作者:谢帆恺 | 中国科学院大学、中国科学院物理研究所博士生审核:刘淼 | 中国科学院物理研究所研究员
在人工智能领域,Transformer架构、大模型是当下最激动人心的话题之一。它们不仅推动了技术的极限,还重新定义了我们与机器交互的方式。本文将带您从科普的视角了解这些开启智能新篇章的概念。
Transformer模型最初由Google的研究人员在2017年提出,它是一种基于自注意力机制的深度学习模型,用于处理序列数据。在此之前,序列数据处理主要依赖于循环神经网络(RNN)和长短期记忆网络(LSTM),但这些模型在长距离依赖和并行计算方面存在限制。
图片来源:网络
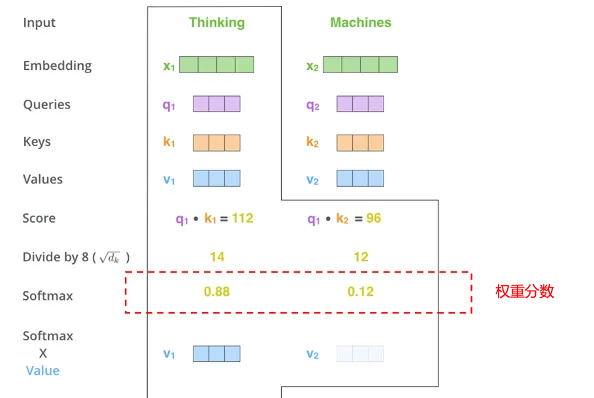
Transformer的自注意力机制允许模型在处理序列的任何元素时,同时考虑序列中的所有其他元素并给出不同元素的重要程度。想象一下,你是一位导演,正在一部舞台剧中指导一群演员。在任何给定的场景中,你都需要决定哪个演员应该成为观众注意的焦点。这时,你会用一束聚光灯照亮你想要突出的演员,而其他演员虽然仍在舞台上,但会处在较暗的背景中。注意力机制在人工智能中的作用就像这个「聚光灯」,它帮助模型确定在处理大量数据时应该「照亮」哪些信息。
在自然语言处理的语境中,比如在阅读一篇文章时,模型需要理解每个单词的意义及其在文中的重要性。不是所有的单词都同等重要,有些单词对于理解句子的意思至关重要,而有些则不那么重要。注意力机制允许模型动态地调整它对不同单词的「聚焦」程度,就像导演控制聚光灯一样,让某些单词在模型的「视野」中更加突出。

图片来源:网络
在具体实现上,每个单词(或数据点)都会被分配一个权重,这个权重代表了它在当前上下文中的重要性。模型通过这些权重来决定在生成输出时应该「照亮」哪些单词。比如从英语翻译到中文,模型会在翻译每个中文词时,重新计算这个分数,以确保聚光灯始终对准最相关的英文词。这种动态调整允许模型即使在面对很长的输入序列时也不会丢失重要信息。这就好比一个翻译员在翻译一句长句子时,她会时不时回头查看原文的某些部分,以确保翻译的准确性和连贯性。
图片来源:网络
通过注意力机制,模型能够更好地处理复杂的模式和长距离的依赖关系,这种能力极大地提高了模型在语言理解、情感分析、语音识别等复杂任务中的表现,并且不断推动着人工智能技术的发展和创新。
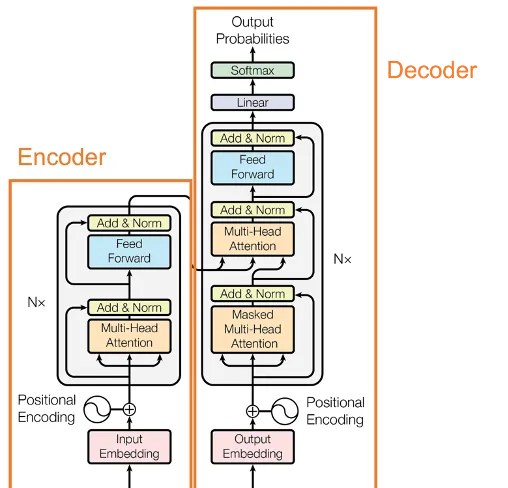
Transformer又可以分为Encoder(编码器)和Decoder(解码器)。其中,Encoder将一段话或者一张图利用注意力机制转换成向量的形式,这个向量包含了这段话或图的所有信息,AI模型便可用这个向量来进行分类或者回归的任务。
图片来源:网络
而Decoder则是根据前面的句子选择概率最高的词输出,直到形成完整的段落。在生成词的过程中,往往会通过采样的方式,赋予模型一定的随机性,因此每次生成的句子都有所不同。
图片来源:网络
目前的大模型主要采用Transformer的Decoder形式,这种架构具有模型复杂度低、上下文理解能力强、语言能力强和预训练效率高等优点。想象你要讲一个故事,作为一个好的故事讲述者,你不仅需要记住你已经说了什么(以保持故事的连贯性),还需要根据已有的情节来创造新的内容。这就像一个Decoder,它需要记住之前的所有内容来生成下一个词。
而Encoder则像是一个倾听者,它专注于理解你的故事,并将它转换成他们心中的一个紧凑的概念或感觉。如果你的目标是创作新的故事内容,那么仅仅做一个好的倾听者是不够的,你还需要能够讲述故事的能力,这正是Decoder所擅长的。
图片来源:网络
大模型的参数量主要是通过对Transformer的Decoder模块进行堆叠而上升的。比如开源大语言模型LLAMA-2就由32个Transformer Decoder进行堆叠,参数量可达几十亿甚至几百亿。OpenAI的GPT-4作为领先全球的大模型,甚至达到了1.76万亿个参数。巨大的参数量使大模型在具备超强的表达能力的同时也消耗着大量的资源,GPT-4在训练过程中,总计使用约3125台机器(25000张A100)进行训练,训练集用到了13万亿个Token(Token可以是一个单词、一个标点符号、一个数字、一个符号等),训练一次的成本需要6300万美元。GPT-4的日耗电达50万度,相当于美国家庭每天用电量的1.7万多倍,能源消耗预计产生了12456至14994吨的二氧化碳排(妥妥的能源巨兽)。由于AI对电力需求飙升,能源赛道同样将迎来新一轮机会。

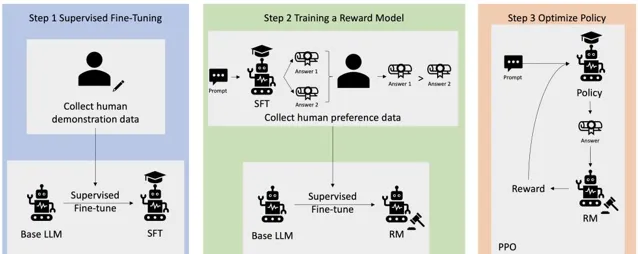
大模型的强大不仅仅得益于它的巨大参数量,更得益于它的训练策略。为了使大模型具有人类决策的倾向性,在初始训练的基础上,加入了基于人类反馈的强化学习(RLHF)。这个过程就像你正在教一个孩子如何玩一个新的电子游戏。你不仅会给他规则上的指导,还会坐在旁边,观察他玩游戏的方式,并在关键时刻给予建议或者示范如何通过难关。基于人类反馈的强化学习在大模型中的应用,就有点像这样一个过程。
在这个比喻中,孩子就像一个强化学习的智能体,而电子游戏就像是它需要学习的任务环境。在传统的强化学习中,智能体通过不断尝试(即「试错」)来学习怎样完成任务,就像孩子自己摸索游戏规则一样。它会根据游戏的得分(奖励)来判断自己的表现。但这个过程可能既低效又费时,因为智能体可能会陷入不必要的错误之中。
RLHF的方法就好比是在孩子旁边加了一个指导者——也就是人类。这个指导者不直接控制游戏,而是通过各种方式给予反馈:
1. 示范:就像大人亲自玩游戏给孩子看一样,人类可以通过执行任务来给智能体示范正确的行为方式。
2. 评价:当孩子完成一次尝试后,大人可以告诉他这样做是好是坏,这就像是人类对智能体尝试的结果给出正面或负面的评价。
3. 指导:在孩子做出选择时,大人可以给出提示或建议,类似地,人类也可以在智能体做决策时给出指导性的建议。
4. 修改奖励:如果孩子完成了一个特别困难的动作或关卡,大人可能会额外奖励他,这就像是人类根据智能体的表现调整奖励函数,以强化某些行为。
通过这些人类的反馈,智能体可以更快地学习到复杂的行为策略,尤其是在那些难以直接编写精确奖励函数的任务中。这种方法特别适用于大模型,因为它们通常需要大量的数据和复杂的行为策略来处理高级任务。
与此同时,大模型仍在不断发展中,然而目前的大模型都是在Transformer的基础上进行开发,AI行业仿佛被困在了六七年前的原型上。不过,AI的发展日新月异,说不定马上就有更好的模型问世于世间。

最后,介绍一个同时让多个大模型为我们「打工」的工具OpenRouter,可以让八十多种大模型同时对同一问题进行回答(赛博养蛊)。
参考文献
[1] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 「Attention Is All You Need.」 arXiv, August 1, 2023. http://arxiv.org/abs/1706.03762.
[2] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. 「GPT-4 Technical Report.」 arXiv, March 4, 2024. http://arxiv.org/abs/2303.08774.
[3] Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, et al. 「Llama 2: Open Foundation and Fine-Tuned Chat Models.」 arXiv, July 19, 2023. http://arxiv.org/abs/2307.09288.

编辑:wnkwef
近期热门文章Top10
↓ 点击标题即可查看 ↓
1.老虎加速朝我跑来的情况下我也对着它冲刺,它会不会愣一下?| No.395
2.龙年吃太饱 | 凭什么大学生和年货不能呆在一个屋子?年货就一点错没有吗?
3.【繁花】中火烧丝光棉真的不怕火烧?
4.人类建筑高度的极限是多少?
5.做饺子馅时要朝同一个方向搅拌吗?为什么?| No.396
6.烟花真的能绽放出爱心形吗?怎么感觉从来没见过(文末领取物理所专属新年红包封面!)
7.尖叫土拨鼠是假的,吃它摸它你就倒霉是真的
8.鼠标里的小球,是什么时候消失的?
9.啄木鸟每天这样duangduang疯狂用头撞树,为啥不会脑震荡?
10.鱼睡觉时会被水冲走吗?沙雕的知识增加了!!
点此查看以往全部热门文章












