(報告的出品方是:中國平安)
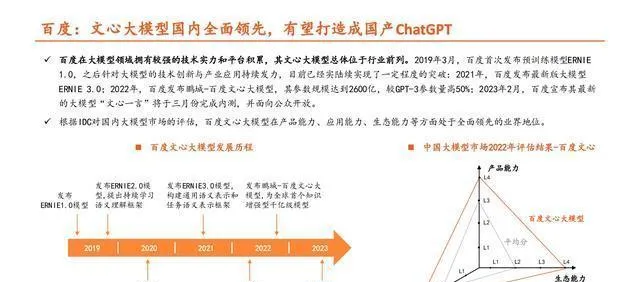
百度的文心大模型在國內是全面領先的,很有希望被打造成國產的ChatGPT。
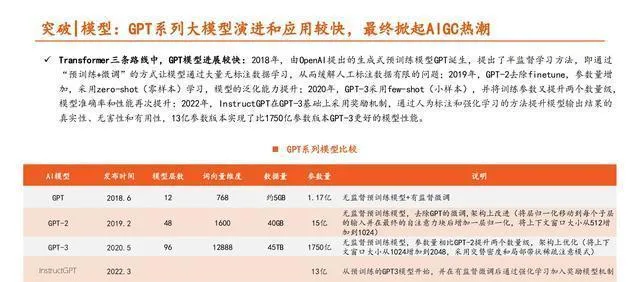
百度在大模型這塊兒有很強的技術和平台積累,文心大模型在行業裏大體上是排在前面的。2019年3月的時候,百度第一次推出預訓練模型ERNIE 1.0,打這以後,在大模型的技術創新和產業套用上就一直下功夫,到現在也陸陸續續有了一定的突破。2021年,百度推出了ERNIE 3.0這個最新版的大模型;2022年,百度又釋出了鵬城 - 百度文心大模型,這個模型的參數規模達到2600億,比GPT - 3的參數量多出50%;2023年2月,百度說它最新的大模型「文心一言」會在3月完成內測,然後對公眾開放。按照IDC對國內大模型市場的評估,百度文心大模型在產品能力、套用能力、生態能力這些方面,在業界是全面領先的。
百度創新性地引入大量知識,文心大模型的效能得到了很大提升。
百度的「文心一言」,其生態建設有了進展,有進行商用拓展的潛力。
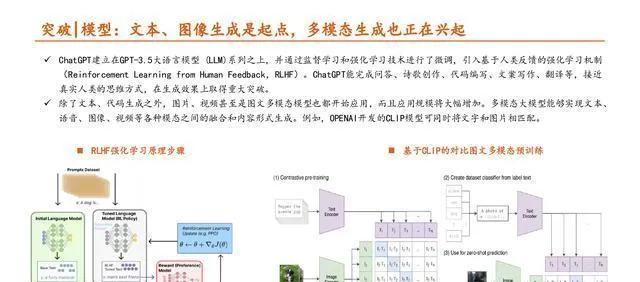
大模型(也叫基礎模型)能夠利用海量、各種各樣的數據(一般是無標註的文本)預先訓練,然後針對很多下遊任務進行微調或者適配。對於不同的任務和套用場景,只要把大模型遷移學習到下遊任務就能達成目的,這樣就解決了傳統自然語言處理(NLP)技術得從頭開始訓練下遊任務的麻煩事兒。
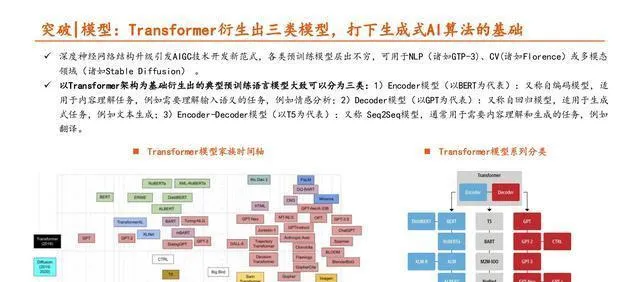
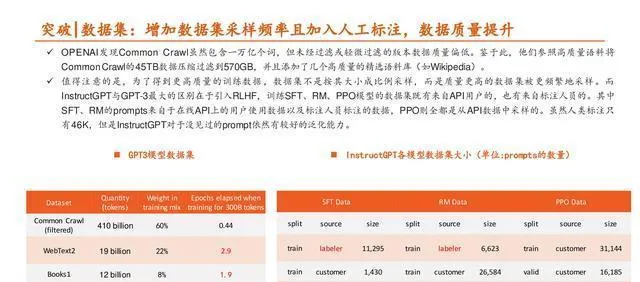
突破 | 數據集:數據量、多樣性、數據品質很關鍵。
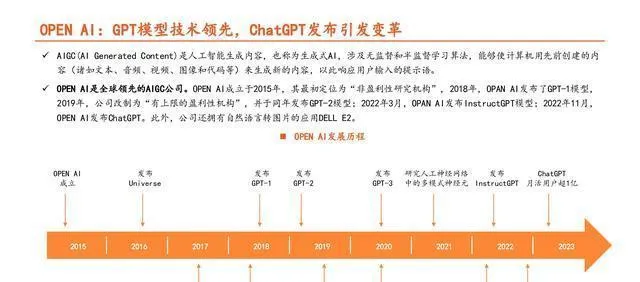
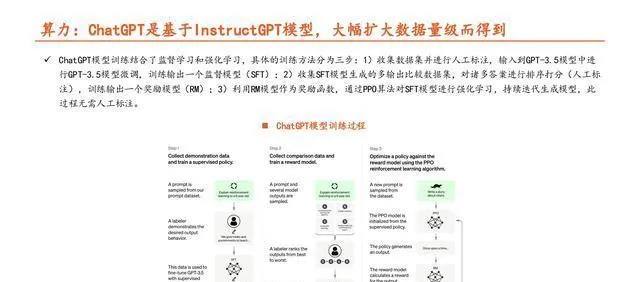
算力方面:ChatGPT是在InstructGPT模型的基礎上,透過大幅增加數據量級而得來的。
ChatGPT模型的訓練把監督學習和強化學習結合起來了,具體的訓練方式分三步:1)先收集數據集,然後人工標註,再把標註好的數據集輸入到GPT - 3.5模型裏對這個模型進行微調,這樣就能訓練得到一個監督模型(SFT);2)收集SFT模型生成的有多個輸出的比較數據集,對很多答案進行排序打分(這一步也是人工標註),透過這個就能訓練得到一個獎勵模型(RM);3)拿RM模型當獎勵函式,用PPO演算法對SFT模型做強化學習,不斷叠代生成模型,這個過程不需要人工標註。
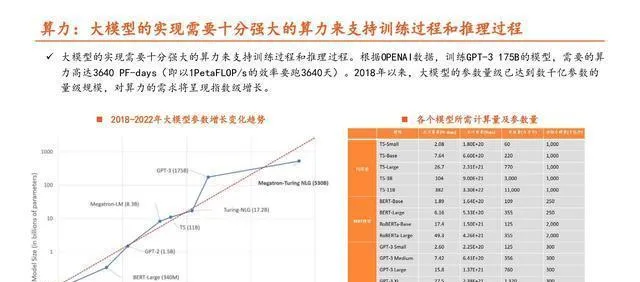
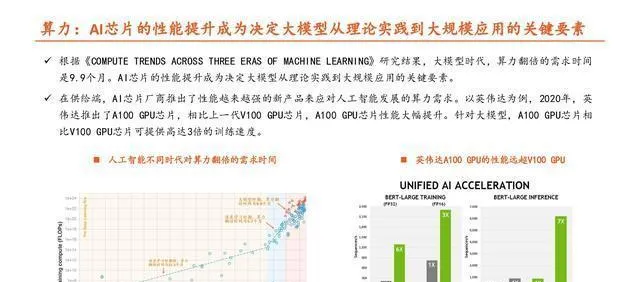
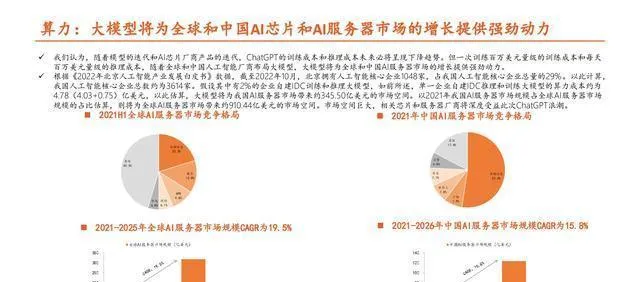
大模型要想實作,在訓練和推理過程中得有非常強大的算力來支撐。
ChatGPT不管是進行訓練還是推理,在算力上花費的成本都很高。
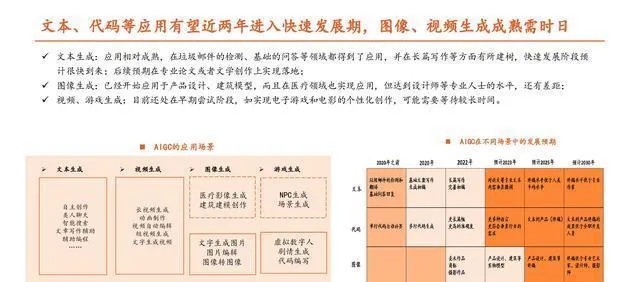
【套用:行業將逐步回歸理性,能否突破需要看B端】
【報告節選:】












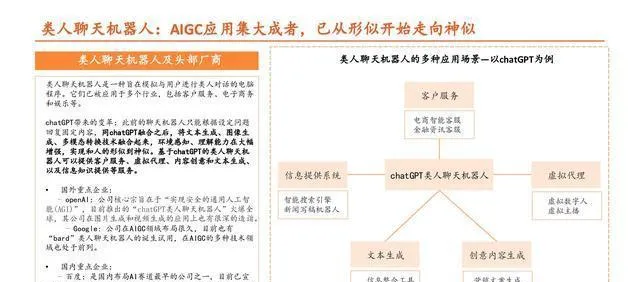





(這篇文章只是用來參考的,不代表我們的任何投資建議哦。要是想要使用相關資訊的話,就去看報告原文吧。)
精選報告來源:【未來智庫】。「連結」











