来源:半导体产业纵横

「算力」相关产业近期持续火爆,智算中心的建设,也正在遍地开花。
进入 2024 年,就有武昌智算中心、中国移动智算中心(青岛)、华南数谷智算中心、郑州人工智能计算中心、博大数据深圳前海智算中心等相继开工或投产使用。
据不完全统计,目前全国正在建设或提出建设智算中心的城市已经超过 30 个,投资规模超百亿元。
到底什么是智算中心?智算中心主要用来做什么?智算中心都有哪些特点?
何为智算中心?
根据【算力基础设施高质量发展行动计划】定义,智算中心是指通过使用 大规模异构算力资源 ,包括 通用算力(CPU) 和 智能算力(GPU、FPGA、ASIC 等) ,主要为 人工智能应用 (如人工智能深度学习模型开发、模型训练和模型推理等场景)提供所需 算力、数据和算法 的设施。
也可以说,智算中心是以人工智能计算任务为主的数据中心。
数据中心通常包括三种类别,除了智算中心以外,另外两种分别是以通用计算任务为主的通算中心,以及以超级计算任务为主的超算中心。
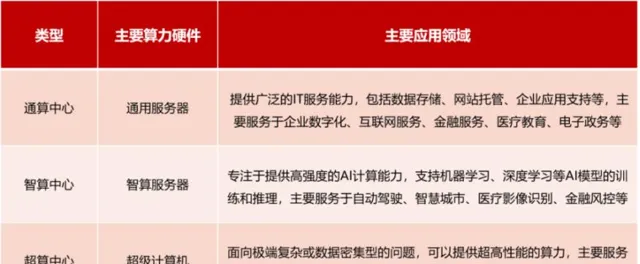
2023 年是人工智能发展的重要转折年,AIGC 技术取得了突破性进展,大模型训练、大模型应用等新业务正在快速崛起,作为智能算力的载体,数据中心也已经从数据机房、通算中心,发展到现阶段的超算中心和智算中心。
智算中心与通用数据中心有何不同?
智算中心,通常与云计算紧密相关,强调资源控制和基础设施管理的灵活性。 在云环境中,数据中心提供商负责硬件和某些软件工具的维护,而客户则拥有数据。相比之下,传统的本地数据中心需要由企业自行管理和维护所有的数据资源。
本质的不同导致两种模式在资本投入、资源部署以及安全性方面都有着极大的区别。
在资本投入上, 智算中心客户无需大量的硬件和软件成本即可选择适合自己的服务模式,如公有云、私有云或混合云;而传统数据中心的客户则需要投入大量资金来购买和维护自己所需的服务器、网络和存储设备。
在资源部署和安全性上, 智算中心的客户可随时随地通过互联网远程访问和管理自己的数据和应用,与此同时还可以享受数据中心提供商提供的专业的安全保障,如防火墙、加密、备份和恢复等;而传统数据中心的客户受到办公/指定地点的限制,且需自己进行保护和管理数据。
智算中心,简单来说就是专门服务于人工智能的数据计算中心,能够为人工智能计算提供所需的专用算力。相比传统数据中心,智算中心能满足更具针对性的需求,以及更大的计算体量和更快的计算速度,为大模型训练推理、自动驾驶、AIGC 等各垂直行业场景提供 AI 算力。
AI 智算,需要什么样的芯片?
在硬件的选择上,智算中心与传统数据中心的硬件架构也有所不同。
AI 智算,需要什么样的算力芯片?
传统数据中心的硬件架构比较单一,主要包含服务器、存储设备和网络设备。智算中心相比于此硬件架构就会更加的灵活,不同的应用场景也会选择不同的计算节点。
智算服务器是智算中心的主要算力硬件,通常采用「CPU+GPU」、「CPU+NPU」或「CPU+TPU」的异构计算架构,以充分发挥不同算力芯片在性能、成本和能耗上的优势。
GPU、NPU、TPU 的内核数量多,擅长并行计算。AI 算法涉及到大量的简单矩阵运算任务,需要强大的并行计算能力。
而传统通用服务器则是以 CPU 作为主要芯片,用于支持如云计算和边缘计算等基础通用计算。
AI 智算,需要什么样的存储芯片?
不止是算力芯片的不同,AI 智算对存储芯片也有着更高的要求。
首先是用量。智算服务器的 DRAM 容量通常是普通服务器的 8 倍,NAND 容量是普通服务器的 3 倍。甚至它的 PCB 电路板层数也明显多于传统服务器。
这也意味着智算服务器需要布局更多的存储芯片,以达到所需性能。
随着需求的水涨船高,一系列瓶颈问题也浮出水面。
一方面,传统冯诺依曼架构要求数据必须加载到内存中,导致数据处理效率低、延迟大、功耗高;另一方面,存储器墙问题使得处理器性能的增长速度远快于内存速度,造成大量数据需要在 SSD 和内存间传递;此外,CPU 挂载的 SSD 容量和带宽限制也成为性能瓶颈。
面对「存储墙」、「功耗墙」等问题,传统计算体系结构中计算存储架构亟需升级,将存储与计算有机融合,以其巨大的能效比提升潜力,才能匹配智算时代巨量数据存储需求。
针对这一系列问题,存算一体芯片或许是一个不错的答案。
除了芯片不同之外,为了充分发挥性能以及保障稳定运行,AI 服务器在架构、散热、拓扑等方面也进行了强化设计。
这些芯片,谁在布局?
算力芯片的布局情况
在 GPU 方面, GPU 擅长大规模并行计算。华为、天数智芯、摩尔线程、中科曙光、燧原科技、英伟达、英特尔、AMD 等都推出有相关的芯片。比如,华为推出了昇腾系列 AI 芯片昇腾 910 和昇腾 310 等,这些芯片专为 AI 训练和推理设计,具有高性能和低功耗的特点。昇腾系列已广泛应用于数据中心、云服务和边缘计算等领域,为智算中心提供强大的算力支持。
英伟达推出了多款针对 AI 训练和推理的 GPU 产品,如 A100、p00 等。英特尔也推出了多款 AI 芯片产品,如 Habana Labs 的 Gaudi 系列芯片,旨在与英伟达竞争。AMD 在 AI 芯片领域也有所布局,推出了 MI 系列 GPU 和 APU 产品。
在 FPGA 方面, CPU+FPGA 则结合了灵活性与高效能,适应算法快速变化。赛灵思、英特尔是市场主要参与者,相关产品有:赛灵思的 VIRTEX、KINTEX、ARTIX、SPARTAN 产品系列以及英特尔的 Agilex 产品系列;国内主要厂商包括复旦微电、紫光国微和安路科技等。
在 ASIC 方面, CPU+ASIC 提供高性能定制计算,适合特定需求。国外谷歌、英特尔、英伟达等巨头相继发布了 ASIC 芯片。国内寒武纪、华为海思、地平线等厂商也都推出了深度神经网络加速的 ASIC 芯片。
在 NPU 方面, NPU 是专门为人工智能和机器学习场景而设计的处理器。与 CPU 和 GPU 不同,NPU 在硬件结构上进行了针对性的优化,专注于执行神经网络推理等 AI 相关的计算任务。CPU 的通用性和 NPU 的专用性相结合,使得整个系统能够灵活应对各种 AI 应用场景,快速适应算法和模型的变化。
目前市场上已有众多量产的 NPU 或搭载 NPU 模块的芯片,其中知名的包括高通 Hexagon NPU、华为的昇腾系列,值得注意的是,各大厂商在芯片计算核心的设计上都有着独特的策略。
在 TPU 方面, TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,更加专注于处理大规模的深度学习任务,具备更高的计算能力和更低的延迟。TPU 也属于一种 ASIC 芯片。
在 DPU 方面, DPU 专门设计用于数据处理任务,具有高度优化的硬件结构,适用于特定领域的计算需求。不同于 CPU 用于通用计算,GPU 用于加速计算,DPU 是数据中心第三颗主力芯片。国际三大巨头英伟达、博通、英特尔的 DPU 产品占据国内大多数市场,赛灵思、Marvell、Pensando、Fungible、Amazon、Microsoft 等多家厂商在近 2-5 年内也均有 DPU 或相似架构产品生产。国内厂商包括中科驭数、芯启源、云豹智能、大禹智芯、阿里云等。
国产算力芯片走到哪一步了?
在 2024 北京移动算力网络大会上,中国移动算力中心北京节点正式投入使用,标志着我国智算中心建设进入新阶段。作为北京首个大规模训推一体智算中心,该项目占地约 57000 平方米,部署近 4000 张 AI 加速卡,AI 芯片国产化率达 33%,智能算力规模超 1000P。
北京超级云计算中心运营实体北京北龙超级云计算有限责任公司 CTO 甄亚楠近日表示,目前帮国产大模型「嫁接」国产芯片,只需 15 天左右就可以跑通。他认为算力共享会是行业大趋势,高端 GPU 算力资源需要各方努力。
近年来,中国人工智能算力芯片的市场格局主要由英伟达主导,其占据了 80% 以上的市场份额。
甄亚楠表示,「我们也非常关注国产芯片的发展,据了解,国内自研的大模型,甚至一些开源的大模型都在不断往国产芯片上去做移植。现在从芯片使用角度来讲,有些模型已经可以跑通运行了,需要追赶的方面主要在类似 GPU 这种高性能。」
「整个的国产化是分层级的,芯片属于硬件这一层,除此之外还有软件的生态。对于国产的芯片来讲,不管是框架还是生态,都需要有一定的培育周期。」甄亚楠呼吁,最终的应用方要给到国产芯片足够的信心。
存储芯片的布局情况
智算中心在存储方面需要具备高容量、高可靠性、高可用性等特点。存储设备通常采用高性能的硬盘或固态硬盘,并配备冗余的存储架构,以确保数据的安全性和可访问性。三星、美光、SK 海力士等都有相关芯片都广泛应用于数据中心、云计算等领域,为智算中心提供高性能的存储解决方案。
国内厂商近年来在 DRAM 与 NAND 技术追赶上也实现了快速发展。
除了传统的存储芯片外,智算中心还需要上文提到的新型存储—存算一体芯片发挥更大的作用。
从存算一体发展历程来看,自 2017 年起,英伟达、微软、三星等大厂提出了存算一体原型,同年国内存算一体芯片企业开始涌现。
大厂们对存算一体架构的需求是实用且落地快,而作为最接近工程落地的技术,近存计算成为大厂们的首选。诸如特斯拉、三星等拥有丰富生态的大厂以及英特尔、IBM 等传统芯片大厂都在布局近存计算。
国内初创企业则聚焦于无需考虑先进制程技术的存内计算。其中,知存科技、亿铸科技、九天睿芯等初创公司都在押注 PIM、CIM 等「存」与「算」更亲密的存算一体技术路线。亿铸科技、千芯科技等专注于大模型计算、自动驾驶等 AI 大算力场景;闪易、新忆科技、苹芯科技、知存科技等则专注于物联网、可穿戴设备、智能家居等边缘小算力场景。
亿铸科技致力于用存算一体架构设计 AI 大算力芯片,首次将忆阻器 ReRAM 和存算一体架构相结合,通过全数字化的芯片设计思路,在当前产业格局的基础上,提供一条更具性价比、更高能效比、更大算力发展空间的 AI 大算力芯片换道发展新路径。
千芯科技专注于面向人工智能和科学计算领域的大算力存算一体算力芯片与计算解决方案研发,在 2019 年率先提出可重构存算一体技术产品架构,在计算吞吐量方面相比传统 AI 芯片能够提升 10-40 倍。目前千芯科技可重构存算一体芯片(原型)已在云计算、自动驾驶感知、图像分类、车牌识别等领域试用或落地;其大算力存算一体芯片产品原型也已在国内率先通过互联网大厂内测。
知存科技的方案是重新设计存储器,利用 Flash 闪存存储单元的物理特性,对存储阵列改造和重新设计外围电路使其能够容纳更多的数据,同时将算子也存储到存储器当中,使得每个单元都能进行模拟运算并且能直接输出运算结果,以达到存算一体的目的。
智算规模占比超 30%,算力建设如火如荼
7 月初,天府智算西南算力中心正式在四川成都投运。据介绍,该中心将以算力支撑成都打造千亿级人工智能核心产业,赋能工业制造、自然科学、生物医学、科研模拟实验等领域的人工智能创新。
这不是个例。近一个月来,银川绿色智算中心项目集中开工;北京移动在京建成首个大规模训推一体智算中心,支撑高复杂度、高计算需求的百亿、千亿级大模型训练推理;郑州人工智能计算中心开工建设,总投资超 16 亿元……以智算中心为代表的数字新基建正加快建设落地。
国家统计局 7 月 15 日发布的数据显示,截至 5 月底,全国新建 5G 基站 46 万个;规划具有高性能计算机集群的智算中心达 10 余个,智能算力占算力总规模比重超过 30%。
据中国 IDC 圈不完全统计,截止 2024 年 5 月 23 日,中国大陆共有智算中心 283 座,已覆盖中国大陆所有省、自治区和直辖市。其中有投资额统计的智算中心项目 140 座,总投资额达到 4364.34 亿元。有规划算力规模统计的智算中心项目 177 座,总算力规模达到 36.93 万 PFlops。
这些「智算中心」标准不一、规模不同,算力规模一般在 50P、100P、500P、1000P,有的甚至达到 12000P 以上,虽然 AI 浪潮给智算中心带来了广阔的发展前景,但供需错配、价格昂贵、重复建设等仍然是我国算力建设面临的难题。
与此同时,多地也纷纷出台专项规划,明确未来几年建设目标,并在技术、应用、资金等方面完善支持举措。例如,江苏发布省级算力基础设施发展专项规划,提出到 2030 年全省在用总算力超过 50EFLOPS(EFLOPS 是指每秒百亿亿次浮点运算次数),智能算力占比超过 45%;甘肃提出对算力网络新型基础设施在用地、市政配套设施建设、人才引进、资金等方面给予政策支持。
「人工智能大模型等应用爆发式发展带动了智能算力需求激增。」国家信息中心信息化和产业发展部主任单志广表示,智能计算发展迅速,已经成为我国算力结构中增速最快的类型,其中大模型是智能算力的最大需求方,需求占比近六成。预计到 2027 年,中国智能算力规模年度复合增长率达 33.9%。











