01:15
(央视财经【第一时间】)美国开放人工智能研究中心OpenAI,15日发布了首个视频生成模型,该模型可通过接收文本指令,生成相应的视频。
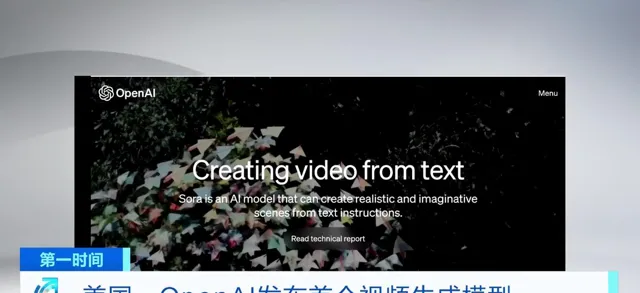
据美国开放人工智能研究中心官网介绍,该公司正在努力让人工智能「理解和模拟处在运动当中的物理世界」。此次发布的文字转视频模型可以依据用户输入的指令,生成一段时长可达1分钟的视频。也能获取现有的静态图像并从中生成视频,还能获取现有视频,进行扩展或填充缺失内容。

据介绍,该模型能够生成包含多个角色以及特定类型运动的复杂场景,并能精确生成物体和背景的细节。目前的模型仍然存在缺陷,例如,它可能难以精确模拟复杂场景的物理状况,也可能无法理解一些特定的因果和时间联系等。此外,模型还可能混淆一些文本指令中的空间细节,例如左右方向等。

相关领域专家将对模型展开测试,目前,该模型只向有限数量的创作者提供访问权限。
转载请注明央视财经
编辑:魏之惠











