LLama 3 405B模型效果已經趕上目前最好的閉源模型比如GPT 4o和Claude 3.5,這算是開源屆的大事,技術報告接近100頁,資訊很豐富,粗略看了一下,很有啟發。這裏就LLaMA 3的模型結構、訓練過程做些解讀,並對其影響、小模型如何做、合成數據等方面談點看法。
作者:張俊林
原文連結: https://zhuanlan.zhihu.com/p/710780476
一、LLaMA 3模型結構
LLaMA 3的模型結構如圖1所示,這基本已經形成目前Dense LLM模型的標準結構了,絕大多數LLM模型結構都與此非常接近。而很多采取MOE結構的LLM模型,其變化無非是把上圖的FFN模組裏的單個SwiGLU模組拓展成K個並聯的SwiGLU模組,形成多個專家,再加上一個路由子網絡來選擇目前Token走這麽多專家裏的哪幾個,如此而已,基本結構也差不太多(所以不要誤會,MOE是Transformer的一種變體,不是獨立的模型結構。很多目前的新型結構,其實是「線性Transformer」結構的變體,目前很少有結構能逃脫Transformer架構的影響,都處在它的陰影下。當然我對新結構持支持態度,Transformer被替換只是時間問題,只不過這不是當前制約大模型能力的瓶頸,改變的迫切性沒那麽大而已)
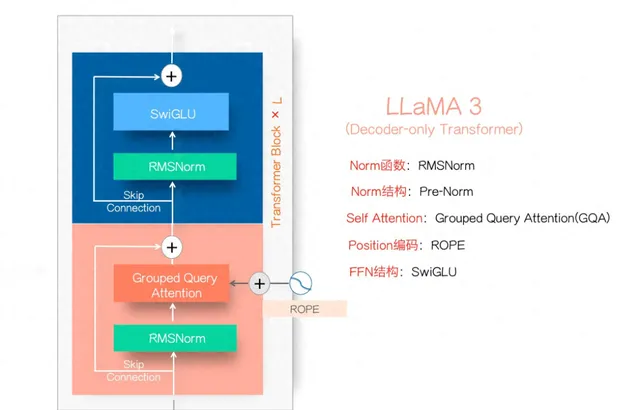
LLaMa 3模型結構
LLaMA 3的模型結構如上圖所示,這基本已經形成目前Dense LLM模型的標準結構了,絕大多數LLM模型結構都與此非常接近。而很多采取MOE結構的LLM模型,其變化無非是把上圖的FFN模組裏的單個SwiGLU模組拓展成K個並聯的SwiGLU模組,形成多個專家,再加上一個路由子網絡來選擇目前Token走這麽多專家裏的哪幾個,如此而已,基本結構也差不太多(所以不要誤會,MOE是Transformer的一種變體,不是獨立的模型結構。很多目前的新型結構,其實是「線性Transformer」結構的變體,目前很少有結構能逃脫Transformer架構的影響,都處在它的陰影下。當然我對新結構持支持態度,Transformer被替換只是時間問題,只不過這不是當前制約大模型能力的瓶頸,改變的迫切性沒那麽大而已。)
之所以LLaMA結構基本快形成行業標準,我覺得有兩個原因。原因一是側面說明了Transformer結構趨於穩定,肯定很多人試過其它變體結構但是要麽在效果,要麽在可延伸性(Scalability),總之,某一點要比這個結構效果要差,這雖然是無依據的推導,但想來是大概率事件。
原因之二是因為目前LLM已形成生態,各種衍生的工具比如快速推理框架等都相容這個結構,如果你新結構變動太大,很多流行工具不支持,就很難擴散影響力形成新的行業標準。新結構不僅僅要達成替換Transformer那麽簡單,你面對的是整個生態,再沒有確切證據表明各方面都明顯好於上述結構前提下,是很難替換掉Transformer的。從這裏就看出Meta堅決走開源路線的高明之處了,早開源早形成影響力早成為行業標準,那麽以後LLM的技術路線做技術選型話語權就非常大 ,其他人就比較被動。谷歌因為一心二用開源不堅決,有點錯失時機。
二、LLaMA 3的預訓練過程
Llama 3 預訓練包括三個主要階段:(1) 初始預訓練,(2) 長上下文預訓練,以及 (3) 退火(Annealing)。總體而言,和目前一些其它開源模型的訓練過程差別不大,不過技術報告公開了很多技術細節。
2.1 初始預訓練
就是常規的預訓練階段,訓練初期使用較小Batch Size以穩定訓練,隨後逐步增大以提高效率,最終達到 16M token 的Batch大小。為了提升模型的多語言和數學推理能力,增加了非英語和數學數據的比例。
2.2 長上下文預訓練
在預訓練的後面階段,采用長文本數據對長序列進行訓練,支持最多128K token的上下文視窗。采取逐步增加上下文視窗長度策略,在Llama 3 405B的預訓練中,從最初的8K上下文視窗開始,逐步增加上下文長度,最終達到128K上下文視窗。這個長上下文預訓練階段使用了大約800B訓練token數據。
2.3 退火(annealing)
在預訓練的最後4000萬個token期間,線性地將學習率退火至0,同時保持上下文長度為128K個token。在這一退火階段,調整了數據混合配比,以增加高質素數據比如數學、程式碼、邏輯內容的影響。最後,將若幹退火期間模型Check Point的平均值,作為最終的預訓練模型。在訓練後期對高質素數據進行上采樣目前其實也是比較標準的做法。
三、預訓練階段不同類別數據配比
不同類別的數據配比如何配置大模型才能有最好的效果?這可能是目前大模型預訓練僅剩的唯一秘密了,LLama報告對此做了披露,他們先透過小規模實驗確定最優配比,然後將之套用到大模型的訓練中。結論是:50%的通用知識Token;25%的數學與邏輯Token;17%的程式碼Token;8%的多語言Token。
四、LLaMA 3的Post-Training

LLaMA 3 Post-Training流程
目前LLM的Post-Training主要有兩種模式,一種是仿照ChatGPT的SFT+RM+PPO的模式,采用強化學習,需要調的超參很多,比較復雜不太好調通;另外一種是SFT+DPO的模式,去掉了PPO強化學習,相對簡化了整個流程,比較容易跑起來。LLaMA 3在這個階段主體結構是SFT+DPO的模式,不過也有自己特殊的一些設計,上圖展示了LLaMA 3整個Post-Training的流程。
首先用人工標註數據訓練RM模型,用來評價一個<Prompt,answer>數據的質素,然後用RM參與拒絕采樣(Rejection Sampling),就是說對於一個人工Prompt,用模型生成若幹個回答,RM給予質素打分,選擇得分最高的保留作為SFT數據,其它拋掉。這樣得到的SFT數據再加上專門增強程式碼、數學、邏輯能力的SFT數據一起,用來調整模型得到SFT模型。之後用人工標註數據來使用DPO模型調整LLM參數,DPO本質上是個二分類,就是從人工標註的<Prompt,Good Answer,Bad Answer>三後設資料裏學習,調整模型參數鼓勵模型輸出Good Answer,不輸出Bad Answer。這算完成了一個叠代輪次的Post-Training。
上述過程會反復叠代幾次,每次的流程相同,不同的地方在於拒絕采樣階段用來對給定Prompt產生回答的LLM模型,會從上一輪流程最後產生的若幹不同DPO模型(不同超參等)裏選擇最好的那個在下一輪拒絕采樣階段給Prompt生成答案。很明顯,隨著叠代的增加DPO模型越來越好,所以拒絕采樣裏能選出的最佳答案質素越來越高,SFT模型就越好,如此形成正反饋迴圈。
可以看出,盡管RLHF 和DPO兩種模式都包含RM,但是用的地方不一樣,RLHF是把RM打分用在PPO強化學習階段,而LLaMA 3則用RM來篩選高質素SFT數據。而且因為拒絕采樣的回答是由LLM產生的,可知這裏大量采用了合成數據來訓練SFT模型。
五、LLama 3 405B為何不用MOE結構?
MOE結構會讓模型效果更好嗎?答案是否定的。這個在很久以前ChatGPT火之前就有研究結論,從對模型效果的影響來說,MOE結構相對Dense模型本身並不會帶來額外優勢,甚至是有劣勢的。MOE的主要優勢是減少訓練和推理成本,付出的代價是訓練不夠穩定以及推理時額外付出大記憶體來儲存膨脹的參數量。但當使用者量大請求多的時候,推理成本占比會更高,此時使用MOE對於推理會更友好,這是為何當模型大到一定程度模型結構就會從Dense轉向MOE的主要原因,是出於成本、效率而非效果角度考慮。我之前看到有些介紹說MOE結構效果更好,這種觀點是沒有事實依據的。
Llama3 405B 之所以沒有采用MOE,技術報告指出主要是考慮到Dense模型訓練更穩定,所以選擇了Dense結構。相比GPT 4的1.8T的MOE模型結構,405B的Dense模型效果與之相當甚至要更好一些(當然,不排除GTP 4目前已經是一個蒸餾小模型的可能)。
六、LLaMA 3模型帶來的影響
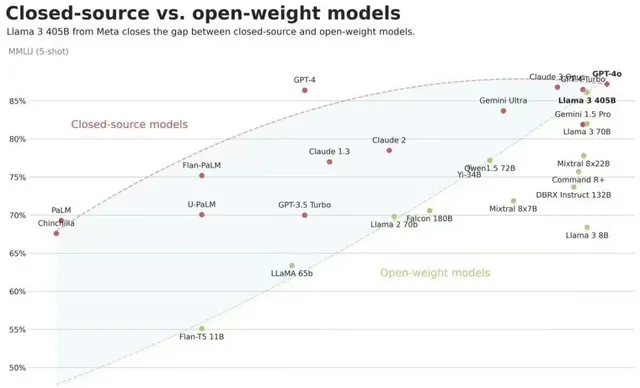
開源模型效果快速追趕閉源模型
前幾個月關於開源和閉源大模型誰優誰劣爭吵的很厲害,不同立場者各執一詞,上圖展示了開源和閉源模型隨著時間能力差異曲線,可以看出兩者差距隨著時間是逐步減小的,而LLaMA 3 405B讓兩線出現了交點,我想這圖基本可以終結「開源閉源之爭」了。
LLaMA 3 405B的開源,對於其它無論閉源還是開源模型,都有重大影響。對於閉源模型,如果其能力還趕不上LLaMA 3,就需要向公眾解釋對使用者收費的依據問題(除了覆蓋推理成本外的費用)。對於開源模型而言,如果能力不如LLaMA 3,就需要考慮如何作出差異化和不同特色的問題。目前看Meta繼續開源比如LLaMA 4等後續更強模型的決心是比較大的(畢竟從大模型開源帶來的股價上漲就能覆蓋成本了,這買賣合算的),隨著LLaMA 4的進一步開源,形勢將逼迫很多原先定位為基礎模型AGI的創業公司轉向特色產品賽道。我覺得這其實是個負面作用,尤其是對開源界,即使是開源賽道也是百家爭鳴比一兩家獨大要好,但是逐漸收斂看樣子不可避免。
我覺得之後一方面要重視LLAMA和Gemma的中文化工作,讓中文支持效果更好。如果這方面作出特點,完全可以實作小公司、小投入,但是擁有當前最強中文模型的能力,從能力角度看,並不弱於獲得大量資金支持的專業大模型公司,而從投入角度則小的多,性價比很高。
另外一方面,在做小模型的時候,要註重用LLaMA 405B這種最強開源模型來蒸餾小模型的思路,這樣做對小模型效果提升會非常明顯,很明顯這也是小投入高產出合算的買賣。
七、小模型崛起三要素
最近半年小模型在快速崛起,各種開源小模型此起彼伏,且效果也越來越好。小模型無論是訓練成本、推理成本還是對於使用者數據私密保護,相比大模型都有獨到的好處。唯一的問題是效果,只要Scaling law成立,就可以推斷出小模型效果不會比超大規模模型效果好,否則就直接反證了Scaling law是不成立的。
所以小模型的關鍵點在於:在模型規模大小受限的情況下,如何透過其它技術手段來不斷提升模型效果,最好的結局是小模型尺寸比最大模型小很多倍,但是效果逐步逼近最大模型的效果,兩者差距越來越小。
這樣美好的結局會出現麽?目前看有極大可能會達成這一目標。從最近一年各種技術進展來說,我歸納下,不斷提升小模型效果的三個關鍵因素:
第一個武器是 預訓練階段增加訓練數據數量和質素 。要打破Optimal Chinchilla Law,在保證質素前提下加大數據數量,這個肯定是有效的。去年早些時候有些模型就比較實在,比如pythia和Llama 1,嚴格遵循這個法則,導致相同規模的模型效果遠比不上那些大量增加數據的模型。後來大家都開始猛加數據,小模型的效果就越來越好。
第二個武器是 模型蒸餾 。從開源角度來看,這個武器相對較新,而且我判斷用蒸餾來提升小模型效果的能力非常強大。所謂「蒸餾」,就是說在預訓練階段小模型作為Student,大模型作為Teacher,Teacher告訴Student更多資訊來提升小模型效果。
原先小模型預訓練目標是根據上文context資訊正確預測Next Token,而蒸餾則改成Teacher把自己做相同上下文做Next Token預測的時候,把Token詞典裏每個Token的生成概率都輸出來,形成Next Token的概率分布,這就是Teacher交給Student的額外附加資訊,小模型從原先的預測Next Token改為預測Next Token的概率分布,要求和Teacher輸出的分布盡量一致,這樣就學到了Teacher的內部資訊。
Gemma 2采用模型蒸餾對於小版本模型提升非常明顯。Llama 3技術報告貌似沒有看到采用這個技術,但是在宣傳頁裏到處暗示你應該拿405B模型作為Teacher去蒸餾自己的小模型,無疑這會是很有效提升小模型能力的新武器。感覺其它模型在這裏沒有足夠的重視,而之後這應該成為普及方案。而研究怎樣的蒸餾方法是最好的會是一個重要研究領域。
第三個武器是 Annealing Data 。這個說法是Llama 3技術報告提的,但是其實去年很多模型應該已經這麽做了,只是叫法不一樣。核心思想就是在預訓練的最後階段,對高質素數據比如數學、邏輯、程式碼數據進行上采樣,增加其影響。LLama 3技術報告說這招對405B模型不怎麽起作用,但是對8B小模型在邏輯程式碼能力方面有明顯提升。
根據現有資料分析,我推斷模型蒸餾和Annealing Data很可能存在一種「反規模效應」,就是說小模型的參數規模越小,上這兩個技術對其正面影響越大。(推斷的,沒明確證據,謹慎參考)所以在研發小模型時尤其註意要引入這兩項改進,三個武器並用,我覺得作出接近最強大模型能力的小模型目前看是可行的。(其實還有一個重要因素,就是Post-Training階段合成數據的影響,這個對幾乎所有尺寸模型都成立,所以放在後面「驅動大模型效果提升三要素」分析了,對小模型也成立)
八、合成數據進入實用化階段
在Post-Training階段,合成數據目前已經產品化。尤其是其中的SFT階段,目前看在朝著完全由合成數據主導的方向發展。比如LLama 3 的SFT數據裏有相當比例是由模型生成的合成數據,而Gemma2 在SFT階段的數據很大比例是由規模更大的模型合成的,且證明了合成數據質素不比人工標註質素差。
在預訓練階段,類似Dalle-3和Sora這種由語言大模型根據圖片或影片覆寫人寫好的文字描述,也已實用化。
目前合成數據的一個重點方向是在Post-Training階段對數學、邏輯、程式碼等數據的合成,數據質素將直接極大影響模型最終效果。
嚴格來說,目前的所謂合成數據只是「半合成數據」,比如Sora的<影片,人寫文字描述<影片,模型覆寫文字描述>,以及Post-Training階段的<Prompt,人寫答案><Prompt,模型生成答案>,都是部份人工數據、部份模型生成數據,所以稱其為「半合成數據」感覺更為恰當。
如果深入思考一下,你會發現合成數據其實是模型蒸餾的一種變體,算是一種特殊的模型蒸餾。(LLM預訓練預測Next Token,其實是人類作為Teacher,LLM作為student。所以LLM本身就是對人類知識的蒸餾。合成數據是更大的模型輸出數據作為Teacher,小點的模型作為Student從中學習知識,所以其實本質上是一種模型蒸餾。)
九、驅動大模型效果提升的三要素
其實從ChatGPT火了以後看各種大模型的技術報告,包括LLama系列模型在內,可以看出大模型之所以能力仍在快速提升,主要驅動力有三個:
首先就是不斷擴大模型和數據規模(Scaling Law)。除此外,在數據方面有兩個發展趨勢:一個是越來越強調數據質素的作用,各種數據篩選方法和工具越來越多,保證質素是第一位的(這個早在Google T5時代就能推出這個結論,目前只是進一步驗證並延續這個思路而已)。
第二個是不斷增加數學、邏輯、程式碼這種能夠提升大模型理效能力的數據配比比例,包括在預訓練階段(增加預訓練數據此類數據比例,且在預訓練後面階段來上采樣此類數據,就是說同樣數據多執行幾遍,以增加其對模型參數影響的權重)和Post-Training階段(增加此類數據占比,Llama3的經過instruct的模型比僅做預訓練模型相比,各種尺寸的效果提升都很大)皆是如此。
目前看,在通用數據快被用完情況下,第三個因素會成為之後大模型進步的主導力量,包括使用數學、邏輯、程式碼合成數據在Post-Training階段的套用,目前技術也越來越成熟,其質素和數量會是決定未來大模型效果差異的最關鍵因素。
來源:【知乎】 https://zhuanlan.zhihu.com/p/710780476
llustration From IconScout By IconScout Store
-The End-
掃碼觀看 !
本周上新!

「AI技術流」原創投稿計劃
TechBeat是由將門創投建立的AI學習社區( www.techbeat.net )。 社區上線500+期talk影片,3000+篇技術幹貨文章,方向覆蓋CV/NLP/ML/Robotis等;每月定期舉辦頂會及其他線上交流活動,非週期性舉辦技術人線下聚會交流活動。我們正在努力成為AI人才喜愛的高質素、知識型交流平台,希望為AI人才打造更專業的服務和體驗,加速並陪伴其成長。
投稿內容
// 最新技術解讀/系統性知識分享 //
// 前沿資訊解說/心得經歷講述 //
投稿須知
稿件需要為原創文章,並標明作者資訊。
我們會選擇部份在深度技術解析及科研心得方向,對使用者啟發更大的文章,做原創性內容獎勵
投稿方式
發送郵件到
或添加 工作人員微信( yellowsubbj ) 投稿,溝通投稿詳情;還可以關註「將門創投」公眾號,後台回復「 投稿 」二字,獲得投稿說明。
關於我「 門 」
▼
將門 是一家以專註於 數智核心科技領域 的 新型創投機構 ,也是 北京市標桿型孵化器 。 公司致力於透過連線技術與商業,發掘和培育具有全球影響力的科技創新企業,推動企業創新發展與產業升級。
將門成立於2015年底,創始團隊由微軟創投在中國的創始團隊原班人馬構建而成,曾為微軟優選和深度孵化了126家創新的技術型創業公司。
如果您是技術領域的初創企業,不僅想獲得投資,還希望獲得一系列持續性、有價值的投後服務, 歡迎發送或者推薦專案給我「門」:











