如今,研究人员不断把人工智能还有机器学习里新出现的以及成熟的工具,跟化学科学里的成熟办法融合起来,从而打造出强大、高效,有些时候还能自主运行的分子发现、材料工程以及过程优化的平台。
这篇综述把支撑这些技术的基本原理做了总结,还着重讲了最近在自主材料发现、迁移学习以及多保真主动学习里的成功运用。
化学空间,就是把所有可能的分子都列出来,这实际上是没有尽头的。分子量达到约 1000Da 的药物样分子,数量估计在 1013 到 10180 之间。而相比之下,能看到的宇宙里质子数估计才只有 10 个 80 。
这种超大的尺寸对于分子的发现和设计,既有益处也有坏处。好处是能让找到具有所需特性的分子候选物有很大的范围,坏处是在有效地探寻这个空间时存在难题。这种探寻可能会被像分子量、热力学稳定性、可合成性以及毒性这样的实际标准所限制,不过大多数时候,通过实验或者计算进行全面的探寻还是不太现实的。
近些年来,在多功能聚合材料、有机电子学还有合成酶这些方面,软材料和生物材料的发现、设计以及工程化都有了很明显的进步。
这一进步很大程度上是因为把信息学、数据科学还有机器学习的方法给集成并采用了,从而加快并达成了材料的表征、分析、工程以及设计。
促使这一趋势形成的是廉价商品的计算能力能用上,特别是厉害的图形处理单元(GPU)卡以及云计算,让拥有大型训练数据库的领域有了很大的进步。
比如说,现在深度又复杂的图像识别网络能够以超厉害的准确度给图像分类,风格传输网络能把图像变成历史画家的那种风格,生成图像网络能够弄出跟不存在的真人很像的人脸图像,还有生成文本网络能产出(至少在这两位工程师看来!)跟人类诗人差不多的东西。
在硬材料计算工程里,人工智能()跟机器学习的应用,要比在软材料里更成熟、更先进。
硬质材料的结构、性质和行为在很大程度上是固定的,这是能量因素决定的。而软材料呢,构象变形和构型熵对它起着重要作用。
硬材料团队更喜欢用差不多的办法体系,基本是依靠电子结构方法,还花了好多时间和精力去创建、打理大型硬材料属性的数据库,这数据库对团队里的大多数成员都有用。
相较而言,软材料领域往往会在更宽泛的长度范畴里思考材料,从原子一直到肽,再到聚合物,还有细胞与器官,并且运用更大型的理论和计算手段,像分子动力学、蒙特卡罗、有限元计算、晶格玻尔兹曼以及相场建模,时间跨度从皮秒能到数年。
这种方法与系统的多样化是这一领域好看又让人兴奋的一点,不过从某种程度来讲,或许会妨碍规模经济的发展,还有维护那种能充分满足广大用户群需要的大型数据库。
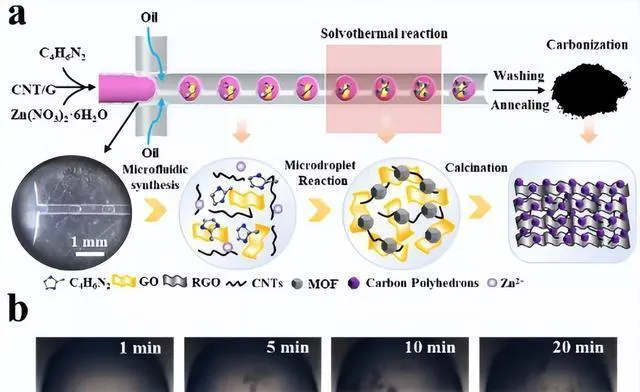
萨顿提到人工智能的「惨痛教训」,说把领域知识和专业知识融入机器学习算法,最终会被更强的计算和用更大数据库训练的更简单算法的应用给取代。让人高兴的是,最近有了少量的软材料数据库和聚合物基因组,不过软材料社区会不会受到刺激,去投资开发这一课程需要的数据库基础设施水平,还得等着看。
在接下来能预见到的日子里,咱们觉得最能赚钱、最能成功的办法就是把领域和数据科学有条理地综合起来。

咱们来瞅瞅机器学习、数据驱动建模还有自主实验(AE)在软材料跟生物材料的发现、设计以及优化方面的应用,最近都有啥新进展。
咱们把支撑这些技术的基本原理给弄明白了,还探讨了它们跟化学、生物分子、机械以及材料工程分支的融合,用来达成或者加快材料或者分子的设计。
最后,咱们瞧瞧这令人兴奋还发展迅速的领域里存在的挑战跟机遇。
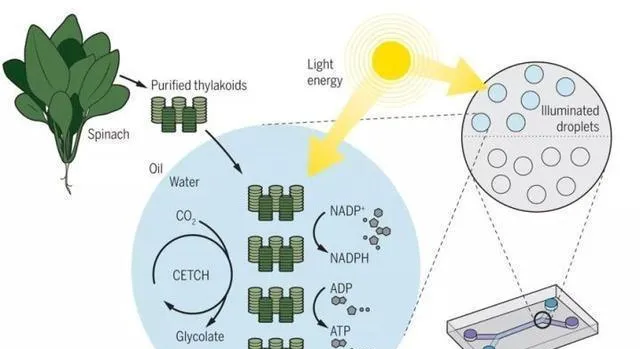
主动学习(也就是顺序学习)策略给出了一个有原则的协议,靠这个协议来引导对化学空间的探索。这些活动的目的,能是把化学空间上模型的不确定性降到最小,也能是找出满足某些性能阈值的分子,或者确认让性能达到最大的条件。从形式上说,实验或者计算是由一些特征在特征空间里定义的。
这些可能是分子的一些性质,像分子量啦或者极化率啥的,不过也能涵盖处理方面的变量,比如说退火温度或者旋涂的速度。
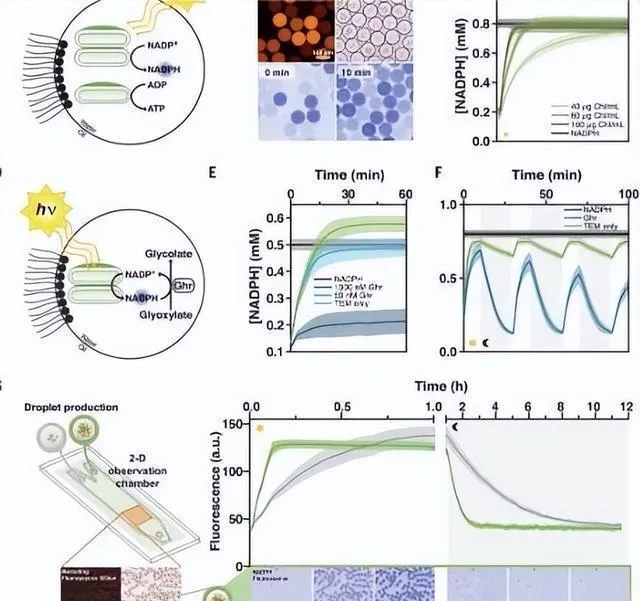
就算用户能提前按照化学直觉、之前的经验或者便利性来指定,数据驱动的工具也能从可能的特性池里做合理的向下选择,或者直接从数据里学习特征。而且,主动学习得包含一个在结果空间里定义的目标属性 y ,这是由实验或者计算产生的。

常见的主动学习框架是贝叶斯全局优化,也就是贝叶斯优化(BO),这是一种最优实验设计,它通过迭代的两步来进行:(a)依据可用数据以及任何现有的知识训练代理模型来做预测;(b2)用获取函数询问这个模型,从而为实验或者计算筛选确定下一个候选者。
模型 f 是靠训练数据去学习的,而且能由任意数量适用于这些数据的回归或者分类模型来确定,像线性回归、支持向量回归、k - 最近邻,还有人工神经网络都可以。
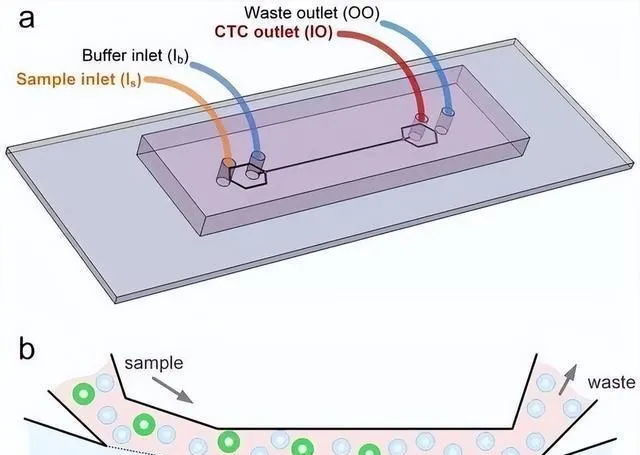
主动学习的热门选择里头,特别合适的是非参数模型,像高斯过程回归。不过呢,模型的选择跟系统的关系很大,GPR 比较适合平滑函数,而基于树的那些方法更适合像相图这种高度不连续的系统。
关键在于,评估代理模型的成本比模拟或者实验低多了,能在每批实验或者模拟的间隔里,在更大的范围进行预测。
业务对象的核心规划要素是采集功能,又叫决策制定政策,这个能把在任意给定位置开展实验的价值给量化了。
采集函数的挑选能让研究者清楚地给活动排个优先级,一般来说,这主要是为了平衡探索参数空间以及利用参数空间里高性能的区域。

比如说,「最大方差」会先看重没探测过区域的采样,而「预期改善」则是去评估在某个位置采样能给出比之前所观察到的最大值还大的值(在最大化任务里)的这种可能性。
一些工作专注在给不同的采购功能和代理模型做基准测试,不过材料系统存在差异,这可能会让得出普遍结论变得困难。
说到底,主动学习形成了一个好的循环:多做些测量能让训练数据增多,从而得出更准确的代理模型,而变好的代理模型能让参数空间的探寻更出色。
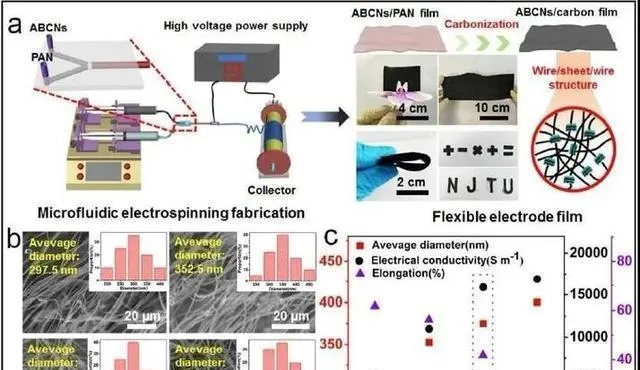
要是代理模型给出的引导比随机或者直觉引导的搜索更好,那么原则上,在主动学习协议里,没必要非得有特别高精度的模型才能实现明显的效率提升。
这些技术啥数量、啥速度的数据都能用,不过呢,最近因为自动化仪器还有计算硬件进步带来了高通量(虚拟)分子筛选技术,所以这些技术就流行起来啦。
在软材料工程这一块儿,BO 指导的高通量实验被用在了发现高玻璃化转变温度聚合物上面。
预期用于治疗二型糖尿病的二肽基肽酶-4拮抗剂的设计,还有控制有效载荷释放的动力学稳定乳液的工程。
预测那些蛋白结合亲和力高的配体,针对冠状病毒疾病 2019(新冠肺炎)的疗法,还有用于分子建模的原子间势的参数化。
在软物质的研究里,好多系统都有着两方面的难题。一是得靠实验明确涌现行为的关键特点,二是在材料构成或者处理的细节上,复杂得很。
虽说好多学科都碰到了这些挑战,可软物质系统通常对细微的处理条件有着特别复杂的依赖,而且在空间跟时间方面存在内在的多尺度表现。
这些挑战让物理实验变成了限制弄懂这类系统的关键所在。
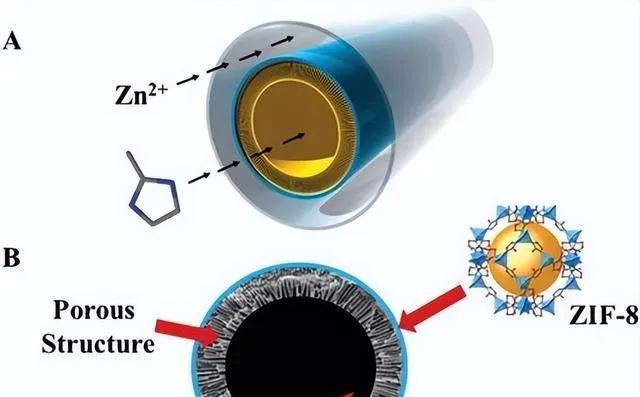
最近有一种能解决实验造成瓶颈问题的系统办法,那就是自主实验(AE),或者说是把机器人技术跟主动学习 AE 相结合。
自动化能让人做实验比手动的更快、更一致,用机器学习来挑实验能让人有系统地利用所有能用的信息,把给定实验给用户定的目标带来有用进展的机会最大化。
换个说法,AE 系统就是主动学习指导实验在物理方面的呈现。
因为 AE 系统到处都有,就有了一些用来形容它的术语,像自动驾驶实验室、机器人科学家,还有人工化学家。
2004 年研发出来的用于研究酵母遗传学的自主系统,被公认为是首个 AE 系统。
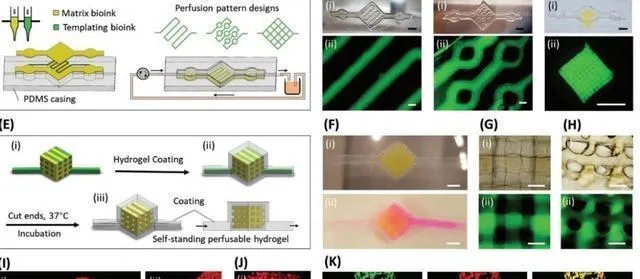
从这次演示开始,声发射系统就拓展到了材料研究、机械方面,还有最近的软材料这块儿事实上。
软材料对 AE 特别适用,好多软物质系统能在解决方案阶段去探究,这样一来,把现有的硬件用到高通量或者自动化实验就比较容易。早期的例子有用于合成水性聚氨酯分散体,还能表征其固体含量和粒度的自动化系。基于流动的化学系统特别适合动态改变反应条件,还能提供在线光学读出。
所以呢,连续流动系统早就被广泛当成自主发现的平台,还跟纳米到皮升级流体样品基于乳液的限制结合起来了,就是为了在没啥先验知识的条件下研究量子点的合成。
通过这种方法找到了 11 种不一样的合成钙钛矿量子点纳米颗粒的配方,这些纳米颗粒有着能够精准调节的发射特性。
参考的文献
【软件与生物材料工程】











