目錄
一、GBase 8s分片表的優勢
二、六種分片方法
輪轉
1.輪轉法
基於運算式分片
2.基本運算式
3.Mod運算運算式
4.Remainder關鍵字方式
5.List方式
6.interval 固定間隔
三、分片表的索引
1.建立索引的註意事項
2.detach索引替代delete功能展現
3.在現有分片表上增加一個新的分片
四、dbspace資料庫空間
1.增加dbspaces空間
2.檢視空間大小
3.檢視空間剩余大小
GBase 8s 的分片是用來處理數據量非常大的表和索引的技術。分片可以用將大表拆分為小表的方式進行管理,提高了GBase 8s的大數據處理效能。同時對外提供的是同一個表的管理方式,這樣對於使用資料庫的存取者而言非常透明。
1、分片是指把一個表的數據分散到多個dbspace中儲存。
2、在邏輯上對外提供一個表的存取介面。
3、在資料庫內部,物理上把大表拆分為多個小表進行管理。
一、GBase 8s分片表的優勢
概括一下,GBase 8s分片表的優勢體現在以下三點:
(1) 有效處理大數據表。
有效利用並行執行,分片表可以啟動PDQ,開啟多執行緒並列處理,可以充分利用多 CPU、多磁盤的物理資源,大大提高大數據表的存取速度。利用分片忽略,可減少需要存取的表空間。利用分片表將大表拆分存放的特性,相當於以存取小表的效率進行存取,如某分片方式將每年儲存在一個分片上,那麽查詢某一時間點的數據時,只需要掃描分片表的一個分片即可,可以有效地處理大數據量的表。實作僅僅對包含「目標數據」的數據分片進行掃描。從而大振幅地提高了整個系統效率。
(2) 分片容易管理--表組合/表分離(attach/detach)。
可以利用GBase 8s對分片表提供的attach和detach功能對分片表進行快速、高效的管理。例如detach可以對表的某一個分片進行快速分離,我們可以利用該功能對歷史數據進行快速刪除,可以替代delete方式。
(3) 有效地提高可用性。
當表的某個分片出現故障時,表的其他分片的數據仍然可用,同時只需要修復該分片即可。當我們需要對表進行重建時,我們可以對分片表利用attach/detach按分片一個個地完成重建,從而提高表的可用性,滿足7x24執行模式的要求。
下面我們來看GBase分片的具體實作。
二、六種分片方法
GBase的六種分片方式可以大致劃分為兩類:一類是輪轉法分片,第二類是基於運算式的方式。
輪轉法:
1.輪轉法
「輪轉法分片」這個存放方法采用輪詢排程,依次在dbspaces上儲存資料庫。特點為:
簡單,不需要了解數據的分布 ;
把數據均勻地分配到所有分片中 ;
提高查詢效能 ;
只能用於表,不能用於索引 ;
不能利用到忽略分片的特性,沒有成功減少對磁盤的掃描;
可配合PDQ啟用多執行緒並列掃描以提高查詢效能。
create table tab_round_robin
(
id int,
name varchar(40),
nation varchar(40),
regtime datetime year to second default current year to second not null
) fragment by round robin
in datadbs1,datadbs2,datadbs3,datadbs4;
顯示的指定索引
create index ix_tab_round_robin_id on tab_round_robin(id) in datadbs1;
基於運算式分片:
「基於運算式分片」則根據表中的一個或多個欄位對分片的規則進行定義,一般在預知查詢條件時采用這種方式,從而避免查詢中對某些分片的掃描。其特點為:
需要對數據分布有所了解 ;
為分片忽略和效能提升提供可能 ;
既可以用於表也可以用於索引 ;
可以基於一列或者多列構建運算式。
基於運算式包括多種具體的形式,下面將介紹5種形式:
2.基本運算式
#當不指定partition時,sql語句如下:
create table tab_expression_based
(
id int,
name varchar(40),
nation varchar(40),
regtime datetime year to second default current year to second not null
) fragment by expression
id < 100 in datadbs1,
id < 200 in datadbs2,
id < 300 in datadbs3;
#加入指定partition,sql語句如下,這對於查詢可以更好的提高效率。
#partition指定的情況下可以對於不同的p0、p1、p2都放在同一個datadbs1空間中
create table tab_expression_based
(
id int,
name varchar(40),
nation varchar(40),
regtime datetime year to second default current year to second not null
) fragment by expression
PARTITION p0 id < 100 in datadbs1,
PARTITION p1 id < 200 in datadbs2,
PARTITION p2 id < 300 in datadbs3;
3.Mod運算運算式
加入取余運算的基本運算式。
create table employee
(
id int,
name char(50),
salary int
)fragment by expression
MOD(id,3) = 0 IN datadbs1,
MOD(id,3) = 1 IN datadbs2,
MOD(id,3) = 2 IN datadbs3;
create index idx_employee on employee(id);
4.Remainder關鍵字方式
利用remainder關鍵字將難以表達的範圍數據指定到一個分片中。
create table table_test
(
col1 int,
col2 date
)fragment by expression
col1 >= 0 and col1 < 100 in datadbs1,
col1 >= 100 and col1 < 200 in datadbs2,
remainder in datadbs3;
create index idx_table_test on table_test(col1);
5.List方式
List方式本質上是對or和in運算的改進,使運算式計算更有靈活性,效率更高。
create table customer
(
id int,
name varchar(128),
street varchar(255),
state char(2),
zipcode char(5),
phone char(15)
)fragment by list(state)
PARTITION p0 values('RS','IL') in datadbs1,
PARTITION p1 values('CA','OR') in datadbs2,
PARTITION p2 values('NY','MN') in datadbs3,
PARTITION p3 values(NULL) in datadbs4;
insert into customer values(1,'suyi','xiqing','RS','12345','12211231223');
insert into customer values(2,'suer','xiqing','IL','12345','13333333333');
insert into customer values(3,'susan','xiqing','OR','12345','14444444444');
insert into customer values(4,'susi','xiqing','CA','12345','15555555555');
insert into customer values(5,'suwu','xiqing','NY','12345','16666666666');
insert into customer values(6,'suliu','xiqing','MN','12345','17777777777');
insert into customer values(7,'suqi','xiqing','','12345','1888888888');
insert into customer values(8,'suba','xiqing','RS','12345','19999999999');
#檢視分片的具體資訊
select t.tabname,f.dbspace,f.partition,f.exprtext
from systables t,sysfragments f
where t.tabid = f.tabid and f.fragtype = 'T'
and t.tabname = 'customer';
#查詢結果如下
tabname customer
dbspace
partition
exprtext
state
tabname customer
dbspace datadbs1
partition p0
exprtext
VALUES ('RS' ,'IL' )
tabname customer
dbspace datadbs2
partition p1
exprtext
VALUES ('CA' ,'OR' )
tabname customer
dbspace datadbs3
partition p2
exprtext
VALUES ('NY' ,'MN' )
tabname customer
dbspace datadbs4
partition p3
exprtext
VALUES (NULL)
5 row(s) retrieved.
透過update語句確認我們的分片表結構,成功按照list方式進行分片。
update customer set state = '' where id = 1;
執行上述update語句後,當前記錄會從當前分片中刪除並且在新的分片裏面插入,透過邏輯日誌展示,可以證明我們的想法。

update customer set state = 'OR' where id = 4;
再來嘗試上面這條update語句,我們知道當前記錄對應的條件沒有發生變化,仍在原來分區,只是state的值進行更新,所以猜想應該只是更新記錄。透過檢視邏輯日誌,證明我們的猜想正確。

6.interval 固定間隔
最初的分片是基於一個range語句來定義的。
優點:GBase 8s提供的基於interval的分片策略,將根據Insert記錄的情況自動擴充套件分片,可提供更為靈活的方式,減少人工維護。
create table sales
(
amount int,
id int,
data_time datetime year to second
)fragment by range(data_time)
interval (10 units day)
store in (datadbs1,datadbs2,datadbs3,datadbs4)
partition p_sales0 values < '2023-01-01 00:00:00' in dbspace;
create unique index idx_sales on sales(data_time,id);
三、分片表的索引
GBase 8s的索引分為attached和detached的兩種索引。
兩種索引的區別在於:attached索引指每個分片的數據都有相應的索引獨立存在;detached索引指的是索引與分片數據儲存在不同的dbspace上。
我們先簡單的建立兩種索引,了解一下。
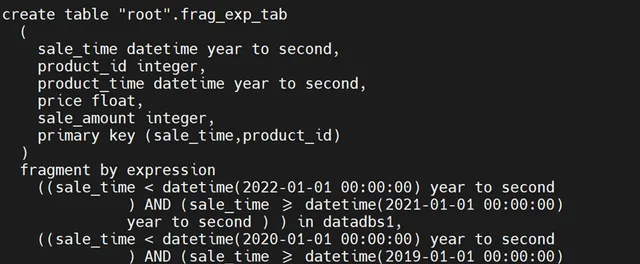
create table frag_exp_tab
(
sale_time datetime year to second,
product_id int,
product_time datetime year to second,
price float,
sale_amount int,
primary key(sale_time,product_id)
)fragment by expression
sale_time < '2022-01-01 00:00:00' and sale_time >= '2021-01-01 00:00:00' in datadbs1,
sale_time < '2021-01-01 00:00:00' and sale_time >= '2020-01-01 00:00:00' in datadbs2,
sale_time < '2020-01-01 00:00:00' and sale_time >= '2019-01-01 00:00:00' in datadbs3;
create index idx_frad_exp_tab on frag_exp_tab(product_time,product_id);
#命令列中輸入以下命令,可以查詢當前表對應索引
oncheck -ci t:frag_exp_tab
#在GBase 8s中自動為主鍵、外來鍵、唯一約束建立索引,預設情況下為detached索引。
#GBase 8s自動建立的索引名字為空格+tabid_+一個序號組成。
Validating indexes for t:root.frag_exp_tab...
Index 101_1 #detached索引
Index fragment partition rootdbs in DBspace rootdbs
Index idx_frad_exp_tab #attached索引
Index fragment partition datadbs1 in DBspace datadbs1
Index fragment partition datadbs2 in DBspace datadbs2
Index fragment partition datadbs3 in DBspace datadbs3
1.建立索引的註意事項
註意:產生'-872'錯誤碼的原因:
在分片表上,如果要建立一個unique的attached索引,需要在索引中包含分片的key欄位,所以基於運算式的分片表上可以建立,不能在輪轉法上建立。
2.detach索引替代delete功能展現
前文開始部份就提到,detached索引還可以起到將分片表中某一分片快速分離的作用,下面進行一個操作實踐,直觀感受一下detach起到的替代delete的功能。
①首先我們建立一個detached索引。
create index idx_frad_exp_tab2 on frag_exp_tab(product_time,sale_time) in datadbs4;
②其次向裏面插入一部份數據,為了清晰的展示分片分離。
insert into frag_exp_tab values('2021-09-06 00:00:00',1,'2000-01-01 00:00:00',999.9,1);
insert into frag_exp_tab values('2020-09-06 00:00:00',2,'1999-01-01 00:00:00',666.6,2);
insert into frag_exp_tab values('2019-09-06 00:00:00',3,'1998-01-01 00:00:00',333.3,3);
insert into frag_exp_tab values('2020-05-01 00:00:00',4,'2000-01-01 00:00:00',111.1,1);
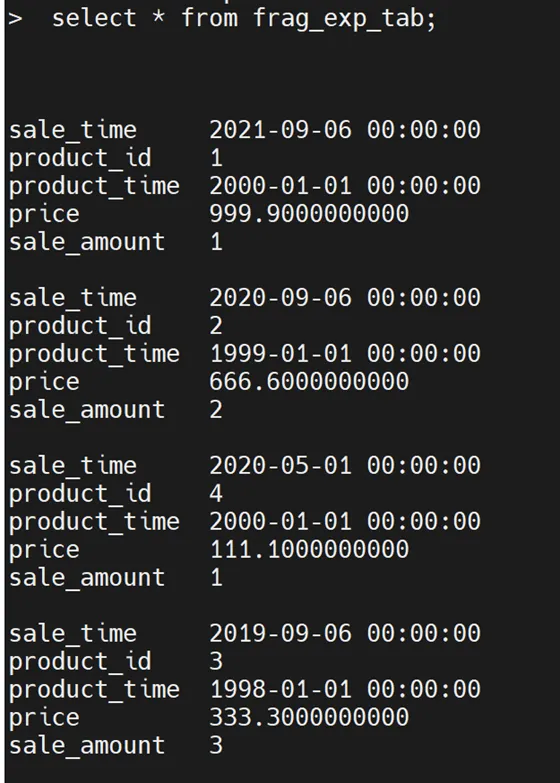
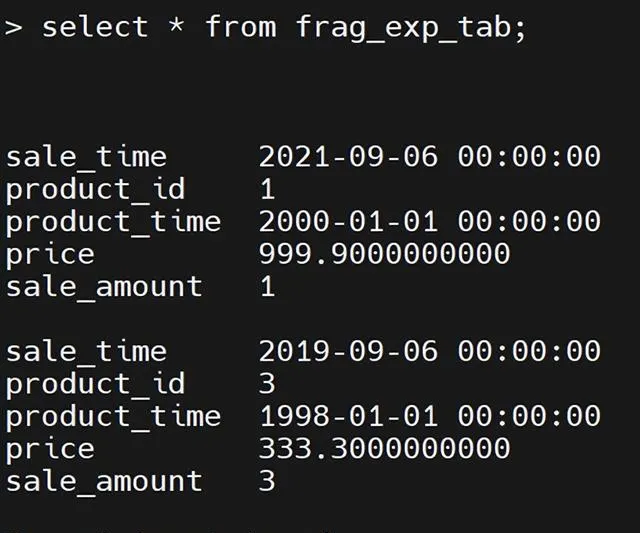
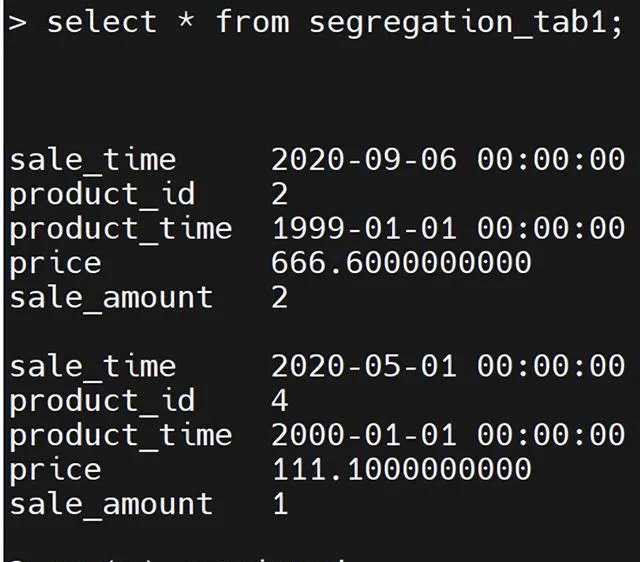
③執行detch子句,將範圍區間分片datadbs2從表frag_exp_tab拆離並放置到新的未分片表segregation_tab1中。
alter fragment on table frag_exp_tab detach partition datadbs2 segregation_tab1;
3.在現有分片表上增加一個新的分片
①首先在命令列下執行語句,檢視我們當前表的結構狀態。
dbschema -d t -t frag_exp_tab -ss
②我們向裏面加入一個新的分片。
alter fragment on table frag_exp_tab add
sale_time < '2021-01-01 00:00:00' and sale_time >= '2020-01-01 00:00:00' in datadbs2
before datadbs3;
③檢視當前表結構,可以看到,已經增加了一個分片,操作成功。

四、dbspace資料庫空間
在實作GBase 8s分片技術時,基本都會使用到增加資料庫空間的操作,下面對dbspace進行一下簡單操作介紹。
1.增加dbspaces空間
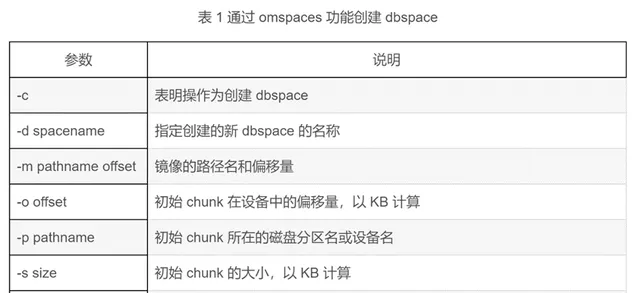
建立新資料庫空間,使用onspaces命令。
onspaces -c -d-k-p-o-s
在linux環境中頁大小預設2k,這裏我們建立一個新的datadbs1,大小為1024000kb。
cd /home/su/gbase/storage
touch datadbs1
chmod 660 datadbs1
chown gbasedbt:gbasedbt datadbs1
onspaces -c -d datadbs1 -k 2 -p /home/su/gbase/storage/datadbs1 -o 0 -s 1024000
以下例子為建立一個臨時 dbspace,名為 tempdbs1,大小為 500000,使用裸裝置/dev/rdsk/device9,偏移量為 100000:
onspaces -c -t -d tempdbs -p /dev/rdsk/device9 -o 100000 -s 500000
2.檢視空間大小
使用命令onstat -d 檢視資料庫空間資訊。

number 為表空間唯一標示號;
pagesize 資料庫空間的頁大小;
flag 列資訊:
Position 1: M 映像
N 未映像
Position 2: X 新映像
D Down,不可用chunk
P 物理恢復完成,等待邏輯恢復
L 正在邏輯恢復
R 正在恢復
Position 3: B BLOB空間
P 物理日誌空間
S 智慧大物件空間
T 臨時空間
U 臨時智慧大物件空間
W SDS主節點的臨時空間,只在SDS備節點顯示
Position 4: B 空間可包含大於2G的chunk
Position 5: A 空間自動擴充套件
每個資料庫空間有一個Chunk檔。Chunk輸出資訊中有size資訊,這個資訊是Chunk的頁的數據,不是檔的字節大小。要得到Chunk的檔字節大小,需要用這個size乘以Chunk檔對應的資料庫空間的pgsize。
3.檢視空間剩余大小
剩余大小就是chunk輸出資訊中free數據乘以Chunk檔對應的資料庫空間的pgsize。











