Sora一經釋出,世界再次被AI的力量所震撼。要知道Runway、Pika等明星模型都還在突破幾秒內的連貫性的時候,Sora已經可以直接生成長達60s的一鏡到底視訊。
大家對Sora的更進一步資訊和細節都非常好奇,但遺憾的是,OpenAI並未公布它的技術細節,而只有一份簡單的技術報告。
今天我們就來扒一扒網上對Sora訓練和推理的估算,看看Sora驚艷效果背後的算力究竟是如何的驚人。
分享幾個自用的Claude 3和GPT-4的映像站給大家吧,均為國內可用:
hujiaoai.cn
(最牛的Claude 3 Opus,註冊即用,測評下來完全吊打了GPT4)
higpt4.cn (穩定使用一年的chatgpt-4研究測試站,非商業目的,而且用的是最牛的128k視窗的版本)
從DiT到Sora
在Sora的技術報告中,作者提到Sora的設計很大程度上受到了【Scalable Diffusion Models with Transformers】論文的影響,這篇論文中提到的模型DiT是用於影像生成的,Sora將這項工作擴充套件到了視訊生成。
我們先來看看DiT模型,最大的DiT模型DiT-XL具有675M參數,需要次浮點運算進行訓練。為了使這個數位更容易理解,這相當於大約一台p00執行12天。
下面是對Sora所需的計算量做一個估算:
1、DiT只對影像進行建模,但Sora是視訊模型,我們假設Sora在把圖片變成視訊的過程中沒有額外計算。
Sora可以生成1分鐘的視訊,如果我們假設視訊以24fps編碼,則一個視訊有1440幀(24fps * 60s)。Sora的像素到潛在對映似乎在空間和時間上都進行了壓縮。如果我們假設與DiT論文(8x)的壓縮率相同,我們最終在潛在空間中得到180幀(1440/8)。
2、Sora明顯大於675M參數,之前有傳言GPT3.5的模型大小是20B
所以我們估計Sora為20B是可行的,這需要DiT的30倍計算量。
3、Sora應該是接受了影像和視訊的混合訓練,OpenAI沒有過多談論他們的數據集,但他們暗示它非常大:「我們從大型語言模型中汲取靈感,這些模型透過對互聯網規模數據進行訓練來獲得通才能力。
假設Sora數據集比DiT使用的數據集大10倍到100倍,但DiT在相同數據上重復訓練,若有更大數據集,則此方法並非最佳。因此將計算量增加4-10倍是合理的,取中值7倍作為估算。
所以,把上面的估算結果相乘,訓練Sora的總浮點數計算量約為:
這相當於14739張p00執行一個月!

以當前p00市場價約3萬美元算,14739張p00約需要4.4億美元,老黃直接狂喜。

在能耗方面,p00 GPU的最大功耗約為700W,這需要大概kWh的電力,這相當於一架波音757飛機飛行七百萬公裏的碳排放,可以繞地球赤道轉173圈,環保人士已經要坐不住了。

我們需要更多的顯卡
Sora的訓練已經消耗這麽多了,我們再來估計一下推理所需的資源。
我們再次使用DiT來推斷Sora,DiT-XL每步使用FLOPS,250個擴散步驟總共FLOPS,同樣的方法,乘上30再乘180,我們可以估計:
一個Nvidia p00 GPU大約每小時能生成5分鐘的視訊。
如果視訊作者要依靠Sora來創作,那麽他至少需要十張以上的p00,才能十分鐘內生成合理時長的視訊。這個成本將非常高,肯定不適合普通人來使用。
盈虧平衡
盈虧平衡,即模型達到一個推理的使用量,使得推理和訓練期間的花費相同。
我們傾向於關註的另一個重要考慮因素是訓練成本與推理成本的比較。眾所周知,訓練成本非常大,但也是一次性成本。相比之下,推理成本要小得多,但推理是頻繁呼叫的,推理計算會隨著使用者數量的增加而增加,因此,檢視「盈虧平衡點」是有用的。
按照前面的計算,我們得出下面DiT和Sora的訓練與推理計算的比較。
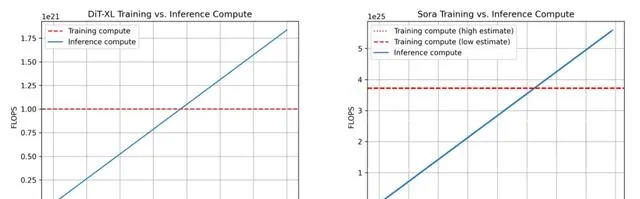
我們可以看到,DiT在生成7.6M影像後達到盈虧平衡點,而Sora在生成53.4M分鐘的視訊後達到盈虧平衡點(約101.53年)
推理成本比GPT4高出幾個量級
為了進一步見識Sora所需計算量之巨大,我們可以對比一下不同模型的每單位輸出,推理計算所需的計算量。
我們先劃定一個標準,對於Sora,每單位輸出是一個1分鐘長的視訊,對於DiT來說,它是一個512x512像素的影像,對於Llama 2和GPT-4,我們將單位輸出定義為包含1000個token的單個文件。
下面是這些模型的對比圖,橫座標是單位輸出的個數,縱座標是所需計算量,因為相差巨大,我們采用對數形式作圖。
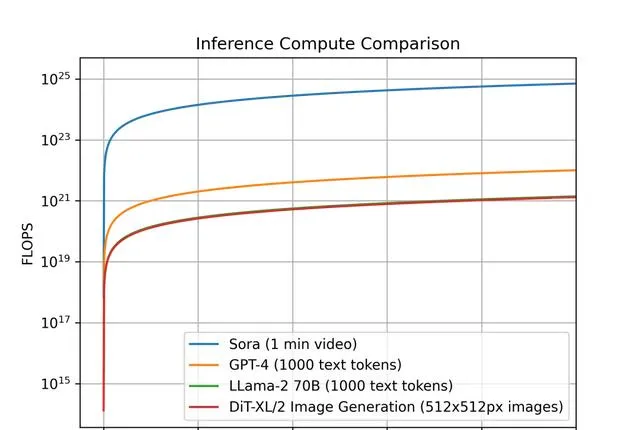
對於Sora和DiT,我們使用上面的推理估計。對於Llama 2和 GPT-4,我們使用 FLOPS = 2 的經驗法則公式估計,即FLOPS=2×參數數量×生成的令牌數量。對於 GPT-4,我們假設該模型是一個混合專家 (MoE) 模型,具有2個專家,每個專家220B參數,且每次前向傳遞都處於活動狀態。
我們可以進一步看到,Sora在推理工作負載方面甚至比GPT-4貴幾個數量級。
未來可期
盡管目前Sora消耗巨大,但它不僅僅是一項技術,還是一個起點,我們相信,未來的視訊生成將會形成一套完整的生態,從上遊的模型到下遊的套用,整個產業將會逐漸被建立。
Sora生成的視訊,無論是在細節水平方面,還是在時間一致性方面(例如,當物體被暫時遮擋時,該模型可以正確處理物體的永續性),對於某些型別的場景來說,已經足夠使用。目前OpenAI選擇和一些藝術和電影工作室合作。
Shy Kids是一家多媒體制作公司,他們利用Sora制作了關於氣球人的短片【Air Head】,導演Walter Woodman評論說:
「盡管Sora在創造看似真實的東西方面很出色,但讓我們興奮的是它能夠創造出完全超現實的東西」,「來自世界各地的人們已經準備好從他們的胸膛裏迸發出故事,終於有機會向世界展示裏面的東西」
Don Allen III是一位跨學科的創作者,他說:
「很長一段時間以來,我一直在制作增強現實混合生物,我認為這些生物在我的腦海中會是有趣的組合。現在,我有了一種更簡單的方法」,「不受傳統物理定律或思維慣例的束縛」,與Sora合作將他的註意力從「技術障礙轉移到純粹的創造力......開啟一個即時視覺化和快速原型制作的世界」
當我們站在視訊內容創作新時代的門檻上時,像Sora這樣的模型的影響遠遠超出了技術領域。我們相信未來隨著技術的最佳化,一個每個人都能擁抱AI,以 前所未有的方式講述自己的故事。












