大纲
内容总结
一句话总结
韩迟博士介绍了其在语言模型表征理解方面的研究,特别是通过词向量视角提供方便灵活的控制原模型输出的方法,并展示了其在去毒化任务上的优越性能。
观点与结论
自问自答
- LM-Steer是如何控制语言模型输出的?
- LM-Steer通过对原模型的输出词向量进行线性变换,操纵词向量与原词向量的差异,从而实现对模型输出的控制。
- LM-Steer在去毒化任务上的表现如何?
- 在去毒化任务上,LM-Steer在主要指标上优于之前的操纵方法,特别是在相似大小的原模型上。
- LM-Steer的训练需要多少参数?
- LM-Steer仅需训练最后一层的参数,之前所有层的参数不需要gradient,因此大大减少了内存开销。
- LM-Steer如何处理词向量中的多义性问题?
- LM-Steer通过线性变换W指导语境向量C在特定子空间中寻找词向量,从而处理词向量中的多义性问题。
- LM-Steer的未来研究方向有哪些?
- 未来研究方向包括输入型词向量的特性与作用、模型中间层的隐式表征的利用、非线性变换和操控的研究,以及更好的理论框架来研究原模型。
视频来源
AI TIME 论道:
https://www.bilibili.com/video/BV17mWmeSEss?p=1
讲座回顾

在这个分享活动中,我非常感谢这个平台给予我机会,与大家分享我最近的工作。大家好,我是 韩迟 ,目前是 伊利诺伊大学厄巴纳-香槟分校(UIUC) 的一名四年级博士生,预计两年后毕业。
我在 ACL2024年 提交的一篇论文荣获 杰出论文奖 ,但由于签证原因,我无法参加线下会议,因此未能与许多人见面。这篇论文名为 LM-Steer ,直译为「给语言模型加上一个方向盘」。我们论文的核心观点是理解 词向量 在语言模型中的作用,并提供相应的解释和分析。

然后我们发现,通过这种视角可以提供一种既方便又灵活的控制原模型输出的方法。该模型是与 伊利诺伊大学厄巴纳-香槟分校(UIUC) 及 斯坦福大学 的众多合作者经过愉快合作后的成果,在此也感谢所有合作者。
论文链接、个人联系方式及代码已放置于页面下方。
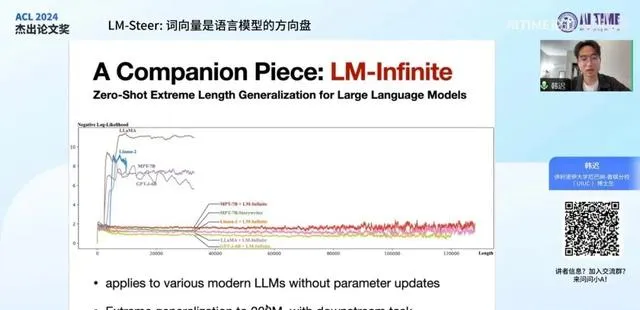
好的,我现在开始。这篇论文有一个姊妹篇,即我在两个月前在 NAACL2024 上发表的另一篇论文,名为 LM-Infinite 。这两篇论文以及我后续主要研究的方向都集中在对语言模型表征的理解上。
LM-Infinite 这篇论文主要研究语言模型中长度表征可能出现的问题。我们发现了几个在过长长度上可能出现的 分布偏移问题 及其根源。为了解决这些分布偏移问题,我们提出了一种对语言模型表示长度的概念化理解,并同时提出了一种简便的方式,即 LM-Infinite ,我们只需改变语言模型计算自注意力分数的方式,而不进行任何微调,就能在零样本情况下将模型延长到非常长的长度。
这种方式可以应用于各种不同的语言模型,无论它们在何种语境下训练得到何种参数,我们都能在各种模型上发现它能在原来会直接导致输出质量下降的问题上得到很好的缓解。我们可以看到,在这个图中,语言模型的损失函数原来在长度一旦超过其预训练长度时会急剧上升,但加入 LM-Infinite 的计算方式后,损失函数可以保持平滑,这代表其输出质量维持在正常水平。
我们可以将这种方式延续到大约 200兆 的长度,同时我们在各种下游任务上也取得了分数的提高。这篇论文也很荣幸获得了 NAACL2024的杰出论文奖 ,与我今天要讲的这篇论文较为相关,因此在此提及。有兴趣的同学可以在 AITIME 之前的另一个活动中了解更多信息。
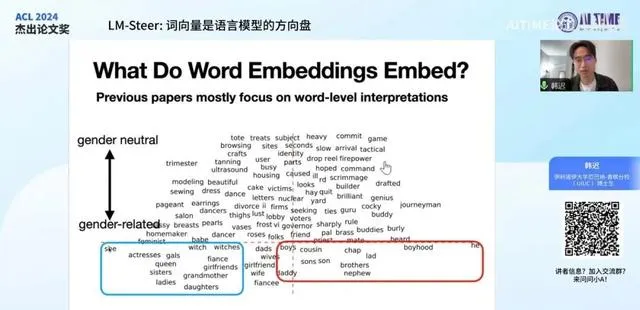
今天我们要讨论的论文主要研究的是 语言模型中词向量所包含的信息 。在之前的研究中,许多论文已经探讨了词向量如何表达词本身的含义,其中一类研究关注的是 类比关系 ,例如 Kings与Queens的关系 。研究发现,在词向量中,Kings与Queens之间的差异与Queens与Queens之间的差异相似。此外,还有研究定义或模拟了词向量中的 矩阵度量空间 ,探讨了不同词之间的距离在词向量空间中的表示方式。
另一类研究则关注于发现词向量中有意义的维度。例如,有研究发现,所有与国家相关的词(如意大利、中国)在某一维度上都有较高的分数,这表明该维度可能与词是否代表一个国家有关。同样,代表人职位的词在另一维度上也有较高的分数。这些发现表明,词向量中存在一些浅显的维度,反映了词的某些基本特征。
另一篇论文采用了不同的方法,将词向量降维到二维平面,并发现许多与性别相关的词在这个平面上展开。例如,左下角聚集了许多关于女性的词,右下角则是关于男性的词。此外,他们还发现了一个性别无关的空间,通过这种方式,他们能够展开二维空间以找到具有特定性质的词,从而消除性别偏见。

还有其他一些研究工作也做了类似的事情,他们发现许多词向量空间中可以找到一些维度,这些维度对应着词本身的词性或语义含义。例如,在这个图中展示了一些 父词 、一些 名字 ,甚至是一些 印度名字 等。此外,还有一些 法语词汇 ,它们在不同的维度中也能找到对应的表征。
我列举这些工作是为了说明,之前的许多研究都关注于 词向量本身 和 单个词之间的关系 ,而我们这篇工作则希望更进一步,探讨这些词向量是否具有某些 功能上的含义 。
在研究中,我们发现许多先前的工作在训练词向量时,与当前语言模型中的方法存在显著差异。早期的工作通常采用特制的训练函数和数据集,旨在学习高质量的词向量。然而,随着大语言模型的发展,人们逐渐不再单独重视词向量的训练,认为其可能缺乏实际意义,因为大语言模型能够忽略这些特殊设计并达到良好的效果。因此,词向量在大语言模型中主要扮演辅助角色。
本页展示了语言模型,特别是 Causal 和 生成式语言模型 的工作方式。每个词,如 X1、X2、X3、X4 ,首先通过 输入型词向量 转换为固定表征,然后这些表征被输入到生成式语言模型中进行处理,生成所谓的 contextual vector 。这些向量不仅包含当前词的信息,还包含之前所有词的信息。例如,第二个向量不仅包含 X2 的信息,还包含 X1 的信息。这些向量随后通过 输出型词向量 进行点积运算,以确定模型生成的下一个词的分布,从而通过采样得到具体的词,如 X2 ,并重复此过程直到输出完成。
在语言模型中, 输入型 和 输出型词向量 并未进行特殊设计,它们完全服务于模型的训练。在许多模型中,输出型和输入型词向量使用相同的参数,但实际上是否使用相同参数影响不大,因为它们在数学上是等价的。如果使用不同的参数,只需对contextual vector进行线性变换即可消除它们在空间上的差异。
我们的研究旨在探讨词向量的 可解释性 ,分析其内部包含的信息。在原模型中,词向量没有特定的训练目标,只有一个统一的训练目标,如生成高质量文本或进行 对齐操作 。对齐操作与生成密切相关,本质上词向量在原模型中并未受到特殊对待。因此,词向量的学习是无意的副产品,但这并不意味着词向量可以随意且不包含任何信息。如果词向量结构复杂或混乱,contextual vector将难以找到相似的词进行输出。
我们进一步研究了 输出型词向量 的工作方式及其作用,即获取下一个词的概率分布。每个contextual vector与输出型词向量进行点积,得到每个词的分数或逻辑值,然后通过指数操作确定每个词的重要性,最终得到一个概率分布,用于采样下一个词。我们对输出型词向量进行了分析,这些分析对后续实验有帮助。例如,点积操作定义了一个相似性指标,即内积空间中的相似性度量。contextual vector的方向指示了寻找最相关词的方向,其长度决定了输出下一个词的概率集中度。
我们使用 隐马尔可夫模型(HMM) 作为理论框架来分析输出型词向量的作用。HMM描述了一个随机过程如何不断生成不同的词,我们的主要理论结论是,HMM中最普遍的输出分布变换等同于输出型词向量上的线性变换。这一结论表明,输出型词向量上的线性变换等同于对语言模型输出分布的调节或操控,即对模型输出句子的控制。这一理论结论连接了单个词概率的操控和整个句子概率的操控,尽管这两者在数学上存在较大差异。我们的发现表明,在某些特殊情况下,输出型词向量的线性变换可以将这两者连接起来。这一线性变换在理论上非常通用,适用于各种语言模型,如 RNN、LSTM和Transformer ,这些模型都以相似的方式使用输出型词向量。因此,我们的理论结论对不同架构都是通用的,这是一个重要的理论性质。
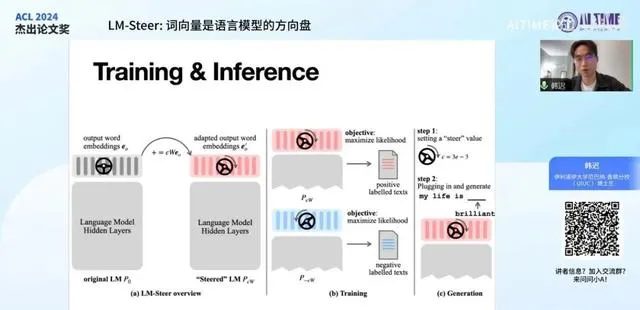
如果我们接受了之前的理论结论,我们就可以提出一种方式去控制原模型的输出,这也就是我们这篇论文中提出的方法—— LM Steer 。具体来说,我们对原模型的输出词向量进行了一个线性变换。与直接进行线性变换不同,我们操纵的是每个词向量与原词向量的差异。也就是说,我们在每个词向量上加上了一个线性变换后的词向量。
大家可以看这个图里面右上角的式子,原词向量可能是e_v,经过我们的操纵后,它变成了e_v加上epsilon W一倍的e_v,即这个式子里的i加上epsilon W,整体乘上e_v。这样定义的好处在于epsilon本身定义了我们这个,就好像一个方向盘的输入量一样,你可以通过方向盘向左打或者向右打,对应的就是epsilon取负值或者正值。当epsilon是负值时,你就在整个空间里面相当于向左改变了词向量的位置。当你把方向盘向右打时,相当于采用一个正的epsilon值,它就相当于向右对词向量进行了变换。在这里,epsilon相当于一个方向盘的输入量或者向方向盘向左打或者向右打的一个尺度。而这个W定义的是我们进行操控的本质是什么,我们WD要在什么样的方向上进行操控,要以什么样的方式进行操控。这个W是一个D乘D的矩阵,其中D是词向量的维度,也就是说它这个矩阵采用不同的值所定义的这种操纵的方式就是不一样的。
在这里epsilon如果取0的话,我们可以看到它就会把模型直接改,就是相当于对模型不做任何操作,它会回到原来的样子,输入词向量会回到原来的值。但是当我们把epsilon取正值或者取负值的时候,我们就相当于在一个维度上,向一个极端或者向另一个极端改变它的输出分布。这个模型的训练也非常的简单,甚至它非常的省空间,它并不是需要很大的GPU,其中一个重要的原因就是我们实际上只是在训练最后一层的参数。然后之前所有层的参数都不需要gradient,都不需要求导,所以这样就省下了很大的内存开销。
这张图里面A这个子图代表的是之前我们说的就是epsilon它的工作方式,B这个子图描绘了这个模型是如何训练的。我们需要正样本或者负样本的文本来定义这个,来告诉我们我们要学到什么样的分布。比如说我们可以把正样本定义为就是思想品德都很优秀的人的语言,然后负样本定为思想品德都非常的下三滥的人所说的话,然后我们把这个样本都位给语言模型,然后其中对于正样本的文本我们把epsilon定为一个正值,比如说0.001然后去找到最能描绘它的W的值,然后也就是去优化这个W,对于负样本我们去把epsilon取为负0.001然后去优化这个W。当然这两个W是共享的,算是同一个W,同一个矩阵值。然后经过这样的训练我们就像用LM-steer去拟合了这么一个分布。当然在这里面其实并不需要正样本和负样本都有,就是如果只有一个也是可以的。
然后C这个子图就是这种模型在训练之后是如何使用的问题了,我们可以把epsilon定为一个任意的值,它可以是0.001,0.002,0.003,或者就可以在这个时数轴上取任何一个值,然后直接把它插入原来的模型,然后就正常的生成就可以了,然后你就可以得到以这个方式操控语言模型之后的。
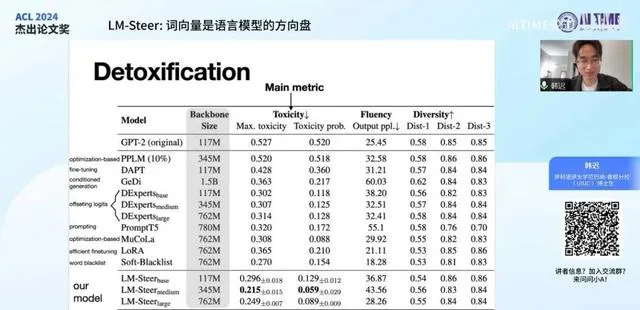
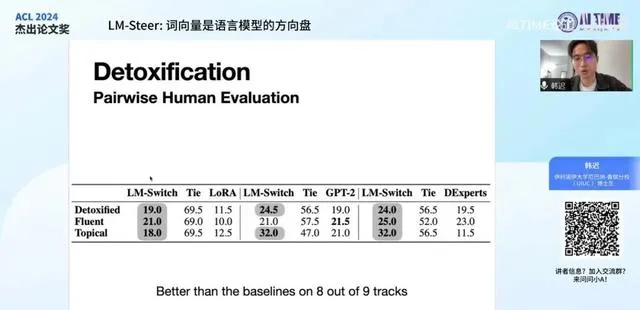
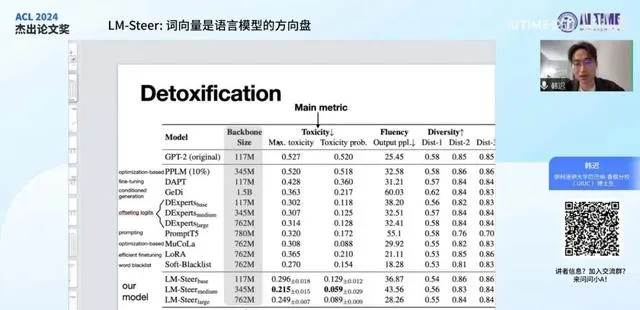
虽然这篇文章的目的并非提出一个具体的方法,但我们还是对原模型进行了操纵实验。我们策划了一个基本且普遍实用的任务,即语言模型的去毒化或无害化。该任务旨在通过提供有害文本作为训练样本,使原模型学会避免产生此类内容。
衡量方式是给模型提供有毒的前置文本,并观察模型是否能不受其影响,继续生成正常内容。我们通过降低toxicity分数来评估模型的表现,发现我们的方法 LM-Steer 在主要指标上优于之前的操纵方法。特别是在对比相似大小的原模型时,这种优势更为明显。
此外,右侧两栏衡量模型输出的质量,我们希望模型输出不仅有质量,而且在 Fluency 上的分数越低越好。
因为刚刚的表格中包含了许多不同大小的模型,这使得比较变得困难。因此,我们绘制了一个图表,以便在不同模型大小下更直观地对比我们与基线方法的效果差异。图表中所有用虚线连接的点代表之前的方法,而所有用实线连接的加号代表我们的方法。这些点之所以被连接起来,是因为它们属于同一个模型家族,例如 Pytheal 或 GPT-2 ,这些家族包含多个不同大小的模型,但彼此相关联。
我们发现,使用 LM-Steer 操控的原模型在相似的模型大小下,表现优于其他模型。特别值得一提的是,我们的模型训练所需的参数非常少,这一点我将在后续的页面中详细说明,它是一种非常精简的控制方法。
我们还进行了一些人类标注研究,以评估我们模型的效果。在此,我需要纠正一个错误,模型名称应为 LM-Steer 。研究中主要测量的尺度包括无害化、输出内容的流畅性以及是否符合当前主题。对比的其他模型包括 LoRA 、 GPT-2 和 DExperts 。其中, LoRA 是一种参数较少的微调方法, GPT-2 是模型原样, DExperts 是一种可控生成方法。
除了原始模型外,其他模型使用的参数都比我们的模型多。然而,我们的模型在九个指标中有八个超过了原始模型,唯一的例外是它在流畅度上并未显著优于未做任何改变的 GPT-2 。这可能是因为任何操作都会对模型的流畅度造成一定影响,因此我们在这一指标上未能超越原始模型,但在其他方面有所牺牲。
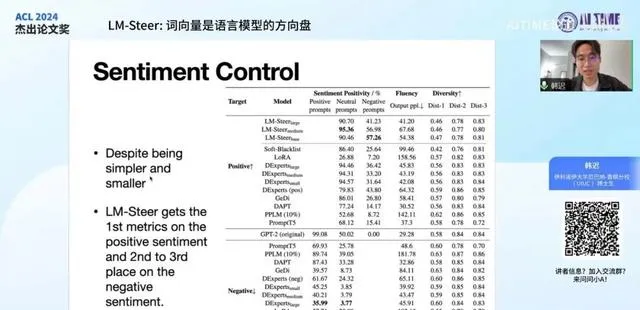
在保持流畅性的前提下,模型在其他各项指标上均取得了较好的效果。针对 情感分析 和 情感控制 任务,我们进行了详细测试。虽然该任务相对简单,许多模型已在此基础上进行了充分比较和优化,达到了较高的分数。
尽管我们的模型设计简单且参数较少,但在四个关键指标中,有两个指标的表现超越了以往的模型,另外两个指标则分别位列第二和第三名。
当然,这个分数并不是我们关注的重点,我们更关注的是模型的一些有趣特性,例如,我们的模型能够轻松实现 连续输出调节 。
在这个图中, 纵坐标 代表 LM-Steer value ,它控制着 epsilon 值的大小。 横坐标 则代表不同的情感,而整个空间坐标代表比例,即每个平面图中的方块所表现的平面都是一个输出分布,展示了模型输出的句子在不同情感上所占的比例。
当我们连续调节 steer value ,即 epsilon 时,可以看到输出逐渐从倾向于负情感平滑过渡到正情感。这些柱状图是实际测得的比例,我们还使用了一些曲线来拟合输出分布,拟合方法是用 beta分布 进行 最大似然估计 ,以更精确和直观地展示分布的渐变过程。

我们还具体进行了一些输出上的采样,以观察 渐变调节 的效果。例如,当调节值从-0.005到+0.005逐渐变化时,输出的句子也会逐渐变化。即使在控制相同随机种子的情况下,句子也会逐渐变得更加文明和有素质。
通过一些显著的指标,如加粗显示的有害词汇和有毒词汇,如「moron」或「stupid」,其程度会变得越来越温和。原本可能使用「这个人是个傻叉」这样的表达,后来则变为「你的国家还不够好」,用词越来越体现高情商。
同时,使用的不良词汇数量也逐渐减少,从原来的两个词减少到一个词组,直至最终使用正向或非负向的词汇。
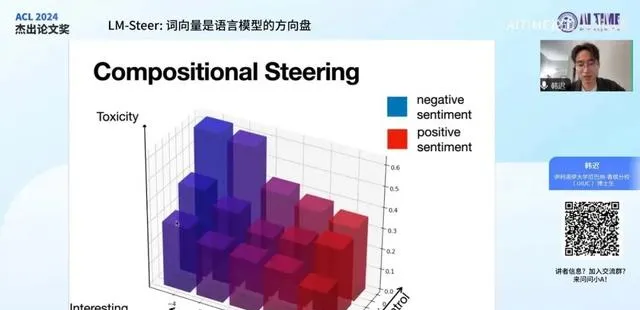
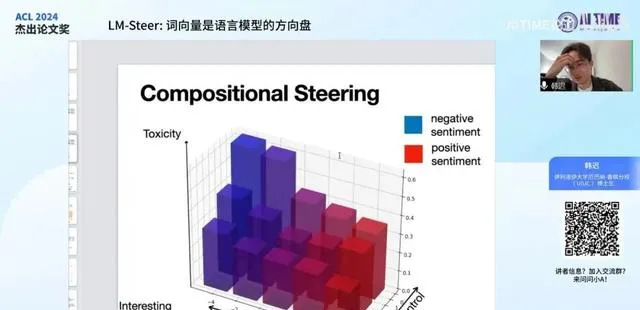
另一个有趣的点在于,我们可以将多个不同的控制方法所控制的 steer方向度 结合起来。例如,我们有一个 LMsteer1号 ,它使用 W1 作为控制矩阵,用 Epsilon1 来代表其控制量。同时,另一个 LMsteer 使用 W2 作为控制矩阵,用 Epsilon2 代表其采用的值。通过将这两个量直接相加,我们可以实现 组合调节 。具体来说,这相当于将原来两个不同的LMsteer所造成的逻辑变化量进行 线性叠加 ,这一过程非常直观。
具体表现在图中,我们实际上进行了两个维度上的调节。其中,这张图表示的是第一个维度,即 语言毒性 的控制。我们从0调整到7,具体的输出毒性分数以 柱状图的高度 表示。我们发现,当采用越来越高的值来压制模型说脏话的倾向时,柱状图的高度会逐渐降低,从后排的高柱子变为前排的低柱子。
另一个维度是 情绪或情感 的控制,图中用 颜色 代表输出的情绪分布,具体情绪是正向还是负向。可以看到,随着我们使用的控制量变得越来越正向,柱子从蓝色变为红色。当我们组合这两个控制量时,可以看到这两个控制实际上或多或少实现了 独立控制 ,即我们可以同时独立控制模型的输出的有害性或无害性与模型输出的情绪的正负极性。
然而,这两个维度并非完全独立,它们之间仍存在一些有趣的关联。例如,当我们逐渐调节输出的情绪,颜色从蓝变到红时,其毒性也会相应降低,这是合理的。当我们让模型说的话越来越温暖、积极时,它也更像一个有素质、有文明的好人,这一点也是符合预期的。
另一个有趣的性质是, LM-Steer 可以在从一个模型向另一个模型转换时,通过显式计算将一个模型上的控制矩阵直接应用到另一个模型上。这一现象利用了之前提到的几个性质。
首先,我们的方法定义了在词向量空间上的双线性度量,即 W定义了C和E之间的相关性 。如果我们有两组不同的词向量,它们来自两个不同的原模型,词向量分别为**E和E' ,其上下文向量可能是 C和C'**。当我们已经计算出第一个原模型上的控制矩阵时,如何将其应用到第二个模型上呢?
我们假设模型的词向量之间存在一定的相关性,这在许多论文中得到了实践验证,即不同模型的词向量大多存在一定程度的线性对应关系。即第一个原模型的词向量矩阵 E可能近似等于另一个模型的词向量矩阵E'乘以变换矩阵H 。我们假设这两个空间相似,即 C和E在同一个向量空间中 ,其上下文向量也应采用同样的方式进行对应, C对应于C'乘以H 。
在第一个原模型上进行的控制量,即我们操纵的改变,是 C转置乘以W乘以E ,我们将这种近似对应关系代入,发现它要达到同样的 logit变化 ,即 概率变化 。在第二个模型上应采用的变化量应为 C'转置乘以H转置乘以W乘以H乘以E'。最后一行的式子表明,中间的三项H转置乘以W乘以H ,实际上起到了在第二个模型中进行操控的作用,即第二个模型中的操控矩阵,我们可以将 H转置乘以W乘以H视为第二个模型中的操控矩阵 。
当我们将其代入时,发现它确实有效,例如,原本只在 GPT-2 large 的尺度上,大约有700兆参数学到了一个 LM-Steer ,学到了一个操控矩阵,然后用这种方式计算,直接应用到另一个模型中的操控矩阵,不进行任何训练。发现在不同模型大小下都可以实现部分无害化效果,例如在各种模型上大约传递了一半的无害化功能。图中上面的曲线代表这些模型原有的毒性,下面的蓝色曲线代表这些模型充分训练后的减毒效果。中间的柱状图代表我们将直接计算出的操控矩阵代入后的效果,发现它大约能达到一半的去毒化效果。
同时,输出的内容也是流畅的,没有破坏模型本身的流畅性,这点比较有意思。我们的模型在计算上也比较经济,我们发现它只需要训练原模型大约0.9%的参数,以 GPT-2 large 为例,它甚至比 LoRA 还要小一个数量级。计算复杂度也没有增加多少,在表格的第二行,我们发现其计算复杂度相对于其他模型来说还是可以接受的。甚至第二行的生成速度甚至可以进一步降低,如果我们假设要进行的控制常数 Epsilon 不变,我们甚至可以直接替换原来的词向量。这样,模型就相当于只是换了一个参数,没有任何额外的计算开销,也会降到和 LoRA 一样的计算速度。其中这个值代表与原模型相比输出速度的比值,1.24代表需要1.24倍的时间,所以这个分数越低越好。
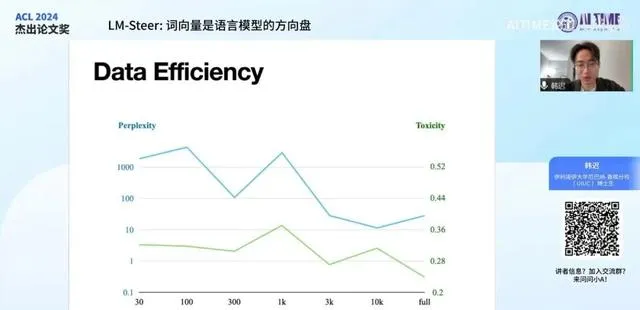
我们的模型实际上只需要很少的参数就可以训练,在这个图中展示了我们用不同大小的数据集进行训练的效果。发现无论是用全量数据集还是较少数据集,去毒化效果都相似。不同的是输出的 perplexity 会逐渐变高,这个值其实也是可以接受的,输出内容还是ok的。我们在其他数据集上进行测试发现它可以做到的效果是,给它两篇新闻文章,一篇文章有某种报道倾向,另一篇文章有另一种报道倾向。这个模型可以只看这两篇文章,然后模仿这两种不同的风格所表达的思想感情。这也是它进行的效果。

我们可以采用我们的方法来标注出一些关键性的词汇。例如,在学会如何使模型无害化之后,我们便能够运用所学的技术,通过模型来识别并标注出每个句子中最具代表性的词汇。
此表格展示了一些这样的实例,包括自动识别出的 种族歧视词汇 和 不当言论 。

要达成这样的效果,所使用的方法如下:我们假设已有一个句子,并希望找到其中最具风格性、与所学功能最相关的词。首先,我们计算原始模型P0中每个词的概率,然后计算经过操控后的模型如何以不同概率输出句子中的每个词。我们的目标是找到那些在原始模型中概率最高,但在操控模型中概率最低的词。这意味着我们要寻找那些包含两种概率分布差异最大的文本段。
具体来说,我们对两种模型进行对数操作,并寻找求和差异最大的子片段。如果你熟悉动态规划,这自然会想到这是一个动态规划问题,我们采用动态规划算法来找到最大求和的子片段。这样,我们就能得到之前表格中的效果。
进一步地,我们发现这种方法也能像之前的工作一样解读词嵌入空间中的不同维度。具体方法是将操控矩阵进行SVD分解,通过SVD分解可以发现一些有趣的现象。例如,这一行展示了LM-Steer对模型的改变量,它对模型的逻辑进行的改变是Epsilon乘以C的转置,乘以W,乘以E。如果我们对W进行SVD分解,就会得到这一行用于这个式子。其中Sigma是一个对角矩阵,我们可以将矩阵中的每一项拆出来,得到像这一行的量。这代表的含义是LM-Steer会寻找词向量中的不同子空间,并根据重要性给予一个分数。也就是说,它实际上是为每个任务寻找一系列子空间,然后看当前的词向量和这些子空间是否对应。再看C向量和另一个子空间是否对应。如果这两者都对应,它就会计算出一个很高的值来改变当前词的概率。只要我们找到V矩阵中不同的行向量,也就是这个小V的转置,这些行向量代表的就是词向量空间中与当前任务相关的维度。

我们进行了 SVD操作 ,并发现这一过程确实提供了一些有价值的解读。例如,我们识别出几个关键空间,并在这些空间中找到了与子维度投影量最大的相关词汇。
其中, 第零维度和第一维度 主要对应 人身攻击 相关的词汇。 第三维度 可能代表 诅咒或骂人 词汇。 第七维度 包含大量与 争吵、辩驳或指控 相关的词汇。而 第八维度 则涉及 政治或政治事件 相关的词汇。
此外,许多维度被省略,因为它们对应的是 非英语词汇 。

所以我进行了适当的删减以提高可读性。至此,今天的分享即将结束。接下来,我想分享一些关于这项工作未来可能的改进方向。
首先,我们的研究主要集中在 输出型词向量 上。对于 输入型词向量 ,由于缺乏充分的理论支持,我们尚未进行深入设计。那么,输入型词向量具有哪些特性?它们的作用是什么?与我们的研究有何关联?这些都是值得探讨的问题。
此外,不仅限于输入型词向量,模型中间层的各种 隐式表征 也包含了大量语义信息。这些信息是否可以用于调整模型输出?已有相关研究涉及这一点,我在此列出。然而,这些研究大多较为粗略,未进行细致分析。我认为,更详细的分析将更为有益。
另一个方向是我们目前仅采用了 线性变换 处理输入型词向量。其他非线性变换和操控同样值得研究。此外,我认为当前缺乏一个完善的理论框架来研究原模型。我不太倾向于使用 隐马尔科夫链(HMM) 。一个更好的理论框架将对分析工作大有裨益。
目前,我的分享就到这里。如果有任何问题,欢迎提出,我将尽力解答。感谢韩迟博士的精彩分享。我们已经汇总了B站和群里的问题,并发送至聊天框。请韩迟博士阅读并解答这些问题。有些问题可能较长,您可以根据自己的节奏逐步回答。好的,我看到了聊天框。谢谢。
首先,关于 LM-Steer如何训练W以达到与人类偏好对齐的效果 ,或者说它是如何找到符合人类偏好的W?例如,是否固定LM参数仅训练W,还是在使用时直接插入已训练好的W?这样的训练数据应如何构建?您认为这种表征工程方式与传统的RLHF方案相比,哪种方式更优?这个问题提得很好。首先,关于其训练方式,我可以回到之前的页面进行展示。请问现在可以看到吗?
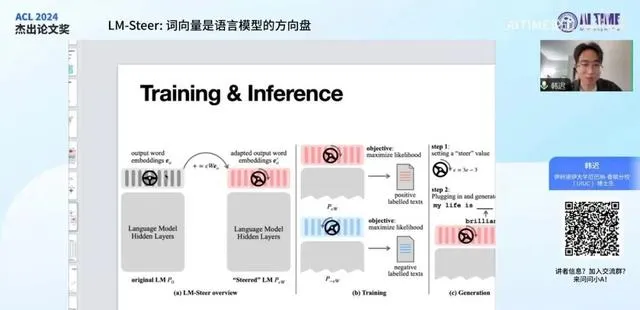
在训练过程中,我们会冻结模型中除 W 以外的所有参数,仅对 W 进行训练。随后,在使用时将训练好的 W 插入模型中。关于训练数据的构建,这是一个值得探讨的问题,实际上任何类型的训练数据都可以使用。例如,目前许多工作会直接提供标记好的正样本和负样本,即 Y win 和 Y lose ,这些可以直接用作训练的正负样本。因此,该方法对训练数据没有特殊要求。
最后一个问题涉及表征工程的对齐方式与传统 RLHF 方法的比较,哪种方式更优。我认为传统的RLHF **方法更优,因为任何涉及训练模型所有参数的方法在经济性和计算效率上都会有所牺牲。如果拥有足够的资金和计算资源,训练所有参数无疑是最佳选择。我们的方法仅涉及非常少量的参数,因此在效果上并非模型的主要卖点,诚实地讲,训练所有参数总是更优的选择。
第二个问题是关于本工作与 DPO 的区别。不考虑训练成本,本工作与 DPO 是两个独立的方向,并不冲突。 DPO 提供了目标函数的选择,而我们的工作则指导应该训练哪些参数。因此,我们的方法可以与 DPO 结合使用,也可以独立使用。关于 DPO 由于数据收集方式可能导致过拟合的问题,我认为所有经济或参数经济的方法都有一定的防止过拟合效果。 DPO 的过拟合问题可能源于其更深层次的原因,因此改进 DPO 或在 DPO 的训练目标上进行研究可能更为本质。同时,也可以结合 LoRA 或 LM-Steer 等方法来减少训练所需的参数量,以获得更好的效果,这些方向都是可以结合的。
第三个问题是关于词向量概率分布与句子分布的壁垒,以及在何种情况下这种壁垒可以被打通。遗憾的是,我在这里没有提供具体的数据表达式。
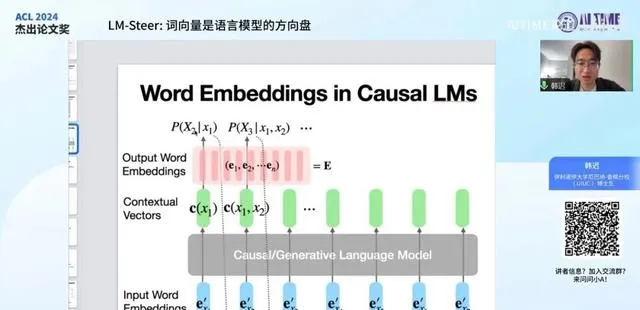
大家应该都清楚,这里每一个P都只决定了当前词的概率。当我们改变P的概率时,不仅改变了当前词的概率,还同时改变了下一个词的输入。当我们改变下一个词的输入时,就会同时改变下一个词的概率。下一个词的概率会传输到更下一个词的输入,然后再传输到更下一个词的概率。
因此,每一个词上概率的改变不仅影响当前的词,还会影响之后所有的词。在我们的模型中,我们会对每一个词都进行这样的操纵。实际上,不同的词的概率改变会与其他所有词的概率改变相互叠加,相互影响。
因此,最终得到的分布是一个非常复杂的问题。我们的分析是基于一定的假设。
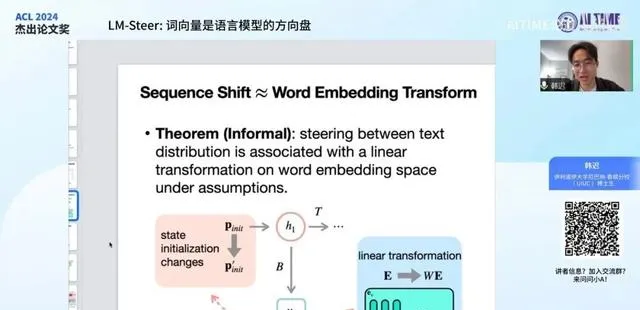
在特殊情况下,该理论框架描述的分布可以等价于输出型词向量的线性变换,因此在这种情况下,壁垒可以被打通。然而,当不满足这些条件时,壁垒的具体情况则超出了隐马尔可夫模型所能研究的范畴。
这也是我最后强调的,我们非常期待能有比隐马尔可夫模型更好的理论框架来研究这些范畴之外的语言模型效果。至于壁垒在其他情况下是否可以被打通,我并不清楚。
下一个问题是关于训练好的W之后,Epsilon大小的调整是否有限,过大的Epsilon是否会导致概率分布畸变。这是一个很好的问题,答案应该是肯定的。
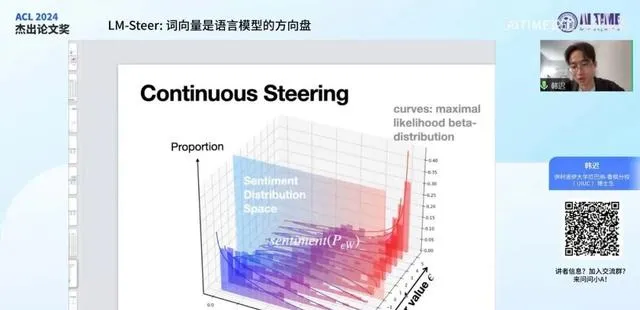
我们目前测试的范围大致为**-5到正5倍 。我们发现, epsilon 在原训练时可能使用的是 -1到正1乘以10的负三次方 。而在输出时,我们使用的是 -5到正5乘以10的负三次方**。至少在这个范围内,其输出效果仍然保持稳定。
在这个表格中,输出的流畅度并不差。当 epsilon值过大时 ,理论上会出现 急剧变化 。具体数值尚未测量,但我们发现 正负五倍范围内 的结果至少是可以接受的。
此外,他还询问了对于 高频语外词 的实验,是否测试过 正常句子的误爆率 ,这也是一个很好的问题。

我们未曾测试过正常的句子,这也是 动态规划算法 的一个特点,即无论何种情况,它都会尝试找到一个具体的词段,即使句子本身并无害处。因此,该算法可能存在 误报率 ,但我们尚未进行具体操作,这只是对该模型性质的一种探索。
关于第五个问题,最初的假设似乎与当前模型的 输出层LM head 不符,后者直接使用最后一层的 hidden state 通过一个 linear层 ,并未如论文中所假设的那样使用hidden state。
Linear层与输入embedding的点乘操作 ,对于这个问题非常有效。Linear层实际上包含一个矩阵,该矩阵将最后一层的hidden state乘以一个矩阵,这个矩阵实际上就是 output word embedding 。尽管有时它被称为Linear Layer,有时被称为output word embedding,但这两个术语在本质上是一样的。这个矩阵在数学上等同于output word embedding,而不是input word embedding。我提到过,即使它们采用相同的值,这两个概念在实际应用中也是有区别的。
第六个问题涉及不同风格的文本生成,例如夸张体或小红书风格。在一定范围内, LM Steer 可以通过控制词的选择来实现这种风格的生成。虽然我没有进行此类实验,但你可以通过收集一些示例文本,可能30到50个,或者一篇文章,然后使用我们的方法进行训练。这种方法不需要大量的语料,这是其优点之一。
第七个问题关于如何区分有害的词,特别是那些在特定语境下才有害的词。我们可以从两个层级回答这个问题。提问者担心的是一个词在不同语境下的不同含义,这正是我们使用 线性变换W 进行操控的原因。W指示C在哪个子空间中寻找特定的词向量。每个词的词向量在不同的子空间中具有不同的特征值,例如「Apple」在水果和公司维度上可能有不同的特征值。理论上,W可以指导C在寻找特定维度时不会影响其他维度。虽然我们没有进行具体实验,但我记得我们发现某些词在某些情况下是有害的,而在其他情况下是无害的,模型能够区分这两种情况。
第八个问题询问作者的动机是从 Linear Representation Hypothesis 来的,还是偶然发现了 LM Output Embedding 的线性性质。实际上,这篇文章的最初动机来自CV领域的一篇文章,该文章发现GAN模型中某些隐藏空间维度可以控制输出图片的特定性质,如大小、角度等。我思考如果文本生成也有类似的性质,语言模型是否也可以进行类似的操控。经过一些探索和实验,我们得到了目前的工作,这实际上是从计算机视觉领域得到的启发。
关于是否可以使用我们的模型解决 gcg jailbreak 的问题,我认为这很困难。jailbreaking涉及复杂的逻辑规则和推演,我们的模型由于其简单性,可能无法胜任这种复杂的问题。解决这个问题可能需要寻找其他模型的参数或机制。
关于画图软件的名字,我使用的是苹果电脑原生的软件 Keynote ,它的风格简单且美观。
第九个问题涉及先进叠加的偏好是否可以直接学习,还是需要先拆解每种偏好并分别收集数据。确实需要先定义这两个维度,因此需要分别收集数据。这两个偏好并不需要正交,实际上在实验中发现它们可能不是正交的。
第十个问题询问与 SAE 的干预有什么区别。SAE是什么,我不太清楚,如果有更多信息,我可以提供更详细的回答。
最后一个问题涉及如何训练W以达到与人类偏好对齐的效果。我们可以固定LM参数只训练W,并在使用时直接插入训练好的W。这种方式与传统的 RLHF方法 相比,效果可能有所不同。如果模型本身能力不足,单纯依靠表征工程可能难以达到好的效果,可能需要类似RLHF的方法来微调模型参数。
但是这也同时导致模型变得更加笨拙,即这些词汇他都不会使用了。这些模型中的词汇可能并不坏,但我非常强硬地告诉他不能使用这些词,因此他一定有所牺牲。所以,如果模型本身不是很好,使用这种方法并不好,他甚至不能直接使用LHF。如果模型本身能力不足,应该继续翻圈或者继续pretrain。所以这两个问题是比较独立的。
还有一个问题提到,数据集构建时筛选出正向复项词的标准是什么?这个方案存在多异性,只在特定语境下表现出正向复项词是如何区分的。我们并不筛选正向复项的词,我们只需要语料,它只要和训练一样,它只需要句子,因此我们并不区分正向复项词。
我们需要的是 文本 ,即 句子 ,然后判断这个句子是好是坏。这与大语言模型本身的训练方式相同,即大语言模型不会强制语言模型使用某个特定的词,而是提供整个句子,告诉它在当前语境下应使用这样的词。
因此,如何区分正向份量的词是由模型自身决定的,模型会根据遇到的不同语境向量选择相应的词。例如,当遇到一个语境向量时,模型会选择具有这些维度的词;而遇到另一个语境向量时,则选择另一个维度的词。
如果一个词具有多义性,如「苹果」既指公司也指水果,那么词向量W应学会引导语境向量C找到特定的维度,而不是将整个词一概而论。这也是词向量本身的作用之一,它具有这样的性质。
关于LM-Steer的理论与 隐马尔可夫模型(HMM) 的关系,它提供了一个理论解释,即告诉我们这个方向是有希望的,并非随意凑合,但与HMM的关系并不大,这也是我不喜欢HMM的原因。如果有更好的理论框架,效果会更好,因为它并不局限于HMM。
如果你们可以看到的话,Dept它的名字叫 Don't Stop Pre-Training ,似乎是这样,总之它是一种 Fine Tuning 的方法。另外, LoRA 也是一种 Fine Tuning 的方法,因此我们确实与 Fine Tuning 的方法进行了对比。
对比结果显示,首先我们确实可以达到更好的效果,并且能够维护,即保证流畅度不会下降得太厉害。同时,我们的方法所需的...
参数量并不大,例如与 DAPT 和 LoRA 相比,我们所需的参数量仅为 LoRA 的十分之一。同时,我们的模型在 解码速度 上也不会有太大牺牲。这就是这几种方法之间的主要区别。
感谢 韩迟博士 的耐心解答,今天似乎没有其他问题了。再次感谢 韩迟博士 ,希望您常来 AITIME 做客。如果有其他小伙伴还有疑问,可以扫描背景上的智能体,与小A联系并留言,我们会与 韩迟博士 私下沟通。
感谢大家的聆听,再次感谢韩迟博士。











