
自動駕駛技術發展了這麽多年,最大的變化是什麽?
在寫下這篇文章的前一天,兩位汽車行業朋友來到愛範兒,和我們坐下聊了聊。聊到的內容有很多,從產品推廣到行業趣聞,而自動駕駛作為行業熱議的一個分支,自然也成為了我們討論的焦點之一。
回顧自動駕駛這些年來的發展,變化其實有不少,包括傳感器的叠代、車端算力的提升、從高精地圖過渡到占用網路等。但在這些變化中,最引人註目的突破當屬大模型的加入。
大模型,讓自動駕駛技術的套用,變得觸手可及。

10 月 23 日,理想汽車全新一代雙系統智慧駕駛解決方案「端到端+VLM」正式開始全量推播,理想汽車的智慧駕駛,從此步入了 AI 大模型的時代。
像人一樣思考,像人一樣駕駛,如今的理想汽車,正在實作這一願景。
好不容易搞懂了端到端,VLM 又是什麽?
關於端到端到底是什麽?是從哪個「端」到哪個「端」?別說普通消費者了,就連不少媒體從業者都沒有搞清楚。
不少廠商都曾對此做出過解釋,其中解釋得最通俗易懂的,還是理想汽車:
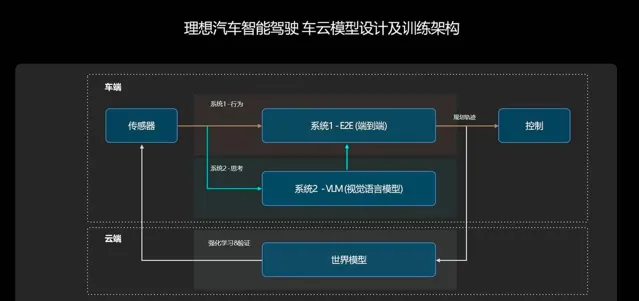
一端,是傳感器:網路攝影機、雷射雷達等傳感器,它們就像是人的眼睛,負責輸入環境資訊。此外還有特別設計的輸入資訊,如車輛的位置、位姿和導航等資訊。
另一端,是行駛軌跡:接收了來自傳感器的資訊後,系統會輸出「動態障礙物」、「道路結構」、「占用網路 Occ」和「規劃軌跡」。前三個感知任務主要透過螢幕呈現給使用者,第四個「行駛軌跡」,就是我們最終需要從傳感器對映出來的東西。
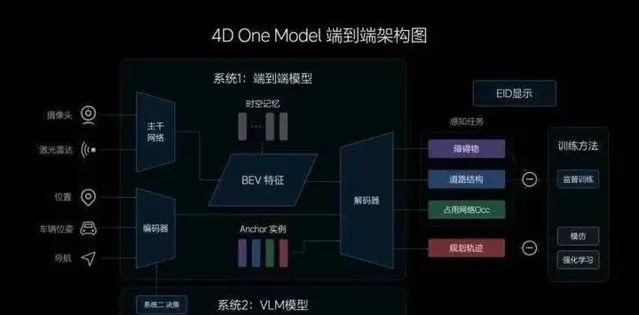
▲理想智駕端到端架構圖
不難發現,從傳感器接收資訊,到系統輸出行駛軌跡這個過程,和我們自己開車非常類似——我們的眼睛負責接收資訊,雙手會自然而然地帶動方向盤,把車輛帶到正確的軌跡上。
是的,依靠端到端模型,理想新一代智駕系統做到了像人一樣駕駛。

一直以來,無論是主機廠還是自動駕駛企業,都在不斷宣傳自家的智駕系統有多麽類人,多麽像「老司機」。然而,一些「老司機」們習以為常的場景,在很長一段時間裏,都是難以解決的行業難題。
最典型的就是環島這一場景,因為場景復雜、感知受限,因此在今年 7 月之前,還沒有幾家車企能夠實作「老司機」般的進出環島。
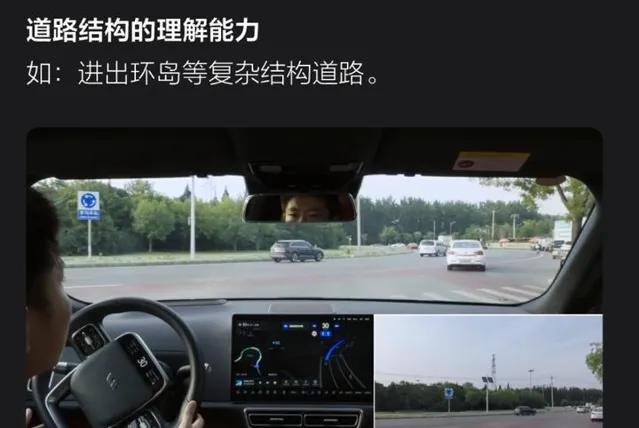
理想智駕技術研發負責人賈鵬曾對愛範兒和董車會表示,對於感知和規控分離的分段式智駕方案來說,在環島場景裏,感知模型需要為規控模型做「各種各樣的假設。」
做個掉頭,還得把掉頭線擬合出來,不同的路口的掉頭還不太一樣,曲率都不太一樣,所以你很難做到一套程式碼就可以把所有環島掉頭搞定,種類太多了。
一體式的端到端方案則不同,其具備更強的復雜道路結構的理解能力,可以運用人類駕駛員數據訓練出不同的環島型別、不同出入口的進出軌跡,自主選擇合適的行進路線。
如此一來,原有的道路拓撲和人工定義的規則,就再是必須的了。
關於環島這件事,賈鵬還分享過一個「好玩的故事」。
在我們(的模型封包含)大概 80 萬 clips(視訊片段)的時候,還過不了環島,後來突然有一天發現我們(餵了)100 萬 Clips(之後)它自己能過環島,我覺得是 100 萬(視訊片段)裏頭剛好有一些環島數據放在裏面了。
「模型確實很厲害,」賈鵬補充道,「你餵了什麽數據他就能學會,這是模型的魅力所在。」
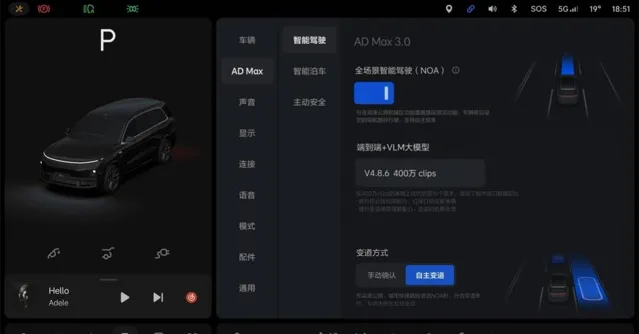
理想如今推出的全量版本基於 V4.8.6 模型,後者是在 400 萬 clips 的基礎上叠代的第 16 個版本。和以往相比,新模型對於超車場景和導航資訊的理解能力得到提升,同時,障礙物的檢測更加精準,繞行的振幅也更為合理。
因此不僅是環島,像 U 型掉頭、擁堵時的蠕行和賽局、十字路口等傳統復雜場景,如今的「端到端+VLM」智駕系統,都能夠很好地自主處理,甚至還支持 P 檔啟用——
在路邊停車時,使用者原地雙擊撥桿來啟用智駕系統,不必再像以前一樣,必須在車道內才能啟用。
介紹完端到端模型的能力,接下來就是 VLM 模型。

VLM 模型是一種視覺語言模型,理想是第一個將視覺語言模型成功部署在車端芯片的廠商,使自動駕駛具備了未知場景的邏輯思考能力。
也就是說,它能夠像人一樣思考。
舉個例子,能夠生成行駛軌跡的端到端模型,完全具備透過收費站的能力,但它在面對收費站時,並不是很清楚自己應該走哪條道,最後只能隨便挑一條來走。
而 VLM 模型,則能夠像人類一樣理解物理世界的復雜交通環境和中文語意,可以清楚地分辨 ETC 車道和人工車道,並輔助端到端模型做出正確的決策。

類似的場景其實還有很多,如公交車道和潮汐車道的辨識、學校路段等路牌的辨識、主輔路的進出等。不僅如此,在遇到施工場景、坑窪路面甚至是減速帶時,VLM 模型也能很好地理解,進行提醒和降速。
截至目前,理想汽車的 VLM 視覺語言模型已經擁有了 22 億的參數量,對物理世界的復雜交通環境具有更擬人的理解能力。
此外,在 OTA 6.4 版本中,高速 NOA 功能也得到了最佳化,在高速 &城市快速路場景中,系統可以更早地辨識前方慢車,超車動作更加高效安全。
總而言之,在端到端+VLM 雙系統的幫助下,如今面向使用者的 OTA 6.4,其擬人化程度上到了一個新的台階。
理想的「快」與「慢」
從技術架構來看,理想汽車這兩年經歷了三次比較大的調整。
從需要先驗資訊的 NPN 網路,再到基於 BEV 和占用網路的無圖 NOA,再到如今的一體化端到端技術路線。
第一代 NPN 架構比較復雜,包含了感知、定位、規劃、導航、NPN 等模組,它們共同支撐起了理想汽車當時 100 城的城市 NOA 推播。

第二代無圖 NOA,理想汽車引入了端到端大模型,模組數量大幅縮減,只剩下了感知和規劃,不再需要等待先驗資訊的更新。
理想的這一步,讓車企的「卷」,不再局限於無聊的開城數量,真正實作了有導航就能開。
今年 5 月,理想汽車招募了 1000 位使用者,正式開啟了無圖 NOA,也就是 AD Max 3.0 的公測。當時的使用者反饋,遠遠超出了理想汽車的預期,短短兩個月後,理想汽車就為 24 萬多位理想 AD Max 使用者推播了這次升級。
只不過,這個時候的端到端,還是一個分段式的端到端,第三代智駕方案,才是真正意義上的一體式端到端——從輸入到輸出,全部由一個模型實作,中間沒有任何規則的參與。
在以往,無論是有圖方案還是無圖方案,都依賴工程師根據各種各樣的道路場景去編寫規則,力圖窮舉所有道路狀況和與之對應的方案,讓智駕的範圍盡可能地廣。
通常來說,廠商會把場景大致分為三種:高速場景、城區場景和泊車場景。這幾大場景又可以繼續細分,規控工程師們則需要針對這些場景來編寫程式碼。
但面對錯綜復雜的現實世界,這樣的做法顯然不夠現實。而一體式端到端,則可以學習人類開車的過程,接收傳感器資訊後,直接輸出行駛軌跡。

有沒有發現,這個時候,提升智駕能力最重要的因素,從工程師變成了數據。而理想,最不缺的就是數據。
10 月 14 日,理想汽車迎來了第 100 萬輛整車在江蘇省常州基地下線,中國第一個百萬輛新勢力車企就此誕生。根據理想汽車公布的數據,在 30 萬元以上的理想車型中,AD Max 使用者的比例,高達 70%——
每過一個月,這些車都能給理想提供十幾億公裏的訓練數據。
另外,理想很早就意識到數據的重要意義,打造了關於數據的工具鏈等基礎能力,比如理想的後台資料庫實作了一段話尋找當時,寫一句「雨天紅燈停止線附近打傘路過的行人」,就能找到相應的數據。
正是憑借龐大的訓練數據和完善的控制鏈,理想智駕實作了在行業中的「後來居上」,用端到端和 VLM 組成了自己的「快」與「慢」。
在理想看來,這套雙系統智駕方案,類似於諾貝爾獎獲得者丹尼爾·卡尼曼在【思考,快與慢】中的快慢系統理論:
人的快系統依靠直覺和本能,在 95% 的場景下保持高效率;人的慢系統依靠有意識的分析和思考,介紹 5% 場景的高上限。
其中,端到端是那個「快系統」,而 VLM 自然就是「慢系統」了。
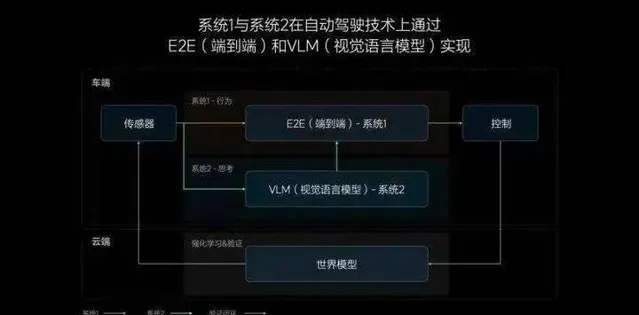
郎鹹朋認為,一個自動駕駛系統到底是 L3 級別還是 L4 級別,並不取決於端到端,VLM 模型才是真正能去應對未知場景,拔高能力上限的關鍵所在。
「理想同學,我要去這裏」
除了智慧駕駛方面的升級,OTA 6.4 在使用者互動方面也引來了革新。
這裏同樣分為「快」和「慢」兩個部份。
作為「快系統」的端到端模型所對應的通常為文字彈窗,為駕駛員即時提供導航、交規、效率、賽局等執行邏輯和動作。
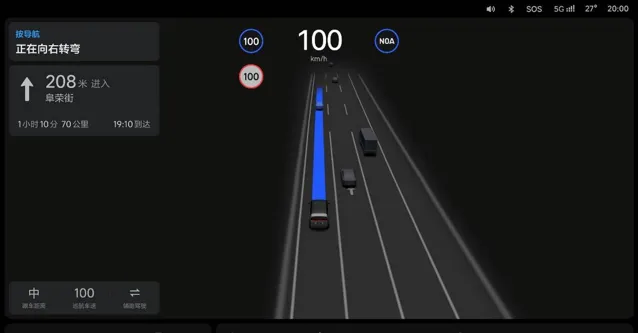
對於「慢系統」VLM 視覺語言模型,理想則為它準備了全新的圖文視窗。在特殊場景下,將前方感知到的畫面投射到頁面內,配合文案講解模型的思考過程和結果。
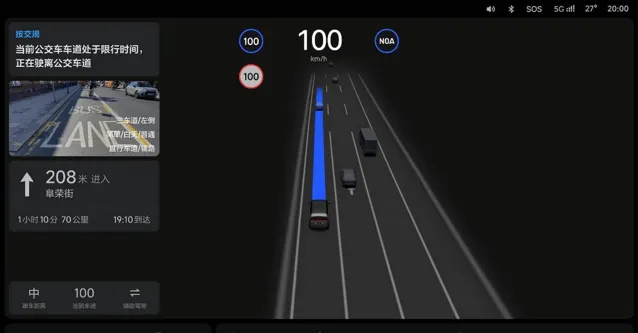
在文字彈窗和圖文視窗的配合下,無論系統執行何種車控動作,駕駛員都能提前知悉。對於那些初次體驗智駕的消費者來說,這種直觀的資訊展示也有助於迅速建立他們對智慧駕駛系統的信任感。
不得不承認,理想汽車對使用者需求的理解確實非常精準。
在我們對於未來的暢想中,智駕和智艙總是繫結在一起的,在 OTA 6.4 版本中,理想也為它的智慧空間帶來了不少升級。
首先是新增的任務大師 2.0 全面接入了理想同學和 Mind GPT 的能力,在大模型的加持下,任務大師的表現更為智慧。

Mind GPT 加持下的理想同學,不僅能夠在周末家庭短途旅行和解答日常小疑問這兩個場景裏發揮作用,結合新升級的高德 AutoSDK 750 版本導航地圖,理想同學可以透過「觸控+語音」的方式,讓駕駛員迅速進行目的地搜尋。
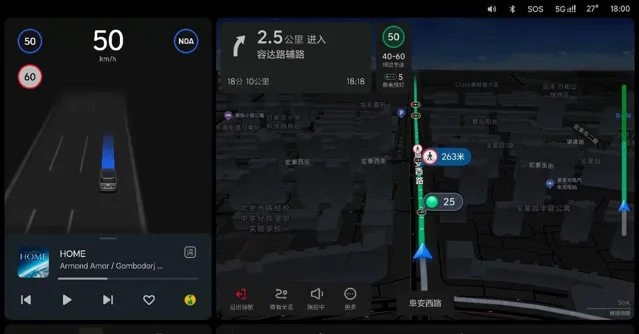
比如說,指著地圖上的某個位置,讓它幫你搜尋充電站任一品牌的充電樁,甚至還可以指定功率。
總之,全新的理想同學完全可以讓你不必拿起手機,你可以用最自然直觀的方式,輕松設定導航路徑。
端到端負責駕駛,VLM 替你思考,而你只需簡單地指引方向。
#歡迎關註愛範兒官方微信公眾號:愛範兒(微訊號:ifanr),更多精彩內容第一時間為您奉上。











