Transformer 是一种深度学习模型,由 Ashish Vaswani 等人在 2017 年的论文【Attention Is All You Need】中首次提出。它主要用于处理序列数据,特别是在自然语言处理(NLP)领域取得了巨大成功,例如在机器翻译、文本摘要、问题回答等任务中表现出色。以下是对 Transformer 模型的关键点解释:
1. 自注意力机制(Self-Attention)

2. 多头注意力(Multi-Head Attention)
3. 前馈网络(Feed-Forward Networks)
4. 位置编码(Positional Encoding)
5. 层归一化(Layer Normalization)
6. 残差连接(Residual Connections)
7. 训练和应用
8. 变体和发展
示例代码(使用 PyTorch 和 Hugging Face 的 Transformers 库):
python
import torch from transformers import TransformerModel , BertTokenizer
# 加载预训练的 Transformer 模型和分词器
model = TransformerModel . from_pretrained ( 'bert-base-uncased' )
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-uncased' )
# 准备输入数据
text = "The quick brown fox jumps over the lazy dog" encoded_input = tokenizer ( text , return_tensors = 'pt' )
# 获取模型的输出
output = model ( ** encoded_input )
# 输出的 'last_hidden_state' 包含了序列的最终隐藏状态
hidden_states = output . last_hidden_state
在这个示例中,我们使用了 Hugging Face 的 Transformers 库来加载预训练的 BERT 模型,并对其进行了简单的文本输入处理和前向传播。
Transformer 模型的提出标志着 NLP 领域的一个重要进展,其自注意力机制和多头注意力的设计使得模型能够更好地处理序列数据中的长距离依赖问题。
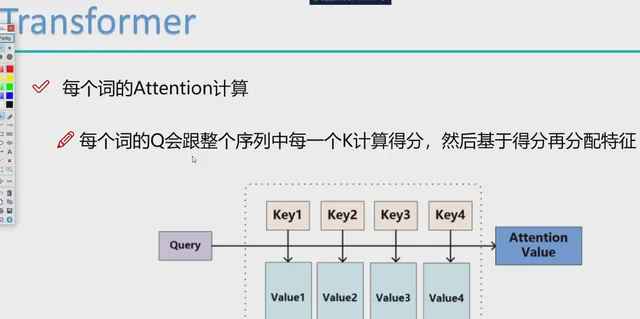
在 Transformer 模型中,"query"(查询)、"key"(键)和 "value"(值)是在自注意力机制中使用的术语,它们是通过以下方式获得的:
- 输入嵌入 :
- 首先,模型接收输入序列(例如,文本句子中的单词或字符),这些输入首先被转换为嵌入表示。这通常涉及到一个可训练的嵌入矩阵,它将输入的离散符号(如单词ID)映射到连续的向量空间。
- 权重矩阵 :
- 输入嵌入随后被分别乘以三个不同的权重矩阵,生成查询(Q)、键(K)和值(V)。
- 这些权重矩阵是模型在训练过程中需要学习的参数。
- 计算注意力得分 :
- 对于序列中的每个元素,模型计算其查询(Q)与所有键(K)的点积,得到一个注意力得分矩阵。这个点积反映了不同元素之间的相似性或相关性。
- 通常,这个得分会通过一个缩放因子(通常是键向量维度的平方根)进行缩放,以防止梯度消失或爆炸。
- Softmax 归一化 :
- 然后,使用 softmax 函数对注意力得分进行归一化,使得每一行的和为1。这样,每个元素的输出都是其对应值(V)的加权和,权重由归一化的注意力得分决定。
- 多头注意力 :
- 在多头注意力中,上述过程被重复多次,但是每个「头」都有自己的权重矩阵。这样,每个头学习到的是输入数据的不同方面或表示。
- 拼接和线性层 :
- 各个头的输出被拼接在一起,并通过另一个线性层进行处理,以产生最终的输出。
-
示例代码(使用 PyTorch):
python
import torch import torch . nn as nn
# 假设输入嵌入的大小为 embedding_size
embedding_size = 256
# 定义权重矩阵
W_q = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
W_k = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
W_v = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
# 假设输入序列的嵌入表示为 embedded_input
embedded_input = torch . randn ( 10 , 32 , embedding_size )
# (序列长度, 批次大小, 嵌入大小) # 计算查询、键和值
Q = torch . matmul ( embedded_input , W_q )
K = torch . matmul ( embedded_input , W_k )
V = torch . matmul ( embedded_input , W_v )
# 计算注意力得分并应用 softmax
attention_scores = torch . matmul ( Q , K . transpose ( - 2 , - 1 )) /
sqrt ( embedding_size )
attention_probs = torch . softmax ( attention_scores , dim =- 1 )
# 计算加权的值
output = torch . matmul ( attention_probs , V )
在这个示例中,我们首先定义了生成查询、键和值的权重矩阵。然后,我们通过矩阵乘法计算了它们,并使用 softmax 函数对注意力得分进行了归一化。最后,我们计算了加权的值,这代表了自注意力层的输出。
在实际的 Transformer 模型实现中,这个过程会更加复杂,包括多头注意力的处理、层归一化、残差连接等。但是,上述示例提供了自注意力机制的基本框架。