西風 發自 凹非寺量子位 | 公眾號 QbitAI
「我想問在座一個問題,無論是求真書院還是丘成桐少年班的同學,如果這個問題都不知道,那你就不應該在這個班!」
2024國際基礎科學大會「基礎科學與人工智慧論壇」上,聯想集團CTO、歐洲科學院外籍院士芮勇此言一出,全場都有些緊張了起來。
但緊接著,他丟擲的問題卻是:13.11和13.8哪個大?

好家夥,就問誰還不知道這個梗。
不過,這次不是嘲笑模型失智。來自學界業界的幾位AI大牛,分析了模型「幻覺」等等一連串問題,引出了他們對「人工智慧的下一步該怎麽走」的看法。

總結來說,包括以下幾個觀點:
大模型發展下一步要走出「沒有抽象能力、沒有主觀價值、沒有情感知識」的搜尋範式。
商業套用落後於模型本身規模增長,缺乏一個超級產品,能真正把投入的價值體現出來。
幻覺限制下,下一步可以思考如何再擴大模型的泛化性和互動性,多模態是一個選擇。
使智慧體知道自己的能力邊界,是一個很重要的問題。
……
香港大學數據學院院長、香港大學電腦系系主任馬毅在討論過程中甚至為現在主流在做的「人工智慧」打上了問號:
人工智慧技術發展積累了很多的經驗,有些我們可以解釋,有些我們不能解釋,現在正好就是非常需要理論的時候。實際上過去這十幾年我們的scholarship可以說是沒有太多突破的,很大可能是被產業、被工程技術的快速發展影響了學術本身的節奏。

一起來看大佬們具體都說了啥。
何為智慧本質?
現場,香港大學數據學院院長、香港大學電腦系系主任馬毅,特別以「回歸理論基石,探尋智慧本質」為題發表了主旨演講。
其中的觀點與其在圓桌上討論的問題不謀而合。
馬毅教授演講主題是「回歸理論基石,探尋智慧本質」,其中回顧了AI歷史發展行程,並對目前AI發展提出了自己的看法。

他首先講了生命與智慧的前進演化。
在他個人看來,生命就是智慧的載體,生命能產生能前進演化,就是智慧機制作用的結果。而且,世界並不是隨機的,是可預測的,生命在不斷的前進演化過程中,學到更多世界可預測的知識。
物競天擇適者生存,這就是智慧的一種反饋,類似於現在強化學習的概念。

從植物到動物、爬行動物、鳥類,再到人類,生命一直在提高自己的智慧,但有一個現象,好像智慧越高的生命出生以後跟隨其爸爸媽媽的時間越長。為什麽?
馬毅教授進一步解釋:因為基因不夠,一些能力要去學習。學習能力越強,需要學習的東西越多,這才是智慧體的更高級形式。
如果以個體方式進行學習,還是不夠快不夠好,所以人發明了語言,人的智慧變成一個群體智慧形式。
產生了群體智慧,發生了一個質變。我們不光只是從經驗觀測去學習這些可預測的現象,還出現了抽象邏輯思維,我們把它叫做人的智慧,或者後來叫做人工的智慧。
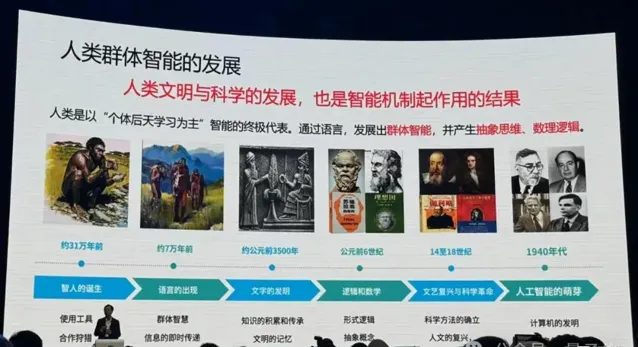
接下來,他講了機器智慧的起源。
上世紀40年代起,人類開始嘗試讓機器模擬生物尤其是動物的智慧。
人類開始從神經元建模,探索「大腦感知是怎麽回事兒」,之後大家發現模擬動物神經系統這件事情應該從人工神經網路去搭建整體,研究變得越來越復雜。

這件事情並不是一帆風順,中間經歷了兩個寒冬,大家發現了神經網路的一些局限性,有些人仍在堅持解決這些挑戰。
之後數據算力發展,訓練神經網路變成了可能,越來越深的網路開始發展起來,效能越來越好。
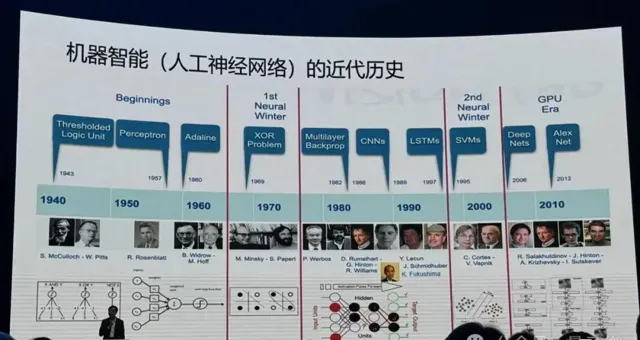
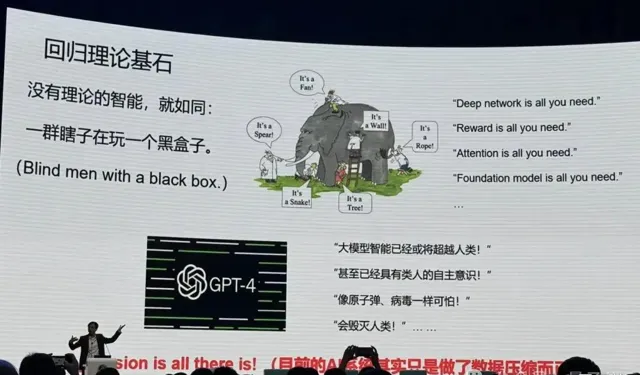
但有個最大的問題:這些網路都是經驗設計的,它是個黑盒子,而且這個盒子越來越大,人們不知道裏面在幹什麽。
黑盒有何不好?從技術角度,經驗設計也可以,可以不斷試錯。但是其中代價很大,周期很長,結果很難控。此外:
只要這個世界上有大家解釋不了的但是很重要的現象,很多人被蒙在鼓裏,就會制造恐慌,現在這個事情正在發生。
所以,如何把黑盒開啟?馬毅教授提出要回到本來的問題:為什麽要學習?生命為什麽能前進演化?
他特別強調,一定要談能透過計算實作的東西:
不要談任何抽象的東西,這是我給大家的建議,你一定要談怎麽去計算,怎麽去執行這件事情。

所以要學什麽?
馬毅教授認為,要學可預測的規律性的東西。
比如手裏拿著一根筆,一松手,大家都知道會發生什麽,而且動作快的話還能抓住。這在牛頓之前就是已知的。人和動物貌似都是對外部世界做了很好的建模。
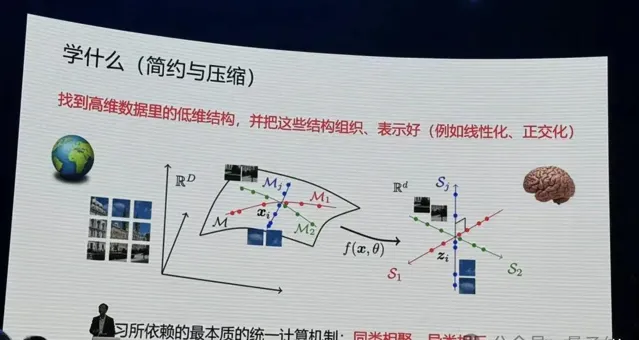
而在數學上,可預測的資訊都統一以數據在高維空間中的低維結構體現出來。
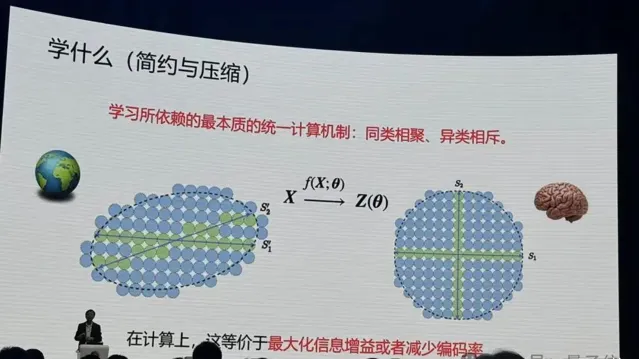
那麽統一的電腦制是什麽?馬毅教授給出了回答:同類相聚、異類相斥,本質就這麽簡單。
如何度量做的好不好?為什麽要壓縮?
他舉了個例子,如下圖。比如說世界是隨機的,什麽都不知道,所有的事情皆可發生,如果用藍色球代替,下一秒鐘所有藍色球都是可能發生的。
但如果要記住其中一件事情發生,就要對整個空間編碼,給它一個程式碼,只有綠色球的區域才可能發生,藍色球的部份就會少很多。
當我們知道的會發生的區域越細後,我們對這個世界的未知就變得越來越少,40年代資訊理論就是在建立這個事情。
要想更好找到這些綠色區域,就要在大腦裏面把它組織的更好。所以我們的大腦是在對這種現象,對這個低維的結構在做這種組織。
在計算上如何實作這個目標?
馬毅教授表示,所有深度網路實際上都在做這件事情。像現在Transformer,對影像進行分割,進行分類辨識,就在做這個事情。
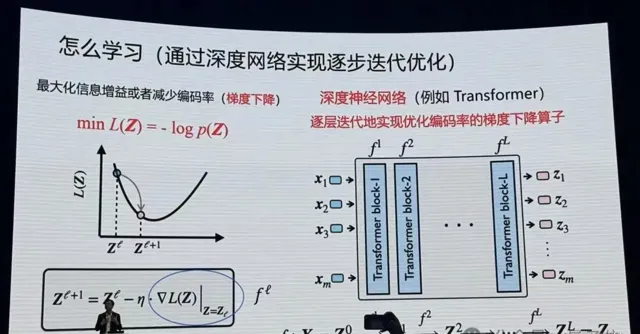
實際上神經網路每一層就是在壓縮數據。
在這當中數學起到非常重要的作用,你去嚴格度量要最佳化什麽東西,嚴格去講怎麽去最佳化,當你把這兩件事做完以後,你會發現你得到的算子跟現在經驗找到的很多算子非常相似。Transformer也好,ResNet也好, CNN也好,都是做這件事情以不同的實作方式。而且在統計、幾何上完全可以解釋它在幹什麽。
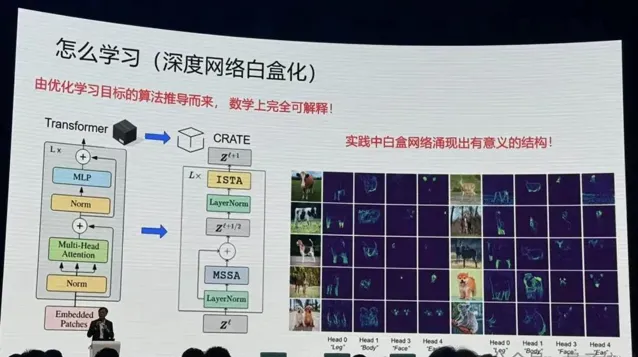
但最佳化本身最優解未必是正確解,在壓縮過程中可能丟掉了重要資訊,怎麽證明現有的資訊維度是好的呢?怎麽證明不會產生幻覺?
回到學習的根本,我們為什麽要記住這些東西?是為了要在大腦裏對物理世界做仿真,為了更好地在物理空間中進行預測。
之後馬毅提到了對齊這一概念:
所以對齊不是跟人對齊,對齊是這個模型自己跟自己學到的東西對齊。
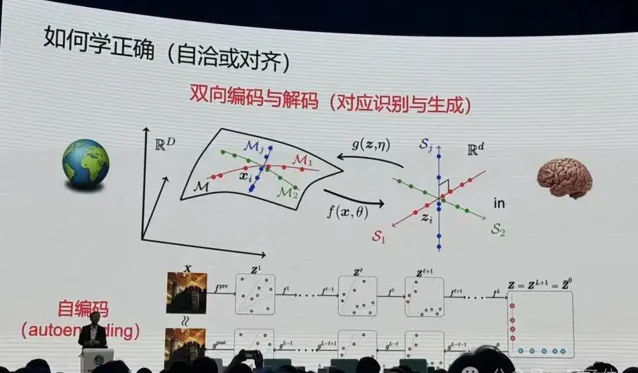
從裏到外兩邊學到一個autoencoding並不夠,自然界的動物是如何學習外部世界的物理模型的——
不斷透過自己的觀測,去預測外部世界,只要和觀測是一致的,就可以了。這就涉及到一個閉環的概念。
只要活著的生物,只要智慧的生物,全是閉環性。
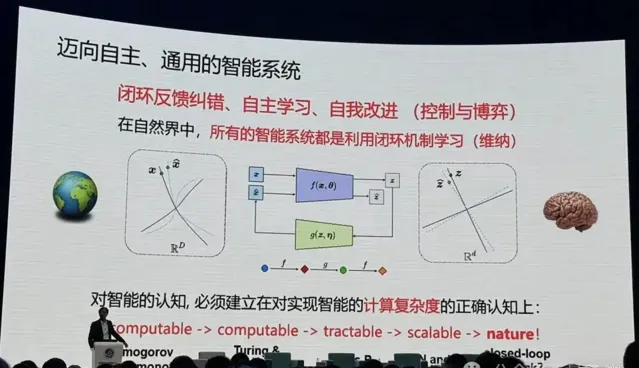
之後馬毅教授引出,我們離真正的智慧還差很遠。
什麽是智慧?大家經常把知識和智慧混在一起,一個系統有知識就是有智慧嗎?一個智慧系統,必須具備自我改進、增加自己知識的基礎。
最後馬毅教授進行了總結。
回顧歷史,40年代大家都想讓機器去模仿動物,但是50年代圖靈提出了一件事——機器能不能像人類一樣思考。1956年達特茅斯會議,一群人坐在一起,他們的目的就是一定要做人區別於動物特有的智慧:抽象能力、符號運算、邏輯推理、因果分析等。
這是1956年他們定義的人工智慧要做的事情,後來這些人基本上都得圖靈獎。所以你以後要得圖靈獎,是選擇去從眾還是做一些獨特的東西……
回看我們過去10年到底在幹什麽?
目前的「人工智慧」在做影像辨識、影像生成、文本生成、壓縮去噪、強化學習,馬毅教授認為,從基礎上我們做的事情就是動物這一層的事情,包括預測下一個token、下一幀影像。
不是說後來我們沒有人在做。但不是主流的大模型。

他進一步解釋,足夠多的錢砸進去,足夠的數據砸進去,模型很多的效能還是會繼續發展,但是長期沒有理論會出現問題,就像盲人摸象。
馬毅教授表示,分享其個人的這段歷程,希望能給年輕人一些啟發。
有了原理我們就可以大膽去設計,就不再等著下一代誰再發明一個好像不錯的網路,咱們再一起用。那你的機會在哪裏呢?
下面來看圓桌論壇中,其他AI大牛對「人工智慧下一步該怎麽走?」這個問題是如何回答的。
人工智慧下一步該怎麽走?
大模型要有「範式」的變化
英國皇家工程院院士、歐洲科學院院士、香港工程科學院院士、香港科技大學首席副校長郭毅可認為,我們現在處於一個非常有趣的時刻——
因為Scaling Law被廣泛接受,百模大戰逐漸形成了一個資源大戰。看似現在只需要做兩件事,有了Transformer模型以後,要解決的就是大算力和大數據的問題。
然而,在他看來事實並非如此。當下AI發展還面臨很多問題,其一是有限算力和無窮需求的問題。
在這種情況下,應該怎樣做大模型?郭院士透過一些實踐,分享了自己的思考。
首先郭院士提到了在算力限制下,采用更經濟的MOE混合專家模型也能達到很好的效果。
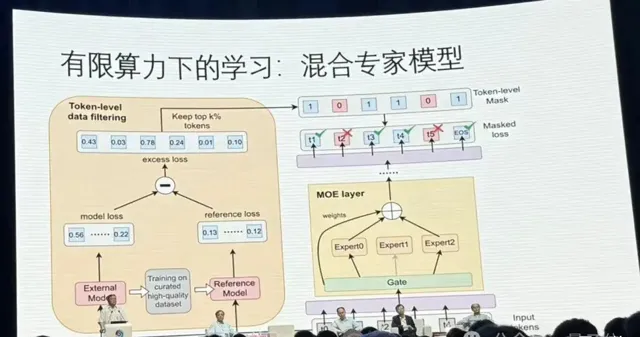
此外,怎樣把一個模型訓完之後,不斷用新的數據改善,讓它能夠把該記住的記住,該忘的忘了,而且在需要的時候還能夠記起已經忘了的東西,也是一個很難的問題。
對於業界的一些「數據已經是用完了」的說法,郭院士表示不認同,「實際上只是變成了模型被壓縮了,而壓縮好的數據可以再生成新的數據」,也就是用生成模型來生成數據。
接著,不是所有東西模型都要從頭學習,可以把知識嵌入到基礎模型裏面。這方面也有很多工作要做。
除了算力,演算法上還有一個問題:機器智慧和人類智慧本身的培養具有兩極性。
郭院士認為,訓練大模型,更重要的問題不在前面,而是在後面。
如下圖所示,大模型的前進演化路徑是從自我學習>間接知識>價值觀>常識,而人類教育的培養路徑與之相反。

正因為如此,郭院士認為應該走出今天大模型「沒有抽象能力、沒有主觀價值、沒有情感知識」的搜尋範式。
我們都知道人類的語言是偉大的,人類語言裏面不僅是內容,不僅是資訊,更多的是人性,是資訊的能量,那麽這些東西怎樣歸類到模型中去?是我們未來研究的一個重要的方向。

總結來說,對於人工智慧下一步該怎麽走,郭院士認為有三個發展階段:
第一個階段以真實性為本;第二個階段以價值為本,機器要有能力闡述自己的觀點,要形成自己的一種主觀價值,並且這個觀點可以根據它的環境來改變;第三當它有了價值觀以後,才懂得什麽是新奇,有了新巫師可能進行創造。
到了創造這個模式,所謂的幻覺不是問題,因為幻覺只有在範式模式下才是個問題。寫小說一定是幻覺,沒有幻覺,寫不出小說來,它只要保持一致性,不需要真實性,所以只要反映一種價值就可以了,所以從這個意義上來講,大模型的發展實際上要有範式的變化。
大模型發展缺一個「超級產品」
京東集團副總裁、華盛頓大學兼職教授、博士生導師何曉冬認為AI下一步面臨三個問題。
首先,他認為從某種意義上來說現在大模型發展進入了一個平台期。
由於數據和算力限制,如果簡單基於規模來提升,有可能達到天花板,算力資源也會成為一個越來越重的負擔。如果按照最新的價格戰(標價),很可能大模型產生的經濟效益連電費都覆蓋不了,那麽自然是不永續的。
其次,何教授認為整個商業套用有些落後於模型本身的規模增長,中長期來看,這終將會成為一個問題:
特別是我們看到這麽大規模的時候,他不再簡單是一個科學問題,它也會成為一個工程問題,比如說參數到了萬億級,呼叫數據到10萬億token級別。那麽必然需要提出一個問題:它帶來的社會價值。
由此,何教授認為目前缺乏一個超級套用和超級產品,能夠真正把投入的價值體現出來。
第三個問題是一個相對比較具體的問題,即大模型幻覺。
如果我們想在大模型之上建設一個AI產業大廈,就要對基礎大模型幻覺有極高的要求。如果基礎大模型錯誤率很高,那麽很難想象這上面可以疊加更多商業套用。嚴肅的產業套用是需要解決幻覺的。
何教授認為在幻覺限制下,下一步可以思考如何再擴大模型的泛化性和互動性,而多模態是一個必然的選擇。

大模型缺乏「能力邊界」認知
聯想集團CTO、歐洲科學院外籍院士芮勇從工業界視角,給出了他對AI下一步的看法。
他表示,從工業界來看,更重要的是模型如何落地。在落地方面,芮勇博士主要講了兩點:
光有大模型是不夠,一定要發展智慧體。
光有雲測大模型也是不夠,需要有一個混合框架。

具體來說,芮勇博士首先列舉了一些研究,並指出大模型目前局限性越來越明顯。比如開頭提到的「13.8和13.11哪個大」的問題,可以看出模型沒有真正理解問題。
在他看來,目前大模型其實只是把在高維語意空間裏看到的海量碎片資訊連線起來,光靠堆砌大算力大網路來造生成式大模型是不夠的,而下一步應該朝著智慧體的方向發展。
芮勇博士特別強調了大模型能力邊界問題。
今天的大模型其實並不知道它自己的能力邊界在哪。為什麽大模型會出現幻覺,為什麽會一本正經胡說八道?其實它不是想騙我們,而是不知道自己知道什麽,也不知道自己不知道什麽,這是一個很重要的問題,所以我覺得第一步要使智慧體知道自己的能力邊界。
此外,芮勇博士表示AI落地光有智慧也不夠,雲上的公有大模型需要面向企業進行私有化。數據驅動加上知識驅動,形成混合的AI模型,而且小模型在很多情況下也非常有用,還有面向個人的模型,能夠知道個人的喜好。
它將不是完全基於雲測的大模型,而是一個混合的端邊雲相結合的大模型。











