續發展註入新動能。
我們相信,RNGD必將成為推動AI計算可持續發展的關鍵力量。它不僅在效能和能效方面達到了前所未有的高度,更透過可編程性的大幅提升,滿足了企業對AI技術靈活部署的需求。這種兼顧了效能、能效和可編程性的全面創新,無疑將為生成式AI註入新的活力,加速其在各行各業的廣泛套用,為人類社會的發展貢獻新的動力。
文章描述過程、圖片都來源於網絡,此文章旨倡導社會正能量,無低俗等不良引導。如涉及版權或者人物侵權問題,請及時聯系我們,我們將第一時間刪除內容!如有事件存疑部份,聯系後即刻刪除或作出更改。











