
分享乐趣,传播快乐,
增加见闻,留下美好!
亲爱的您,这里是LearningYard学苑!
今天小编为大家带来的文章
「喆学(25):精读博士论文
【基于概率语言术语集理论的多属性群决策方法及其应用研究】
基于概率语言信息的多属性群决策
模型及应用(1)」。
欢迎您的访问。
Share interest, spread happiness,
increase knowledge, and leave beautiful!
Dear, this is LearningYard Academy!
Today, the editor brings you
" Zhexue (25): Intensive reading of doctoral dissertation
"Multi-attribute group decision-making method
based on probabilistic language term
set theory and its application research"
Multi-attribute group decision-making
based on probabilistic language information
Model and its application (1)"
Welcome to your visit.
本期推文小编将从思维导图、精读内容、知识补充三个方面为大家介绍博士论文【基于概率语言术语集理论的多属性群决策方法及其应用研究】的基于概率语言信息的多属性群决策模型及应用。
In this tweet, I will introduce the multi-attribute group decision-making model based on probabilistic linguistic information and its application of the doctoral dissertation "Multi-attribute group decision-making method based on probabilistic linguistic term set theory and its application research" from the three aspects of the mind map, the content of the intensive reading, and the knowledge supplement.
一、思维导图(Mind Map)
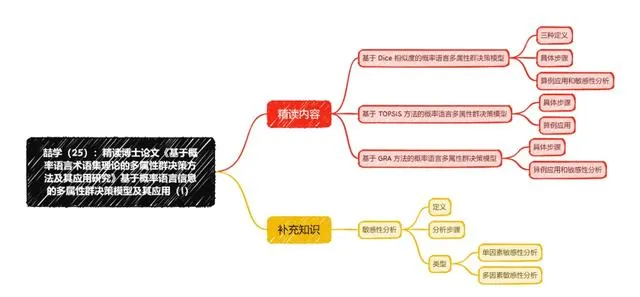
二、精读内容(Intensive reading content)
(1)基于 Dice 相似度的概率语言多属性群决策模型(Probabilistic linguistic multi-attribute group decision-making model based on Dice similarity)
1.三种定义(Three definitions)
文中定义3.1中定义了一个名为L的语言术语集,它包含了-0、-2、-1、0、1等多个元素。这些元素代表了不同的评估或决策结果,并且可以与概率相结合,形成概率语言术语集。
Definition 3.1 in this paper defines a language term set named L, which contains multiple elements such as -0, -2, -1, 0, 1, etc. These elements represent different evaluation or decision results and can be combined with probability to form a probabilistic language term set.
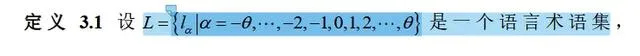
为了计算两个概率语言术语集之间的相似度,文中提出了概率语言Dice相似测度(PLDSM)。该测度基于Dice相似度的传统定义,但进行了适当的修改以适应概率语言术语集的特性。文中列举了PLDSM满足的几个重要性质,包括取值范围在0到1之间、对称性以及当两个概率语言术语集完全相同时取值为1等。
In order to calculate the similarity between two probabilistic language term sets, this paper proposes the probabilistic language Dice similarity measure (PLDSM). This measure is based on the traditional definition of Dice similarity, but is appropriately modified to adapt to the characteristics of probabilistic language term sets. This paper lists several important properties that PLDSM satisfies, including the value range between 0 and 1, symmetry, and the value of 1 when two probabilistic language term sets are exactly the same.

示例3.1中引用了PLDSM的计算公式(公式3.1),该公式考虑了概率语言术语集中每个术语的概率,并通过特定的数学运算来计算两个术语集之间的相似度。根据PLDSM公式,需要分别计算两个术语集中所有对应术语概率的乘积之和,再除以两个术语集长度的函数值。计算出的PLDSM值反映了两个概率语言术语集之间的相似程度,值越接近1表示相似度越高,越接近0表示相似度越低。
Example 3.1 quotes the calculation formula of PLDSM (Formula 3.1), which takes into account the probability of each term in the probabilistic language term set and calculates the similarity between the two term sets through specific mathematical operations. According to the PLDSM formula, it is necessary to calculate the sum of the products of the probabilities of all corresponding terms in the two term sets respectively, and then divide it by the function value of the length of the two term sets. The calculated PLDSM value reflects the similarity between the two probabilistic language term sets. The closer the value is to 1, the higher the similarity is, and the closer it is to 0, the lower the similarity is.

定义3.2中PLDSM是一种用于量化两个概率语言术语集之间相似度的测度。这个测度是用来量化PL1(P)和PL2(P)之间相似度的一个指标。其计算公式较为复杂,但基本思路是通过比较两个集合中对应位置上的术语的概率分布,来计算出它们之间的相似度。
In Definition 3.2, PLDSM is a measure used to quantify the similarity between two probabilistic language term sets. This measure is an indicator used to quantify the similarity between PL1(P) and PL2(P). Its calculation formula is relatively complicated, but the basic idea is to calculate the similarity between them by comparing the probability distribution of terms at corresponding positions in the two sets.

定义3.3的计算涉及到两个概率语言术语集中对应位置上的术语的概率分布,以及一个分辨系数λ(其取值范围为0≤λ≤1)。公式通过求和并归一化处理,最终得到一个介于0和1之间的相似度值,该值越大表示两个概率语言术语集之间的相似度越高。
The calculation of Definition 3.3 involves the probability distribution of terms at corresponding positions in two probabilistic language term sets, and a resolution coefficient λ (whose value range is 0≤λ≤1). The formula is summed and normalized to finally obtain a similarity value between 0 and 1. The larger the value, the higher the similarity between the two probabilistic language term sets.

在实际决策问题中,不同的属性(或元素)往往具有不同的重要性。例如,在多属性决策(MADM)中,各属性的重要性分布可能是不均匀的。文章提出了两种基于概率语言的加权广义Dice相似测度(PLWGDSM),用于量化两个概率语言术语集之间的相似度,并考虑属性权重的影响。这两个测度方法通过计算每个属性值与一个参考点之间的距离(或相似度),并结合各自的权重,来综合评估两个概率语言术语集的相似程度。
In practical decision-making problems, different attributes (or elements) often have different importance. For example, in multiple attribute decision making (MADM), the importance distribution of each attribute may be uneven. This paper proposes two weighted generalized Dice similarity measures (PLWGDSM) based on probabilistic language to quantify the similarity between two probabilistic language term sets and consider the influence of attribute weights. These two measurement methods comprehensively evaluate the similarity between two probabilistic language term sets by calculating the distance (or similarity) between each attribute value and a reference point and combining their respective weights.

2.具体步骤(Specific steps)
根据决策问题的性质,将语言信息矩阵转换为成本型(即成本越低越好)或效益型(即效益越高越好)的决策矩阵。这一步是为了统一不同属性之间的衡量标准。对成本型和效益型决策矩阵进行标准化处理,确保所有属性在同一尺度上进行比较。标准化的目的是消除不同量纲和量级对决策结果的影响。
According to the nature of the decision problem, the language information matrix is converted into a cost-type (i.e., the lower the cost, the better) or benefit-type (i.e., the higher the benefit, the better) decision matrix. This step is to unify the measurement standards between different attributes. The cost-type and benefit-type decision matrices are standardized to ensure that all attributes are compared on the same scale. The purpose of standardization is to eliminate the influence of different dimensions and magnitudes on the decision results.

使用熵权法计算每个属性的重要性权重。熵权法是一种客观赋权方法,它根据各属性的变异程度来确定权重,变异程度越大的属性对决策结果的影响越大。利用计算得到的属性权重,结合概率语言术语集的特点,应用概率语言加权广义Dice相似度测度来计算不同方案之间的相似度或距离。基于PLWGDSM的计算结果,确定一个理想化的方案,该方案在所有属性上均表现最优。将每个待选方案与概率语言正理想方案进行比较,根据相似度或距离的度量结果,选择出最接近正理想方案的方案作为最终决策结果。
The importance weight of each attribute is calculated using the entropy weight method. The entropy weight method is an objective weighting method that determines the weight according to the degree of variation of each attribute. The greater the degree of variation, the greater the impact of the attribute on the decision result. Using the calculated attribute weights and combining the characteristics of the probabilistic language term set, the probabilistic language weighted generalized Dice similarity measure is applied to calculate the similarity or distance between different solutions. Based on the calculation results of PLWGDSM, an idealized solution is determined, which performs best in all attributes. Each candidate solution is compared with the probabilistic language positive ideal solution, and the solution closest to the positive ideal solution is selected as the final decision result based on the measurement results of similarity or distance.



3.算例应用和敏感性分析(Example Application and Sensitivity Analysis)
通过成都市某农业食品公司采购大豆油的绿色供应商选择过程,展示了GSCM在实际应用中的操作。该公司通过初步筛选后,仍有5家候选供应商需要进一步评估。为此,公司邀请了4位专家从服务水平、产品价格、产品质量和环境管理四个方面对候选供应商进行评价分析。其中,产品价格被视为成本型指标,即越低越好,而其他三个指标为效益型指标,即越高越好。最后按照上述步骤,选出A3为最佳方案。
The operation of GSCM in practical application is demonstrated through the green supplier selection process of a Chengdu agricultural food company purchasing soybean oil. After the company passed the initial screening, there were still 5 candidate suppliers that needed further evaluation. To this end, the company invited 4 experts to evaluate and analyze the candidate suppliers from four aspects: service level, product price, product quality and environmental management. Among them, product price is regarded as a cost-type indicator, that is, the lower the better, while the other three indicators are benefit-type indicators, that is, the higher the better. Finally, according to the above steps, A3 is selected as the best solution.
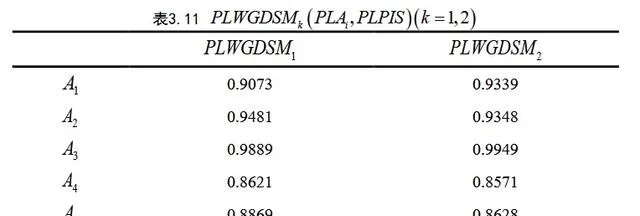
最后是率语言信息的多属性群决策中分辨系数的灵敏度分析,指出随着分辨系数的变化,方案排序结果显著不同,并反映了决策者的风险偏好。决策者可根据自身对风险的态度选择适当的分辨系数值以确保决策的科学性和合理性。
Finally, there is a sensitivity analysis of the resolution coefficient in multi-attribute group decision-making based on linguistic information. It is pointed out that as the resolution coefficient changes, the solution ranking results are significantly different and reflect the risk preference of the decision-maker. Decision makers can choose appropriate resolution coefficient values based on their own attitudes toward risks to ensure the scientificity and rationality of their decisions.

(2)基于 TOPSIS 方法的概率语言多属性群决策模型(Probabilistic linguistic multi-attribute group decision-making model based on TOPSIS method)
1.具体步骤(Specific steps)
首先,将语言信息矩阵转换为概率语言决策矩阵。接着,为了消除不同属性量纲和量级的影响,需要对概率语言决策矩阵进行标准化处理,得到标准化的概率语言决策矩阵。
First, the language information matrix is converted into a probabilistic language decision matrix. Then, in order to eliminate the influence of different attribute dimensions and magnitudes, the probabilistic language decision matrix needs to be standardized to obtain a standardized probabilistic language decision matrix.

使用熵权法(或其他合适的权重计算方法)来计算各个属性的权重,这些权重反映了属性在决策过程中的重要程度。
Use the entropy weight method (or other appropriate weight calculation methods) to calculate the weights of each attribute, which reflects the importance of the attribute in the decision-making process.

基于标准化的概率语言决策矩阵和属性权重,确定概率语言正理想方案和负理想方案。正理想方案是所有属性都达到最优(或最符合决策者期望)的方案,而负理想方案则是所有属性都最差(或最不符合决策者期望)的方案。
Based on the standardized probabilistic language decision matrix and attribute weights, the probabilistic language positive ideal solution and negative ideal solution are determined. The positive ideal solution is the solution where all attributes are optimal (or most in line with the decision maker's expectations), while the negative ideal solution is the solution where all attributes are the worst (or least in line with the decision maker's expectations).

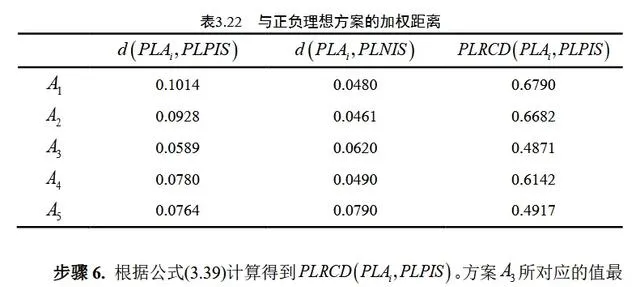
利用海明距离(或其他合适的距离度量方法)计算每个方案与正理想方案和负理想方案之间的距离,并考虑属性权重进行加权处理。接着,基于加权正理想距离和加权负理想距离,计算每个方案与正理想方案的相对接近度(PLRCD),该值反映了方案与最优解的接近程度。最后,根据概率语言相对接近度(PLRCD)的值对方案进行排序,选择PLRCD值最大的方案作为最优方案。
The distance between each solution and the positive ideal solution and the negative ideal solution is calculated using the Hamming distance (or other appropriate distance measurement method), and the attribute weight is considered for weighted processing. Then, based on the weighted positive ideal distance and the weighted negative ideal distance, the relative closeness (PLRCD) of each solution to the positive ideal solution is calculated. This value reflects the closeness of the solution to the optimal solution. Finally, the solutions are sorted according to the value of the probabilistic linguistic relative closeness (PLRCD), and the solution with the largest PLRCD value is selected as the optimal solution.


2.算例应用(Application examples)
四川省某市消防救援局近期对当地部分高层住宅小区进行了详细调查,通过实地考察、访谈等方式收集数据,并邀请专家从消防设施状态、住户自救能力、与消防站距离、安全通道情况四个方面进行评估,以推动消防安全工作的持续改进。根据上述的步骤最后得出A3为最优方案
The Fire Rescue Bureau of a city in Sichuan Province recently conducted a detailed investigation of some local high-rise residential areas, collected data through field visits and interviews, and invited experts to evaluate the status of firefighting facilities, residents' self-rescue capabilities, distance from fire stations, and safe passages in order to promote continuous improvement of fire safety work. According to the above steps, A3 is finally concluded as the best solution.
(3)基于 GRA 方法的概率语言多属性群决策模型(Probabilistic linguistic multi-attribute group decision-making model based on GRA method)
1.具体步骤(Specific steps)
首先,成本型的属性值转化为其相应的效益型的属性值。接着,将语言信息矩阵转换为概率语言决策矩阵。
First, the cost-type attribute values are converted into their corresponding benefit-type attribute values. Then, the language information matrix is converted into a probabilistic language decision matrix.

对处理后的数据进行标准化,得到标准化的概率语言决策矩阵,以便进行后续的比较和分析。使用CRITIC方法计算各属性的权重,这种方法考虑了属性间的相关性。
The processed data is standardized to obtain a standardized probabilistic language decision matrix for subsequent comparison and analysis. The weight of each attribute is calculated using the CRITIC method, which takes into account the correlation between attributes.

基于标准化的概率语言决策矩阵和属性权重,构建两个决策矩阵:一个用于计算「正向灰色关联系数和」,另一个用于计算「负向灰色关联系数」。这两个矩阵反映了各方案与正理想方案和负理想方案的接近程度。计算每个方案与正理想方案的整体正向灰色关联系数和,以及与负理想方案的整体负向灰色关联系数。
Based on the standardized probabilistic language decision matrix and attribute weights, two decision matrices are constructed: one is used to calculate the "positive grey correlation coefficient sum", and the other is used to calculate the "negative grey correlation coefficient". These two matrices reflect the degree of proximity of each scheme to the positive ideal scheme and the negative ideal scheme. The overall positive grey correlation coefficient sum of each scheme with the positive ideal scheme, and the overall negative grey correlation coefficient with the negative ideal scheme are calculated.

利用这些数值,进一步计算每个方案的概率语言相对关联度(PLRCD),这是一个综合指标,用于衡量方案与最优解的接近程度。根据概率语言相对关联度(PLRCD)的值,对所有方案进行排序,选择PLRCD值最大的方案作为最优方案。
Using these values, we further calculate the probability linguistic relative correlation degree (PLRCD) of each solution, which is a comprehensive indicator used to measure the closeness of the solution to the optimal solution. According to the value of the probability linguistic relative correlation degree (PLRCD), all solutions are sorted and the solution with the largest PLRCD value is selected as the optimal solution.

2. 算例应用和敏感性分析(Example Application and Sensitivity Analysis)
文章简述了四川省某市计划建设电动汽车充电站,并通过专家从废气排放、工程造价等四维度,采用基于概率语言信息的多属性群决策模型,评估五个候选位置,以选出最佳建设地点。按照上述步骤,最后得出A2为最佳方案。
The article briefly describes the plan to build an electric vehicle charging station in a city in Sichuan Province, and uses a multi-attribute group decision-making model based on probabilistic language information to evaluate five candidate locations from four dimensions, such as exhaust emissions and project cost, to select the best construction site. According to the above steps, A2 is finally concluded as the best solution.
文中通过改变分辨系数的值,观察各个方案排序值的变化情况,从而进行敏感性分析。分辨系数在灰色关联分析中是一个重要的参数,它用于调节不同指标间差异的敏感性。通过改变分辨系数,可以检验决策结果是否稳定,即是否容易受到参数变化的影响。文中最后提到验证了PL-GRA方法处理MAGDM问题的稳定性和平稳性。这意味着通过敏感性分析,证明了PL-GRA方法在处理此类多属性群决策问题时,能够得出稳定且可靠的决策结果,即使面对不同的参数设置或条件变化。
In this paper, by changing the value of the resolution coefficient and observing the changes in the ranking values of each scheme, a sensitivity analysis is performed. The resolution coefficient is an important parameter in grey relational analysis, which is used to adjust the sensitivity of the differences between different indicators. By changing the resolution coefficient, it is possible to test whether the decision result is stable, that is, whether it is easily affected by parameter changes. At the end of the paper, it is mentioned that the stability and stability of the PL-GRA method in dealing with MAGDM problems have been verified. This means that through sensitivity analysis, it is proved that the PL-GRA method can produce stable and reliable decision results when dealing with such multi-attribute group decision-making problems, even in the face of different parameter settings or condition changes.
三、知识补充(Knowledge Supplementation)
敏感性分析是指从定量分析的角度,研究有关因素发生某种变化对某一个或一组关键指标影响程度的一种不确定分析技术。其实质是通过逐一改变相关变量数值的方法来解释关键指标受这些因素变动影响大小的规律。
Sensitivity analysis is an uncertainty analysis technique that studies the impact of a certain change in related factors on a certain or a group of key indicators from a quantitative analysis perspective. Its essence is to explain the law of the impact of these factors on key indicators by changing the values of related variables one by one.
(1)分析步骤(Analysis steps)
1.敏感性分析指标:敏感性分析的对象是具体的技术方案及其反映的经济效益。因此,技术方案的某些经济效益评价指标(如息税前利润、投资回收期、投资收益率、净现值、内部收益率等)都可以作为敏感性分析指标。
1. Sensitivity analysis indicators: The object of sensitivity analysis is the specific technical solution and the economic benefits it reflects. Therefore, some economic benefit evaluation indicators of the technical solution (such as profit before interest and taxes, payback period, investment return rate, net present value, internal rate of return, etc.) can be used as sensitivity analysis indicators.
2.技术方案的目标值:一般将在正常状态下的经济效益评价指标数值作为目标值。
确定不确定性因素可能的变动范围:这是进行敏感性分析的基础,需要基于历史数据、市场预测等信息来确定。
2. Target value of the technical solution: Generally, the value of the economic benefit evaluation indicator under normal conditions is used as the target value.
Determine the possible range of changes in uncertainty factors: This is the basis for sensitivity analysis and needs to be determined based on historical data, market forecasts and other information.
3.不确定性因素变动时评价指标的相应变动值:通过模拟不同情境下不确定性因素的变动,计算其对评价指标的影响。
3. The corresponding change value of the evaluation indicator when the uncertainty factor changes: By simulating the changes of uncertainty factors in different scenarios, calculate their impact on the evaluation indicators.
4.敏感性因素及其影响程度:根据计算结果,找出对项目经济效益影响最大的敏感性因素,并分析其影响程度和敏感性程度。
4. Sensitivity factors and their impact: According to the calculation results, find out the sensitivity factors that have the greatest impact on the economic benefits of the project, and analyze their impact and sensitivity.
5.项目承受风险能力:基于敏感性分析的结果,评估项目在面临不确定性因素变动时的承受风险能力。
5. Project risk tolerance: Based on the results of sensitivity analysis, evaluate the risk tolerance of the project when facing changes in uncertainty factors.
(2)类型(Types)
单因素敏感性分析为次只变动一个因素而其他因素保持不变时所做的敏感性分析。这种方法简单易行,但忽略了各因素之间的相互影响。多因素敏感性分析为多个因素的变动对评价指标的影响。这种方法更接近实际情况,但计算复杂度较高。
Single factor sensitivity analysis is a sensitivity analysis performed when only one factor is changed while other factors remain unchanged. This method is simple and easy to implement, but it ignores the mutual influence between factors. Multi-factor sensitivity analysis is the impact of changes in multiple factors on the evaluation index. This method is closer to the actual situation, but the calculation complexity is higher.
今天的分享就到这里了。
如果您对文章有独特的想法,
欢迎给我们留言,
让我们相约明天。
祝您今天过得开心快乐!
That's all for today's sharing.
If you have a unique idea about the article,
please leave us a message,
and let us meet tomorrow.
I wish you a nice day!
翻译:AI翻译
参考资料:百度、文心一言
参考文献:卫村. 基于概率语言术语集理论的多属性群决策方法及其应用研究 [D]. 西南财经大学, 2023.
本文由LearningYard学苑整理发出,如有侵权请在后台留言!
文案|hzy
排版|hzy
审核|yyz











