大多數人一想到人工智慧,就會想到 ChatGPT 之類的聊天機器人、DALL-E 之類的影像生成器,或者用於預測蛋白質折疊結構的 AlphaFold 之類的科學套用。然而,很少有人認為物理學是人工智慧系統的核心。但人工神經網路的概念確實首先是生物物理學、統計物理學和計算物理學這三個學科的物理學研究融合的結果。正是由於這項在 20 世紀 80 年代主要開展的開創性工作,人工智慧和機器學習才得以廣泛套用,並滲透到我們今天的日常生活中。

2024 年諾貝爾物理學獎授予約翰·霍普菲爾德 (John Hopfield) 和傑佛瑞·辛頓 (Geoffrey Hinton),以表彰他們在人工神經網路方面的開創性進展,這最終導致了我們今天所熟悉的生成式人工智慧套用的爆炸式增長。
「人工智慧」竟然與物理學有關,這一想法表面上可能有些牽強。你可能會問自己:「為什麽電腦科學的突破會獲得諾貝爾物理學獎?」當然,這是一個好問題,因為表面上看兩者之間的聯系並不明顯。但是,讓我們來看看物理學的三個不同分支領域:
· 生物物理學,
· 統計物理學,
· 和計算物理學,
最終會給出令人滿意的答案。具體來說,機器學習的基礎是統計物理學,而導致其誕生的理念——人工神經網路——則直接源於生物物理學。

人類大腦被普遍視為奇跡,成人大腦中估計有 860 億個神經元,神經元之間的連線數量是成年人的 7000 倍。盡管許多人預測,在不久的將來,人工智慧機器將擁有更多的連線和「神經元等價物」,但人類大腦的組成遠不止神經元(包括大量神經膠質細胞),其復雜性尚未完全了解。
因此,人們推斷,人們可以嘗試建立一個「人造」大腦,或者至少是一個能夠學習辨識模式的東西,方法是構建一個行為類似的網路。出現的想法被稱為人工神經網路。實際上,人工神經網路只是一種電腦模擬,但這種模擬具有以下特點:
· 你有可以接受特定值的節點,這些節點代表神經元,
· 節點之間存在連線,這些連線會根據節點是否一起受到刺激而增強或減弱,這代表了突觸。
隨著時間的推移,如果你一遍又一遍地刺激連線的節點,連線就會加強,而如果你在一個節點不刺激另一個節點時刺激它(反之亦然),連線就會減弱。
現在,試著想象一下回憶很久以前聽到、看到或經歷過的事情的過程。幾個月前,我自己就有過這樣的經歷,當時我在看電視節目【別忘了歌詞】的一集,當時他們播放了 Rick James 的歌曲【Super Freak】。這首歌我聽過很多次,我敢發誓我知道所有的歌詞,但當他們在以下歌詞後停止音樂時:
「那個女孩現在非常狂野,她是一個超級怪胎,
是那種 ___ ___ ___ ___ ___ ___ ___ 「
我被難住了。我知道這首歌的所有歌詞:那個女孩很古怪,那個女孩是個超級怪胎;每次我們見面時,我都很喜歡嘗嘗她的味道,但這並沒有讓我得到答案。我試著哼唱薩克斯獨奏;但沒用。然後我試著唱這段歌詞,之後,我的大腦意識到,那個女孩現在很狂野,那個女孩是個超級怪胎,就是 你在新浪潮雜誌上讀到的 那種女孩。然後我驚呼道:「哦,我的天,我是世界上最聰明的人!」

瑞克·詹姆士(本名詹姆士·安布羅斯·強森二世)的墓碑,由本文作者於 2023 年拍攝:幾個月後他開始創作【別忘了歌詞】。
剛才發生了什麽?你有這種感覺嗎?作為一個有大腦但記憶力不完美的人,這說明了我們的記憶是如何運作的:透過刺激大腦的相關部份,即在形成記憶時和之前回憶起這些記憶(或資訊)時受到刺激的部份,你可以觸發大腦中「找到」你正在尋找的模式的部份的刺激。這個重要概念被稱為關聯記憶:你的大腦不僅儲存模式,而且當你「記起」之前發生的事情時,它會試圖重新建立這些模式。透過觀察你大腦中的單個神經元,這一點是無法明顯的發現的;這是一種需要大腦中各個部份協同作用的突發行為。
這個偉大的想法啟發了約翰·霍普菲爾德:他是一位物理學家,之前曾研究過分子生物學問題,後來對神經網路產生了興趣。在思考神經元同時放電的集體行為時,他使用了與其他表現出類似集體行為的物理系統進行類比:流動流體中形成的渦流以及磁化系統中原子和分子的方向。霍普菲爾德推測神經元的集體行為可以產生計算或學習能力,然後試圖透過在人工神經網路中展示這一點來證明它。

自然神經元透過各種突觸相互連線,隨著突觸連線的加強,神經元更有可能同時激發:這是大腦學習時發生的現象。人工神經網路將這些神經元建模為編碼有特定值的節點,節點的連線性可以增強或減弱,這取決於它們是否采用彼此相同或不同的值。
霍普菲爾德首先建立了一個人工神經網路(同樣,這只是一個電腦程式),其中有大量節點,每個節點只能采用兩個值之一:0 或 1。(或者,與磁自旋類似,自旋向上或自旋向下。)就像許多磁性材料的情況一樣,相鄰節點(或原子/分子)的自旋值會影響相關節點(即原子/分子)的值,該神經網路中節點的值部份由連線節點的值決定。就像磁化材料趨向於平衡配置或能量最小化的配置一樣,霍普菲爾德對他的人工神經網路進行了編程,以根據一系列預編程模式將所有節點上的能量最小化:您可以將其視為「訓練」數據集。
另一種思考方式是想象你有一個網格,比如說,長 14 個元素,高 19 個元素:總共 266 個元素。你一開始有一個「輸入模式」,就其本身而言,它可能看起來什麽都不像。但是,如果你有一系列參考模式(你可能稱之為「已保存」模式),則可以將輸入模式與所有可能的參考模式進行匹配,以檢視哪一個是最接近的匹配。這可能會叠代進行,一步一步地最佳化你的輸入模式,以更好地匹配接近的參考模式。即使在你的輸入模式有雜訊、不完美或部份被刪除的情況下,你通常也可以恢復與你的輸入模式最匹配的最佳、最正確的已保存模式。

Hopfield 模型的理念是,存在一系列可能的輸出:對於任何一組輸入,都可以得出解決方案。即使在輸入有雜訊、損壞或其他不完美的情況下,最優選的「谷值」也將對應於保存的模式之一,根據演算法和訓練數據,該模式與輸入模式最匹配。
Hopfield 網路能夠執行這種相當原始的模式匹配,這將為尋找不完整或損壞的數據與「真實」參考數據集之間的匹配鋪平道路,這種匹配在影像分析領域仍有套用,包括物件辨識和電腦視覺。盡管如此,Hopfield 的原始模型從根本上受到被視為可能答案的任何一組單獨的「保存模式」的限制;它本質上不是生成性的,而只能進行模式匹配。
這就是今年另一位諾貝爾物理學獎得主傑佛瑞·辛頓 (Geoffrey Hinton) 的工作意義所在。它不關註特定的個體模式,而是將其概括為包括模式的統計分布:包括實際上不屬於任何參考數據集的模式。(例如,如果您的參考集僅包含字母表中的 26 個字母,您可能還會期望統計分布中的字元代表多個字母連在一起,例如 æ。)您可能希望以某種前所未見的方式從數據中平均得出多個可能的解決方案,例如文本中的點「t」或交叉「i」。
辛頓的第一個重大進步是用第一個真正的生成模型——波茲曼機取代了原始的霍普菲爾德模型。

在 Hopfield 網路中,所有節點都相互連線,節點之間的連線具有權重。在波茲曼機中,有可見節點層(輸入和輸出),它們之間有隱藏節點網路。在受限波茲曼機中,同一層的節點之間沒有連線,只有相鄰的不同層的節點之間有連線。
在波茲曼機中,你仍然有一個輸入或一組輸入代表你的初始數據,你仍然會得到一個輸出或一組輸出代表你的電腦程式最終會讀出的內容。然而,在輸入層和輸出層之間,可能存在各種隱藏層:隱藏節點(這些節點不僅不屬於任何參考數據集,而且在任何時候都不是人類(或程式設計師)輸入的節點)將輸入與輸出分開。這些隱藏層允許將更一般的機率分布納入分析,這可能導致任何簡單的演算法都無法發現的意外輸出。
雖然這種型別的電腦(波茲曼機)由於計算資源利用效率低下而套用有限,但它促使 Hinton 和其他合作者想到了一種更精簡的模型:受限波茲曼機,其:
· 將輸入連線到隱藏層,
· 其中隱藏層在連線到輸出之前先連線到另一個隱藏層,
· 然後呼叫反向傳播,隱藏層可以相互通訊,
· 最終收斂到最佳最終輸出。
這一進步極其重要,原因十分深刻:它證明了具有隱藏層的網路可以透過這種方法進行訓練,以執行之前被證明在沒有這種隱藏層的情況下根本無法解決的任務。
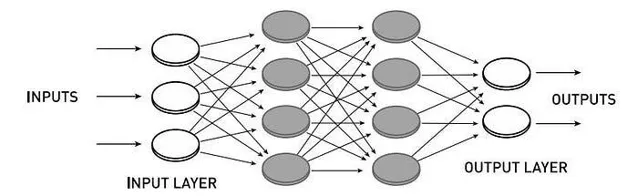
這個前饋網路(無反向傳播)的範例是受限波茲曼機的範例:其中輸入層和輸出層之間至少有一個隱藏層,並且節點僅連線在不同層之間:而不是同一層的節點之間。
透過限制不同型別的節點(輸入-隱藏、隱藏-輸出)之間的連線,但禁止同一型別的節點(輸入-輸入、輸出-輸出或同一層的隱藏-隱藏)之間的連線,計算速度和效率顯著提高。隱藏節點的重要性和功能已不容否認。
很快,這項新技術開始得到成功套用。銀行現在可以自動將支票上的手寫數位(0、1、2、3、4、5、6、7、8、9)分類,無需人工幹預。影像、語言甚至臨床和醫學數據中的模式都可以被辨識;早期未曾預料到的進步之一是能夠辨識影像中的「角落」特征。如今,近乎即時和近乎通用的語言轉譯幾乎已經成為一種理所當然的技術,但它的根源要歸功於霍普菲爾德和辛頓。
後來,其他方法被證明能夠取代基於受限波茲曼機的預訓練,節省更多的計算時間,同時仍然能夠實作深度和密集人工神經網路的相同效能。

這是 iask.ai 針對整數的查詢截圖,以及其嚴重錯誤的響應。正確答案是 -5,這需要輸入幾個額外的提示才能誘導 AI 做出正確響應。
然而,仍然有大量的套用具有實際的積極價值。人工神經網路擅長於:
· 即使對於最復雜的數學函式來說,它也是極好的函式逼近器,
· 近似多體量子系統,精確模擬需要極高的計算量,
· 非常好地模擬原子間和分子間的作用力,從而能夠對某些類別的材料及其應表現出的特性做出新的預測,
· 並可延伸到復雜的物理系統。
物理系統套用非常廣泛,包括基於物理的氣候模型、尋找可指示加速器對撞機中新粒子(包括希格斯玻色子)的粒子軌跡、從南極的 IceCube 探測器繪制微中子中的銀河系、辨識人類搜尋演算法遺漏的淩日系外行星候選者,甚至用於處理用於構建事件視界望遠鏡的第一張黑洞事件視界影像的數據。

事件視界望遠鏡 (EHT) 合作計畫拍攝的兩個黑洞大小對比:位於梅西耶 87 星系中心的 M87* 和位於銀河系中心的人馬座 A* (Sgr A*)。盡管梅西耶 87 的黑洞由於時間變化緩慢而更容易成像,但從地球上看,銀河系中心周圍的黑洞是最大的。人工神經網路對於分析和處理用於恢復這些影像的數據至關重要。
或許最深刻的是生物和醫學套用——也許具有諷刺意味的是,這又回到了生物物理學,而生物物理學是人類對人工神經網路產生興趣的科學。AlphaFold 可以僅基於底層胺基酸序列預測性地計算完全折疊的蛋白質結構,包括三級和四級結構。使用人工神經網路的機器學習可以大大提高基於乳房 X 線檢查影像的乳癌早期檢測率(而不會增加假陽性率)。它是我們擁有的用於糾正患者在接受 MRI 掃描時身體任何部位發生的自願和非自願運動的最佳工具。
雖然肯定會有一大批把關不放、持反對態度的物理學家大喊「這是電腦科學,甚至不是物理學」,但重要的是要記住,同樣的事情也曾被說過:
· 化學物理學,
· 生物物理學(生物物理學),
· 計算物理學,
· 統計物理學,
以及物理學的所有其他分支領域。人們也曾以類似的理由嘲笑諾貝爾獎授予原子鐘和計時。對於那些這樣想的人,我想說:僅僅因為這個領域是你不感興趣的物理學的一個方面的結果,並不意味著它不是物理學,當然也不意味著它不值得獲得諾貝爾獎。我們是否將人工智慧、機器學習和人工神經網路用於社會的利益或弊端並不是重點。重點是,這種強大的新技術正變得越來越普遍,正是物理學的洞察力導致了它的誕生和它能力的許多巨大飛躍。我們接下來要怎麽做,完全不在諾貝爾委員會的掌控之中,就像炸藥和高爆炸藥的發明者諾貝爾本人無法控制他的發明以後會如何使用一樣。對於全人類來說,下一步該怎麽做,取決於我們自己。











