2022年底ChatGPT的横空出世,让所有人惊叹于自然语言处理聊天机器人(NLP)的能力,它们能够将简短的文本提示神奇地转换为连贯的类人文本,甚至包括论文、语言翻译和代码示例。科技公司也被 ChatGPT 的潜力深深吸引,纷纷开始探索如何将这项创新技术应用于自身产品和客户体验。
然而,与以往的AI模型相比,GenAI由于其更高的计算复杂度和功耗需求,带来了显著的「成本」提升。那么,GenAI 算法是否适用于对功耗、性能和成本都至关重要的边缘设备应用呢?答案是肯定的,但是不无挑战。
GenAI,下沉到边缘端潜力巨大
GenAI,即生成式人工智能(Generative AI),是一类可以生成各种内容(包括类人文本和图像)的机器学习算法。早期的机器学习算法主要专注于识别图像、语音或文本中的规律,并基于数据进行预测。而 GenAI 算法则更进一步,它们能够感知和学习规律,并通过模拟原始数据集按需生成新的规律。举个例子,早期算法可以预测某一图像中有猫的概率,而GenAI则可以生成猫的图像或详细描述猫的特点。
ChatGPT可能是当下最著名的GenAI算法,但并非唯一,目前已有众多GenAI算法可供使用,并且新算法也在不断涌现。GenAI算法主要分为两大类:文本到文本生成器(又名聊天机器人,如 ChatGPT、GPT-4 和 Llama2)和文本到图像生成模型(如 DALLE-2、Stable Diffusion 和 Midjourney)。图 1展示了这两种模型的示例。由于两种模型的输出类型不同(一种基于文本,另一种基于图像),因此它们对边缘设备资源的需求也存在差异。

图 1:文本到图像生成器 (DALLE-2) 和文本到文本生成器 (ChatGPT) 的 GenAI 输出示例
传统的GenAI应用场景往往需要连接互联网,并访问大型服务器群以进行复杂计算。然而,对于边缘设备应用而言,这并非可行方案。边缘设备需要将数据集和神经处理引擎部署在本地,以满足低延迟、高隐私、安全性和有限网络连接等关键需求。
将GenAI部署于边缘设备,蕴藏着巨大潜力,能够为汽车、相机、智能手机、智能手表、虚拟现实/增强现实 (VR/AR) 和物联网 (IoT) 等领域带来全新机遇和变革。
例如,将GenAI部署到汽车中,由于车辆并不总是受到无线信号覆盖,因此 GenAI 需要利用边缘可用的资源运行。GenAI的应用包括:
- 改善道路救援,并将操作手册转换为AI增强的交互式指南。
- 虚拟语音助手,基于GenAI的语音助手能够理解自然语言指令,帮助驾驶员完成导航、播放音乐、发送信息等操作,同时确保行车安全。
- 个性化座舱:根据驾驶员的喜好和需求,定制车内氛围照明、音乐播放等体验。
其他边缘应用也可能受益于GenAI。通过本地生成图像并减少对云处理的依赖,可以优化AR 边缘设备。另外,语音助手和交互式问答系统也可以应用于很多边缘设备上。
但是GenAI在边缘设备上的应用尚处于起步阶段,要实现大规模部署, 需要突破计算复杂性和模型大小的瓶颈,并解决边缘设备的功耗、面积和性能限制问题。
挑战来了,如何将GenAI部署到边缘侧?
想要理解 GenAI并且将之部署到边缘侧,我们首先需要了解它的架构和运作方式。
GenAI 快速发展的核心是transformers,一种新型的神经网络架构, 是Google Brain团队在2017年的论文中提出的。与传统的递归神经网络 (RNN) 和用于图像、视频或其他二维或三维数据的卷积神经网络 (CNN)相比,transformers在处理自然语言、图像和视频等数据方面展现出了更强大的优势。
Transformers之所以如此出色,关键在于其独特的 注意力机制 。与传统的 AI 模型不同,transformers更加关注输入数据中的关键部分,例如文本中的特定字词或图像中的特定像素。这种能力使transformers能够更准确地理解上下文,从而生成更加逼真和准确的内容。与 RNN 相比, transformers 能够更好地学习文本字符串中单词之间的关系,与 CNN 相比,可以更好地学习和表达图像中的复杂关系。
得益于海量数据的预训练,GenAI 模型展现出强大的能力,使他们能够更好地识别和解读人类语言或其他类型的复杂数据。 数据集越大,模型就越能更好地处理人类语言。
与 CNN 或视觉转换器机器学习模型相比,GenAI 算法的参数(神经网络中用于识别规律和创建新规律的预训练权重或系数)要大几个数量级。如图2所示,用于基准测试的常见 CNN 算法 ResNet50 拥有2500万个参数,而一些 GenAI 模型(如BERT 和 Vision Transformer (ViT) )的参数则高达数亿。
然而也有例外,Mobile ViT 是一种经过优化的 GenAI 模型,其参数数量可以和CNN模型 MobileNet 相媲美,这意味着它可以用于计算资源有限的边缘设备上。
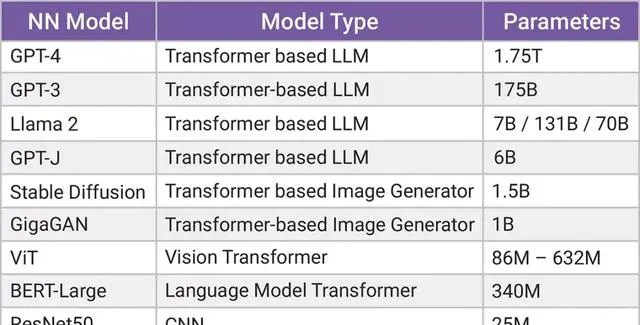
图 2:各种机器学习算法的参数大小
由此可见,GenAI 模型功能虽强大,但也需要庞大的参数数量来支持。鉴于边缘设备的内存有限,嵌入式神经处理单元 (NPU) 怎样才能完成处理如此巨大参数数量的工作?
答案是它们无法完成。
为了解决这一难题,研究人员正在积极探索参数压缩技术,以减少 GenAI 模型的参数数量。例如,Llama-2 提供了700亿个参数的模型版本,甚至更小的 70 亿个参数模型。虽然具有 70 亿个参数的 Llama-2 仍然很大,但已经处于嵌入式 NPU能实现的范围内了。MLCommons 已将 GPT-J(一个具有 60 亿个参数的 GenAI 模型)添加到其 MLPerf 边缘 AI 基准列表中。
选择最快的内存接口很重要
GenAI 算法的强大功能背后,隐藏着对计算资源和内存带宽的巨大需求。如何平衡这两者之间的关系,是决定 GenAI 架构的关键因素。
例如,文生图往往需要更多的计算能力和更高的带宽支持,因为处理二维图像需要大量计算,但参数量相差不大(通常在亿范围内)。大型语言模型的情况较为不平衡,它们需要较少的计算资源,但需要大量的数据传输。即使是较小规模的语言模型(例如6-7亿参数的模型),也受到内存限制的影响。
解决这些问题的有效方法是 选择更快的内存接口。 从图3可以看出,边缘设备通常使用的LPDDR5内存接口带宽为51 Gbps,而HBM2E可以支持高达461 Gbps的带宽。使用 LPDDR 内存接口会自动限制最大数据带宽,这意味着,与服务器应用中使用的 NPU 或 GPU 相比,边缘应用给予 GenAI 算法的带宽将自动减少。我们可以通过增加片上 L2 内存的数量来解决这个问题。

图 3:LPDDR和HBM之间的带宽和功率差异
在ARC® NPX6 NPU IP上实现 GenAI
要针对GenAI等基于Transformer的模型实现高效的NPU设计,就需要复杂的多级内存管理。
新思科技的ARC® NPX6处理器具有灵活的内存架构,可支持可扩展的L2内存,最高可支持64MB的片上SRAM。此外,每个NPX6内核都配备了独立的DMA,专门用于执行获取特征图和系数以及编写新特征图的任务。这种任务区分可以实现高效的流水线数据流,从而最大限度地减少瓶颈并最大化处理吞吐量。该系列在硬件和软件中还具有一系列带宽节省技术,以最大化利用带宽。
Synopsys ARC® NPX6 NPU IP 系列基于第六代神经网络架构,旨在支持包括 CNN 和转换器在内的一系列机器学习模型。NPX6 系列可通过可配置数量的内核进行扩展,每个内核都有自己的独立矩阵乘法引擎、通用张量加速器 (GTA) 和专用直接内存访问 (DMA) 单元,用于简化数据处理。NPX6 可以使用相同的开发工具,将需要性能低于1 TOPS的应用扩展为需要数千TOPS的应用,从而最大限度地提高软件的重复使用。
矩阵乘法引擎、GTA 和 DMA 全都经过优化以支持转换器,使 ARC® NPX6 能够支持 GenAI 算法。每个内核的 GTA 都经过明确设计和优化,可高效执行非线性函数,例如 ReLU、GELU、Sigmoid。这些功能使用灵活的查找表方法加以实现,可预测未来的非线性函数。GTA 还支持其他关键操作,包括转换器所需的 SoftMax 和 L2 标准化。除此之外,每个内核内的矩阵乘法引擎每个循环可以执行 4,096 次乘法。由于 GenAI 基于转换器,因此在 NPX6 处理器上运行 GenAI 没有计算限制。
在嵌入式 GenAI 应用中,ARC NPX6 系列将仅受系统中可用LPDDR的限制。NPX6能够成功运行Stable Diffusion(文本到图像)和 Llama-2 7B(文本到文本)GenAI 算法,而其效率取决于系统带宽和片上SRAM的使用情况。虽然更大的GenAI模型也可以在 NPX6 上运行,但它们会比在服务器上实现的更慢(按照每秒令牌数测量)。
结论
随着行业各界人士不断探索新的算法和优化技术,以及IP厂商的助推,未来,GenAI 将彻底改变我们与设备交互的方式,为我们带来更加智能化、个性化和美好的未来。











