为了让飞桨开发者们掌握第一手技术动态、让企业落地更加高效,飞桨官方在7月至10月特设【飞桨框架3.0全面解析】系列技术稿件及直播课程。技术解析加代码实战,带大家掌握包括核心框架、分布式计算、产业级大模型套件及低代码工具、前沿科学计算技术案例等多个方面的框架技术及大模型训推优化经验。本文是该系列第六篇技术解读,文末附对应直播课程详情。
大模型时代是人工智能领域的一个重要发展阶段,推理部署的重要性随之愈发凸显。它关乎到模型在产业应用中的性能表现、运行效率、成本控制以及用户体验的优劣, 是将大模型研究成果转化为实际应用的重要桥梁,对于充分发挥大模型的潜力,推动人工智能技术的广泛应用具有重要意义。
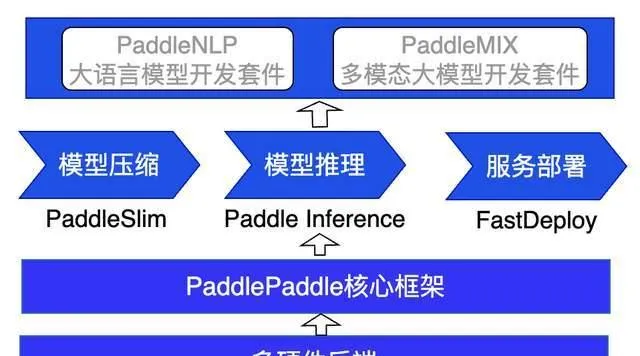
飞桨框架3.0的核心组件之一——飞桨推理引擎,本次也迎来了全面革新。此次升级 依托于高扩展性的中间表示(PIR)以及 灵活易用的 PASS 机制,显著增强了推理部署的优化效率和性能。同时,新版本的推理引擎还引入了一键转静使用 Paddle Inference 推理接口,极大地简化了从动态图到静态图的推理流程,为用户提供了更加便捷和高效的推理体验。
针对大模型在产业上部署的严苛需求,飞桨框架3.0在从大模型压缩到推理加速,再到服务化部署全流程部署能力上进行了深度优化。特别在飞桨的两大重要套件——PaddleNLP 大语言模型开发套件与 PaddleMIX 多模态大模型开发套件中,我们精心准备了详尽的全流程部署教程文档,旨在 帮助用户轻松上手,快速实现从模型训练到实际部署的无缝对接。
在硬件支持方面,飞桨推理引擎展现出了强大的兼容性和灵活性。它不仅完美支持英伟达 GPU 的多机多卡高效部署,还积极拥抱国产及国际领先的 AI 芯片生态,包括昆仑 XPU、昇腾 NPU、海光 DCU、燧原 GCU 以及英特尔 CPU 等多种硬件的推理支持。这一举措确保了飞桨能够 覆盖更广泛的部署场景,满足不同用户的多样化需求,推动大模型推理技术在更多实际业务中的应用与落地 。
特点一
大语言模型无损量化压缩方案
基于 PaddleSlim 提供的多种大语言模型 Post Training Quantization(PTQ)训练后量化技术,提供 WAC(权重/激活/KV 缓存)灵活可配的量化能力,支持 INT8、FP8、4Bit 量化能力。 针对大模型激活数值分布的特点,创新的提出并实现了分段激活平滑(Piece-wise Smooth Search,PSS)算法,相比业界常用的 SmoothQuant,有更好的平滑效果,量化损失更小。 在生成式语言大模型中,激活的数值分布非常不平滑,导致量化损失较大。相比激活,权重的数值分布相对平滑,对量化更友好。如下图所示,(a) 和(b)分别为 Llama 7B 其中一个 FFN2层输入激活和权重的数值分布。为了优化激活数值分布,可以将激活的异常值迁移到权重,使激活和权重整体的量化损失更小。业界常用的方法是 SmoothQuant,在激活通道维度上乘以一个平滑系数向量 ,同时在对应的权重上除以相同的平滑系数向量。
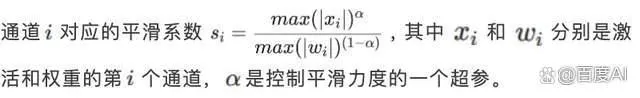
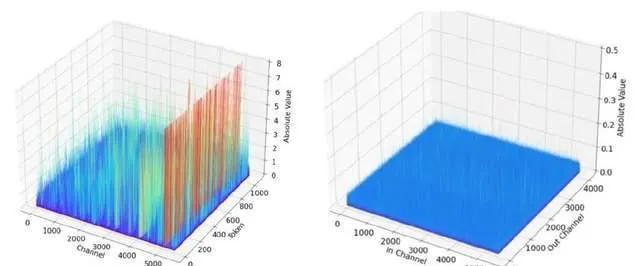

在 PaddleSlim 中实现了此方案,并在 PaddleNLP 中提供了基于 Llama 3.1等模型的完整 压缩教程 。实验表明,我们提出的 PSS 算法处理后的激活和权重的数值分布均更加平滑,量化精度更高,可以看下图(a),量化后的精度优于 SmoothQuant。下图(b)给出了激活、权重、KV Cache 通过 INT8、FP8量化后的精度值与浮点模型对比情况,可以看到 无论是基于 INT8的 W8A8(C8),还是基于 FP8的 W8A8(C8)精度均接近无损 。
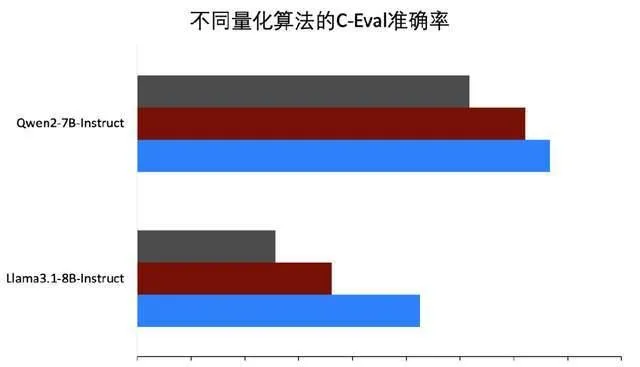
(a) PSS 效果
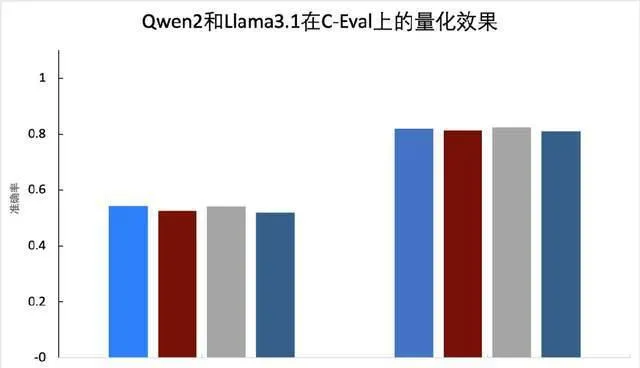
(b) 量化效果
特点二
大语言模型高性能推理优化
支持 Llama 3.1 405B 高性能部署
本次更新中,我们基于 PaddleInference 构建了大模型高性能推理方案,支持 Llama 3.0、Llama 3.1、Mixtral 等一系列大语言模型推理 。支持 Weight Only INT8及 INT4推理,支持权重、激活、Cache KV 进行 INT8、FP8量化的推理,注意力机制支持 PageAttention、FlashDecoding 等优化,支持基于 TensorCore 深度优化。
FastDeploy 基于英伟达 Triton 框架专为服务器场景的大模型服务化部署设计了解决方案。提供了支持 gRPC、HTTP 协议的服务接口。后端推理引擎采用 PaddleInference,服务与推理协同优化,支持流式输出、异步调度,支持连续批处理(continuous batching),对 Prefill 与 Decode 的计算混合调度,减少对解码时延的影响。 在集群化服务部署上,FastDeploy 可灵活控制连续批处理插入的新请求数量,支持请求动态拉取的方案,实现各实例更好地负载均衡,带来更低的首 Token 时延和更佳的用户体验。
Llama 3.1于7月份刚开源,其中 Llama 3.1 405B 是开源社区中最大的模型,飞桨推理部署也快速支持了此模型,支持 INT8、INT4、FP8的高性能部署,下面是在 PaddleNLP 大语言模型套件中的推理流程。
准备环境
(此处详细代码请进入百度AI公众号内同篇文章查看)
模型推理
(此处详细代码请进入百度AI公众号内同篇文章查看)
更详细的内容和最佳实践可以可以参考文档教程 :
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/predict/inference.md
特点三
跨模态模型一键转静推理
DiT 扩散模型性能领先
▎一键转静使用 Paddle Inference 推理接口
飞桨框架的设计上遵循动静统一的理念,静态图的图优化有助于提升推理性能,以往为了使用 Paddle Inference 的静态图推理,用户需要先导出模型、再编写推理代码,为了更方便用户直接进行静态图推理、或动静混合方式推理,
推出了
paddle.incubate.jit.inference()接口可一键转静推理
,并且支持使用 Paddle TensorRT 后端进行推理,具体使用示例如下,可以看到增加一行代码即可。在多模态模型的高性能推理加速中,我们也用此功能,通过静态图 PASS 优化能力获得加速。
(此处详细代码请进入百度AI公众号内同篇文章查看)
▎多模态模型高性能优化
多模态模型如 Stable Diffusion 及 DiT 结构在文本生成图像/视频领域、LLaVA 在图生文领域应用广泛,飞桨也对这些模型做了高性能推理优化。在 LLaVA 等图生文模型上我们直接应用了大语言模型优化技术。针对文生图及文生视频扩散类模型,我们 提供了丰富的通用图优化,如 Norm 类融合、矩阵横向融合、FlashAttention 融合高性能算子 。
以 DiT 模型优化为例,飞桨框架3.0核心设计PIR减少框架调度开销,具备更丰富的图优化 PASS,基于这些优化可直接提升推理性能。针对 DiT 模型中多个归一化 Norm 算子与 Elementwise 计算新增了融合优化,此外,还通过矩阵横向融合 PASS 将 GEMM 进行横向融合计算,使原本零散的小 GEMM 操作,融合为大 GEMM 进行统一计算。还折叠了模型组网中公共子表达式,消除模型多层的冗余计算部分。将 DiT 模型动态图推理从1325.6738ms 提升至219ms,性能提升6倍。NVIDIA A100 SXM4 40GB 硬件上测试,与 TensorRT-LLM v0.11.0性能相比,DiT 模型推理速度领先10.5%。此外,与 TensorRT v10.0性能相比, SD1.5模型推理速度领先7.9% 。
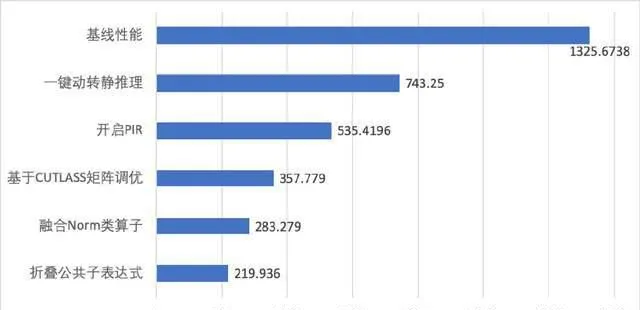
(a) DiT 模型推理优化
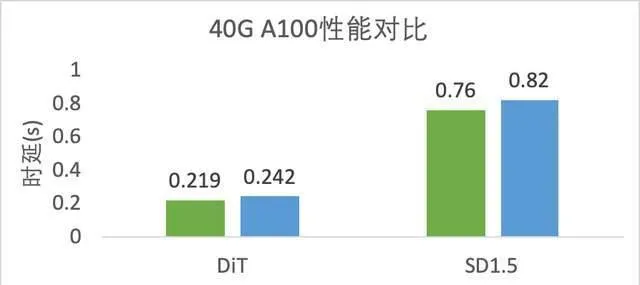
(b) 与 TensorRT/TensorRT-LLM 性能比较
特点四
多硬件大模型推理支持
基于飞桨框架还支持了昆仑XPU、昇腾NPU、海光DCU、燧原GCU、英特尔X86 CPU 等多种硬件的大模型推理, 不同硬件的推理入口保持统一,仅需修改 device 即可支持不同硬件推理 。
▎昆仑XPU 推理:
支持算子级别的融合优化,支持 PageAttention、KVCache 等常用大模型优化技术,模型算子粒度 API 对齐 GPU,使得动转静、推理、服务化部署可以统一支持。
文档传送门:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/xpu
▎昇腾NPU 推理:
飞桨基于 ATB(Ascend Transformer Boost)构建了昇腾NPU 推理,ATB 推理加速库是面向大模型领域,实现基于 Transformer 结构的神经网络推理加速引擎库,提供昇腾亲和的融合算子、通信算子、内存优化等,作为公共底座为提升大模型训练和推理性能,飞桨在此基础上,还支持了连续批处理等功能实现推理成本的极致压缩。
文档传送门:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/npu/
▎海光DCU 推理:
飞桨对海光DCU-K100AI 大模型推理功能完全对齐 GPU,支持 W8A8C8等多种量化方法,支持 Llama 系列模型,飞桨也对 K100 AI 芯片进行了性能精调,大幅度提升推理性能。
文档传送门:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/dcu_install.md
▎燧原GCU 推理:
燧原GCU 基于飞桨插件式松耦合统一硬件适配方案(CustomDevice)支持大模型推理,算子层面极致融合优化如位置编码、注意力机制、归一化算子等,使得大模型推理性能显著提升。
文档传送门:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/gcu
▎X86 CPU 推理 :
飞桨 CPU 集成 xFT(xFasterTransformer)加速引擎,基于 xDNN、oneDNN、OMP、x86-SIMD-sort 等加速库,结合 AVX512、AMX 加速指令,提供 x86架构下高性能推理能力。飞桨 CPU 支持 FP16/BF16、Weight Ony INT8等精度类型推理,支持使用 HBM 加速大模型推理。
文档传送门:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/inference.md
总结
基于飞桨框架3.0新一代中间表示PIR及更低成本的 PASS 开发机制,飞桨推理部署全面升级,并持续提升大模型推理性能。量化压缩,支持 INT8、FP8、INT4多种量化精度,支持对大模型权重、激活、KV Cache 量化的灵活组合,提供 PSS 大模型无损量化解决方案。推理部署,支持 KV Cache 量化以及 NVIDIA GPU上FP8量化推理,支持 PageAttention优化,支持 FlashDecoding 长输入序列优化技巧,支持基于 TensorCore 优化注意力机制融合算子。服务部署上,全新升级,支持对自回归解码生成模型进行连续批处理,采用 Prefill 与 Decode 混合调度模式,支持服务与推理异步调度,提供高可用的大模型服务化部署方案。在飞桨 PaddleNLP 大语言模型套件中支持了 Llama 3.1/3.0、Mixtral 等系列大语言模型推理,包括 Llama 3.1 405B 的多卡推理部署。在飞桨PaddleMIX多模态大模型套件中新增 DiT 等扩散模型优化。并新增昆仑XPU、昇腾NPU、海光DCU、燧原GCU、英特尔CPU 多硬件的大模型推理优化。
▎官方开放课程
7月至10月特设【飞桨框架3.0全面解析】直播课程, 技术解析 加 代码实战 ,带大家掌握核心框架、分布式计算、产业级大模型套件及低代码工具、前沿科学计算技术案例等多个方面的框架技术及大模型训推优化经验,实打实地帮助大家用飞桨框架3.0在实际开发工作中提效创新!

▎飞桨动态早知道
为了让优秀的飞桨开发者们掌握第一手技术动态、让企业落地更加高效,根据大家的呼声安排史上最强飞桨技术大餐!涵盖飞桨框架3.0、低代码开发工具 PaddleX、大语言模型开发套件 PaddleNLP、多模态大模型开发套件 PaddleMIX、典型产业场景下硬件适配技术等多个方向,一起来看吧!

温馨提示:以上仅为当前筹备中的部分课程,如有变动,敬请谅解。
▎拓展阅读
【飞桨官网】
https://www.paddlepaddle.org.cn/
【企业合作入口】
https://paddle.wjx.cn/vm/m3sxpfF.aspx#











