第一部份:ThinkAny 的發展歷程
介紹一下 ThinkAny
ThinkAny 是一款新時代的 AI 搜尋引擎,利用 RAG(Retrieval-Augmented Generation)技術快速檢索和聚合網路上的優質內容,並結合 AI 的智慧回答功能,高效地回答使用者的問題。
ThinkAny 的目標是:搜得更快,答得更準。
ThinkAny 的定位是做全球化市場,從第一個版本開始就支持了多語言,包括(英語 / 中文 / 韓語 / 日語 / 法語 / 德語 / 俄語 / 阿拉伯語)。
ThinkAny 的官網地址是:https://thinkany.ai
采用雙欄式布局,界面非常簡潔大氣。

我為什麽要做 AI 搜尋引擎
我選擇做什麽產品,一般有三個原則:
- 是我很感興趣的方向
- 產品有價值,能帶來成就感
- 在我的能力範圍內
早在去年 11 月,就有朋友建議我研究一下 AI 搜尋賽道的產品。
當時我的第一想法是,搜尋引擎應該是一類有很高技術壁壘的產品,不在我的能力範圍,所以一直不敢嘗試,也沒花時間去研究。
直到今年年初,有媒體報道:「賈揚清 500 行程式碼寫了一個 AI 搜尋引擎」,當時覺得很神奇,寫一個 AI 搜尋引擎這麽簡單嗎?
花了點時間研究了一下賈揚清老師開源的 Lepton Search 源碼,Python 寫的,後台邏輯 400 多行。
又看了一個叫 float32 的 AI 搜尋引擎源碼,Go 寫的,核心邏輯也就幾百行。
看完兩個計畫程式碼之後,開始「技術祛魅」,號稱能顛覆谷歌 / 百度統治的新一代 AI 搜尋引擎,好像也「不過如此」。
底層技術概括起來就一個詞,叫做「RAG」,也就是所謂的「檢索增強生成」。
- 檢索(Retrieve):拿使用者 query 調搜尋引擎 API,拿到搜素結果;
- 增強(Augmented):設定提示詞,把檢索結果作為掛載上下文;
- 生成(Generation):大模型回答問題,標註參照來源;
弄清楚 AI 搜尋的底層邏輯之後,我決定在這個領域開始新的嘗試。
我給要做的 AI 搜尋引擎產品取名「ThinkAny」,名字直譯於我之前創立的一家公司「任想科技」。
ThinkAny 是如何冷啟動的
ThinkAny 第一個版本是我在一個周末的時間寫完的。
MVP 版本實作起來很簡單,使用 NextJs 做全棧開發,一個界面 + 兩個介面。
兩個介面分別是:
- /api/rag-search
這個介面呼叫 serper.dev 的介面,獲取谷歌的檢索內容。輸入使用者的查詢 query,輸出谷歌搜尋的前 10 條資訊源。
- /api/chat
這個介面選擇 OpenAI 的 gpt-3.5-turbo 作為基座模型,把上一步返回的 10 條檢索結果的 title + snippet 拼接成上下文,設定提示詞,請求大模型做問答輸出。
提示詞參考的 Lepton Search ,第一版內容為:
You are a large language AI assistant built by ThinkAny AI. You are given a user question, and please write clean, concise and accurate answer to the question. You will be given a set of related contexts to the question, each starting with a reference number like [[citation:x]], where x is a number. Please use the context and cite the context at the end of each sentence if applicable.Your answer must be correct, accurate and written by an expert using an unbiased and professional tone. Please limit to 1024 tokens. Do not give any information that is not related to the question, and do not repeat. Say "information is missing on" followed by the related topic, if the given context do not provide sufficient information.Please cite the contexts with the reference numbers, in the format [citation:x]. If a sentence comes from multiple contexts, please list all applicable citations, like [citation:3][citation:5]. Other than code and specific names and citations, your answer must be written in the same language as the question.Here are the set of contexts:{context}Remember, don't blindly repeat the contexts verbatim. And here is the user question:
前端界面的構建也沒有花太多時間,使用 tailwindcss + daisyUI 實作了基本的界面,主要是一個搜尋輸入框 + 搜尋結果頁。
20240619150035
寫完基本功能後,我把程式碼送出到了 Github ,使用 Vercel 進行釋出,透過 Cloudflare 做網域名稱 DNS 解析。第一個版本就這麽上線了。
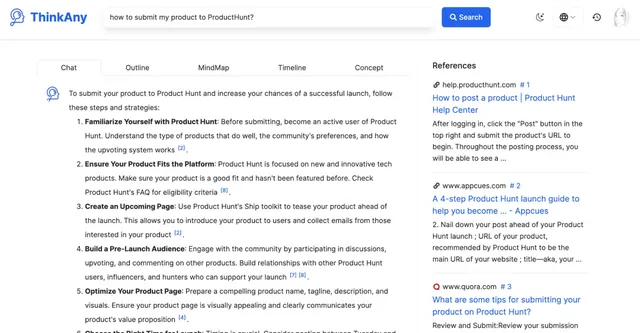
我在 ProductHunt 釋出了 ThinkAny,在微信朋友圈 / 即刻 / Twitter 等地方發動態號召投票,當天 ThinkAny 沖到了 ProductHunt 日榜第四。

20240619153349
ProductHunt 上榜給了 ThinkAny 很大的曝光,接下來幾天,在 Twitter / Youtube 等平台有使用者自發傳播,ThinkAny 完成了還算不錯的冷啟動。
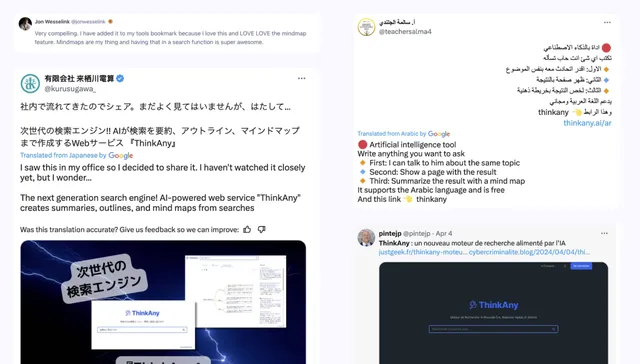
20240619153808
ThinkAny 的產品特性
20240619154427
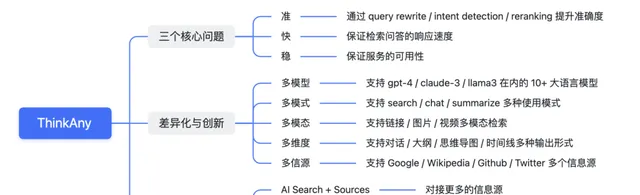
ThinkAny 雖然第一個版本實作的比較簡單,但在創立之初,就一直聚焦在三個核心問題。
也就是我認為的,AI 搜尋的三個要義:準 / 快 / 穩。
❝
準確度是 AI 搜尋的第一要義。
使用者之所以會選擇使用 AI 搜尋引擎,是因為傳統搜尋引擎不能第一時間給到使用者想要的答案,往往需要點進去閱讀幾個連結的內容之後,才能得到足夠多的資訊。
而 AI 搜尋引擎,解決的第一個問題就是搜尋效率問題,用 AI 代替人工,閱讀檢索內容,總結歸納後給到使用者一個直接的答案。
而這個答案,一定要有足夠高的準確度。這是建立使用者信任的基礎,如果準確度不達標,使用者使用 AI 搜尋的理由就不成立。
影響 AI 搜尋的兩個關鍵因素:掛載的上下文資訊密度 + 基座模型的智慧程度。
ThinkAny 在基座模型的選擇上,整合了 gpt-4-turbo / claude-3-opus 等大參數模型,有非常高的智慧程度。
在上下文資訊密度的問題上,采取了並列讀取多個連結內容,暴力傳輸全部內容的策略。
ThinkAny 也緩存了歷史對話,支持對搜尋結果進行追問(連續對話)。
❝
AI 搜尋的響應速度要足夠快
AI 搜尋的底層原理是 RAG,涉及到 Retrieve 和 Generation 兩個步驟。Retrieve 要求聯網檢索資訊的速度足夠快,Generation 要求大模型生成內容的速度足夠快。
除了這兩個步驟之外,為了提高搜尋結果的準確度,需要對檢索結果進行重排(Reranking),需要獲取檢索到的內容詳情(Read Content),這兩個步驟往往是耗時的。
所謂魚與熊掌不可兼得,在 AI 搜尋準確度與響應速度之間,需要找到一個平衡。為了保證搜尋準確度,有時候需要犧牲響應速度,加一些過渡動效來管理使用者等待預期。
ThinkAny 目前采取的方案是,透過開關控制是否獲取詳情內容,線上的版本暫時關閉。表現是響應速度非常快,但準確度不夠高。
後續的版本會重點最佳化準確度,在準與快之間找到一個更好的平衡。
❝
AI 搜尋要保證高可用
軟體產品的服務穩定性(高可用)是一個很常見的話題,使用者規模起來之後,是必須要重視的一項工作。
影響 ThinkAny 可用性的因素,第一個是下遊依賴,也就是搜尋 API 與基座模型 API 的穩定性。
ThinkAny 最初的版本,大模型問答用的是 OpenAI 官方介面,有時候會遇到響應超時和帳號封禁的問題,非常影響可用性,後來切到了 OpenRouter 做多模型聚合,穩定性有了很大的提高。
ThinkAny 當前的線上服務采用的是 Vercel + Supabase 的雲平台部署方案。使用者量和數據量起來之後也有會比較大的效能瓶頸,目前也在基於 AWS 搭建自己的 K8S 集群,後續遷移過來,在服務穩定性和動態擴容方面會有更好的表現。
除了以上三個核心問題之外,ThinkAny 五月初釋出的第二個大版本,在功能差異化方面做了很多創新。
- 多模式使用 Multi-Usage-Mode
支持 Search / Chat / Summarize 三種模式,對應檢索問答 / 大模型對話 / 網頁摘要三種使用場景。
20240619163507
- 多模型對話 Multi-Chat-Model
整合了包括 Llama 3 70B / Claude 3 Opus / GPT-4 Turbo 在內的 10+ 大語言模型。
- 多模態檢索 Multi-Mode-Search
支持檢索連結 / 圖片 / 視訊等模態內容
- 多維度輸出 Multi-Form-Output
支持以對話 / 大綱 / 思維導圖 / 時間線等形式輸出搜尋問答內容。
20240625150128
- 多信源檢索 Multi-Retrieve-Source
支持檢索 Google / Wikipedia / Github 等資訊源的內容,作為搜尋問答的掛載上下文。
另外,ThinkAny 還開源了一個 API 計畫:rag-search,完整實作了聯網檢索功能,並對檢索結果進行重排(Reranking)/ 獲取詳情內容(Read Content),最終得到一份準確度還不錯的檢索結果。
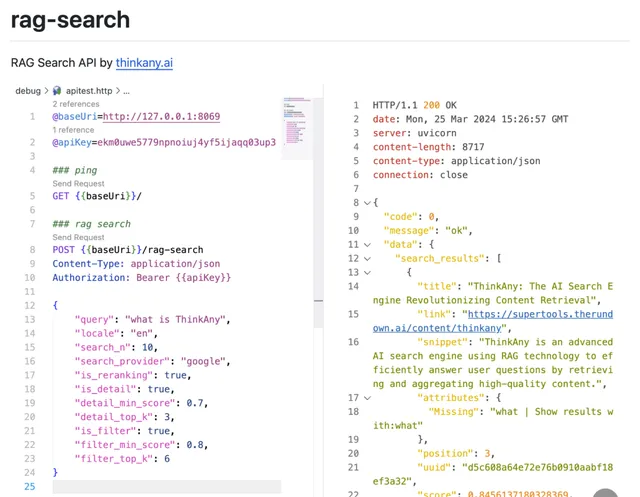
20240619163823
ThinkAny 產品的長期發展方向,會走 AI Search + Anything 的平台化路線。
允許使用者掛載自訂資訊源(Sources)/ 建立自訂智慧體(Agents)/ 實作自訂的流程編排(Workflows)
ThinkAny 要保證基礎能力的完備性,結合第三方的創意,實作一個更智慧的 AI 搜尋平台,覆蓋更多的搜尋場景。
ThinkAny 的營運情況
ThinkAny 於 2024/03/20 正式釋出上線,當天獲得 ProductHunt 日榜第四的成績。
3 個月累計使用者 170k,日均 UV 3k,日均 PV 20k,日均搜尋 6000 次。
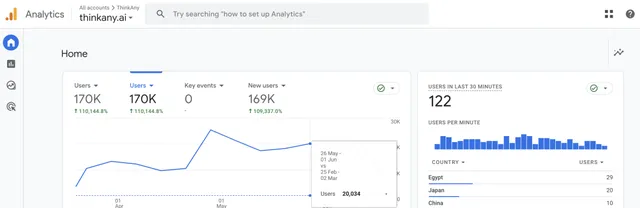
20240619181257
主要使用者分布在埃及 / 日本 / 印度 / 美國 / 中國和其他中東地區。
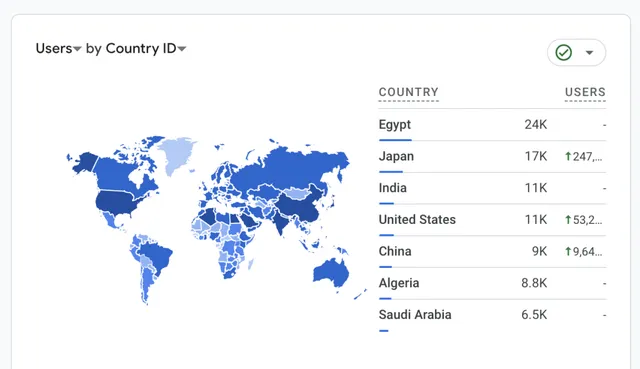
20240619181548
月存取量 580k(基於 similarweb 數據估算),5 月實際存取量較 4 月份增長 90%。
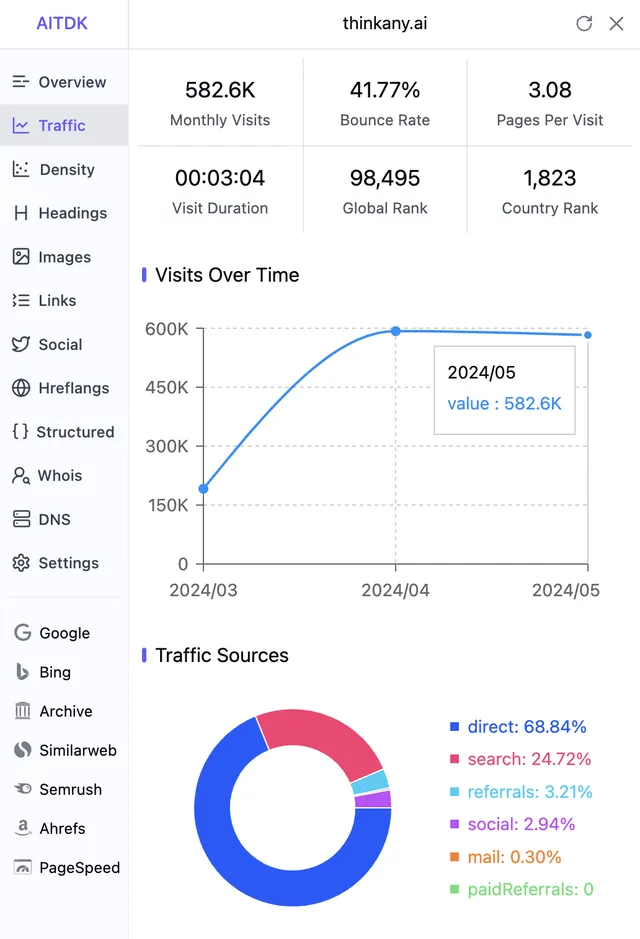
20240619181354
根據 YouTube / Twitter 等平台的使用者反饋,使用者最喜愛的功能是 ThinkAny 對搜尋結果的思維導圖摘要功能。
5 月份釋出的第二個大版本,上線了使用者增值付費功能,然而目前統計到的支付率比較低,僅為 0.03% 左右。
主要支出在於搜尋 API 和大模型 API 的成本,當前還未實作營收平衡。
第二部份:關於 AI 搜尋的認知分享
AI 搜尋的標準流程
AI 搜尋,一般有兩個流程:一個是初次檢索, 另一個是檢索後追問。
用一張流程圖表示如下
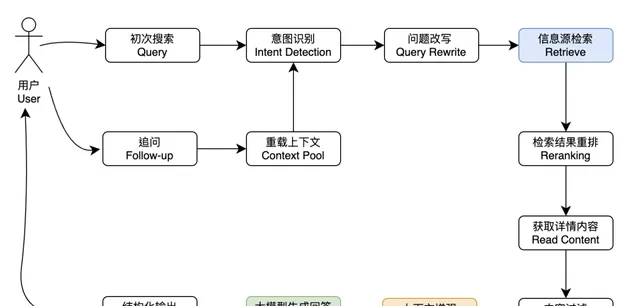
20240625165151
對於初次檢索的處理,大部份的 AI 搜尋引擎產品都是一致的步驟。
而對於追問的處理,不同的 AI 搜尋產品可能會有不同的處理方案。
比如 Perplexity 的追問模式,會繼續走聯網檢索的流程,拿到新的參照資訊後,再進行回答。
ThinkAny 目前的版本,只在初次搜尋的時候聯網檢索,後續的追問不再重新檢索。
主要考慮的是,大部份場景下,使用者追問是針對初次回答的補充性提問,初次檢索的結果作為回答參考已經足夠,重新聯網檢索沒有太大的必要性,浪費時間,浪費成本,也更容易造成幻覺。
然而,有時候追問也需要聯網檢索新的參考內容,只檢索初次 query 的方案並不適用於所有場景。
後續的版本,ThinkAny 打算透過 Context Pool 來覆寫追問邏輯,允許聯網檢索新的參照內容,透過連結過濾降低 Context Pool 中參照內容的重復度,最大可能提升多輪問答的準確度,降低幻覺。
AI 搜尋如何提升準確度
上面講到了,AI 搜尋的第一要義是準確度。影響搜尋準確度的兩個關鍵因素是:掛載的上下文資訊密度 + 基座模型的智慧程度。
對於一個 AI 套用層產品,計畫前期不太需要關心模型層面的事情,我們也沒有太多精力去從模型層面進行突破。
在基座模型的選擇上,如果不考慮成本的問題,優先使用 gpt-4-turbo / claude-3-opus 等模型,暴力傳輸所有的檢索內容,也能有比較好的效果。然而,有時候也會有比較大的幻覺問題。如果支持追問,對話輪數多了之後,會面臨 context 長度的瓶頸問題。
提升 AI 搜尋引擎的準確度,另一個方向是最佳化檢索得到的上下文資訊密度。主要包括以下幾個措施:
- 意圖辨識 Intent Detection
在聯網檢索之前,先對使用者的 query 進行意圖辨識(Intent Detection)。意圖辨識的目的是對使用者的搜尋意圖進行分類,路由到合適的資訊源,召回更精準的參考資訊。
首先,可以判斷使用者 query,是否需要聯網。
比如,使用者輸入:「你好」,「你是誰」,「10 的 9 次方等於多少」之類的問題時,可以不聯網檢索參考資訊,直接用大模型訓練好的知識庫進行回答。一些數學問題 / 編程問題 / 生活常識問題,有標準答案的,就不需要再聯網檢索。
判斷是否聯網,可以節省一次搜尋成本,也能更快速的響應使用者提問,提升搜尋效率。
主要實作方案有兩種:
第一種是內建問題庫,把無需聯網的常見問題緩存起來,再跟使用者提問做相似度匹配,如果使用者提問命中關鍵詞庫,就直接大模型回復,不聯網檢索。
第二種是設定提示詞,請求大模型判斷是否需要聯網。
第一種方案會有列舉無法窮盡的問題,第二種方案主要問題在於大模型的辨識準確度不夠高。
意圖辨識另一個關鍵作用,是對使用者提問進行分類,比如可以把使用者的搜尋意圖分為:
還有其他一些分類,包括多級子分類。照樣面臨列舉無法窮盡的問題。
對搜尋意圖進行分類,可以匹配更準的資訊源和更好的回復提示詞。
比如搜尋「膝上型電腦」,如果能提取出一個「shopping」意圖,就可以掛載亞馬遜 / 淘寶 / 京東等電商平台的資訊源進行更小範圍內的搜尋,召回的資訊會更加精準。同時也可以載入跟此類搜尋意圖匹配的提示詞樣版,來控制搜尋後的大模型回答內容。
意圖分類是搜尋前一個非常關鍵的步驟,可以很大程度提升檢索召回率,透過不同的提示詞樣版總結輸出,保證了搜尋結果的個人化。
目前主流的實作方案,主要是透過提示詞,請求大模型完成辨識。不管是成熟的大模型,還是微調的小模型,準確度都不夠高。
大模型提供的 Function Calling 能力也可以理解為一種意圖辨識。
- 問題覆寫 Query Rewrite
在完成意圖辨識,確認需要聯網檢索之後。可以對使用者的 query 進行覆寫(Rewrite)。Query Rewrite 的目的,是為了得到更高的檢索召回率。
Query Rewrite 可以透過設定提示詞請求大模型完成。
主要包括三個維度的覆寫:
比如使用者搜尋:「ThinkAny」,覆寫後的 query 可以是:「ThinkAny 是什麽?」,再把問題轉譯成英文:「What is ThinkAny」,同一個問題,雙語分別檢索一次,得到更多的參考資訊。
比如使用者搜尋:「ThinkAny 是什麽?」,得到第一次回復後繼續追問:「它有什麽特點?」,用歷史對話內容作為上下文,把第二次 query 覆寫成:「ThinkAny 有什麽特點?」,指代消解後再去檢索,會有更高的召回率。
比如使用者搜尋:「ThinkAny 和 Perplexity 有什麽區別?」,可以把 「ThinkAny」 和 「Perplexity」 兩個名詞提取出來,分別檢索。
- 多資訊源聚合 Multi Source
提升 AI 搜尋準確度,另一個關鍵措施就是做多資訊源整合。
結合上面提到的意圖辨識和問題覆寫,假設使用者搜尋:「ThinkAny 和 Perplexity 的區別是什麽?」,根據意圖辨識,判斷需要聯網,並且是資訊查詢類的搜尋意圖。
在問題覆寫階段,提取出來 「ThinkAny」 和 「Perplexity」 兩個概念名詞,除谷歌檢索之外,還可以檢索 Wikipedia / Twitter 等資訊源,拿到百科詞條內容和 Twitter 的使用者反饋資訊,可以更好的回答這個問題。
❝
AI 搜尋最大的壁壘在於數據。
多資訊源的整合,可能會涉及到海量數據的處理,包括自建資訊源索引等技術,傳統搜尋廠商做這件事會更有優勢。
依靠 UGC 建立數據飛輪的超級 App,在垂類數據的整合上,也會更有優勢。比如騰訊元寶整合的公眾號數據,小紅書自身的衣食住行攻略類數據,知乎的時事評論數據等,都有比較深的護城河。
- 搜尋結果重排 Reranking
AI 搜尋如果要做多資訊源整合,免不了要對多資訊源的檢索結果做重排(Reranking)。
重排的目的主要是兩個:
第一點很好理解,多資訊源的檢索內容受限於資訊源自身的搜尋實作,有可能出現搜出來的結果不太匹配的情況。就算是谷歌這種聚合資訊源,也會受到 SEO 的幹擾,返回跟搜尋 query 並不匹配的結果。
第二點主要考慮到 context 長度問題,我們可能不太願意暴力傳輸所有的檢索結果,而是選擇其中的 top_k 條結果,獲取詳情,再作為上下文掛載內容。Reranking 的目的就是為了讓最有可能包含準確資訊的結果排到最前面,不至於出現資訊遺漏。
做重排的方案有很多,ThinkAny 嘗試過的方案有兩種:
第一種方案主要問題是效率比較低,第二種方案測試下來準確度不夠高。
- 搜尋內容讀取 Read Content
很多的資訊源(比如谷歌)返回的檢索結果,只包含連結 + 摘要資訊。如果要保證足夠的資訊密度,免不了要獲取連結對應的詳情頁內容(Read Content)。
上一步的 Reranking 讓我們可以選擇其中最匹配的 top_k 條數據,而不至於獲取全部內容導致 context 超限。
為了保證獲取詳情內容的效率,我們需要做一定的並列處理。比如透過 goroutine 或者 python 的協程並列讀取 top_k 條連結,在一次請求耗時內拿到 top_k 條連結的全部內容。
獲取連結詳情內容有很多方案,包括網頁爬蟲 / 無頭瀏覽器抓取 / 第三方 Reader 讀取等。
ThinkAny 目前使用的是 jina.ai 的 Reader 方案。做了一個開關,控制是否獲取連結詳情,為了保證響應速度,線上的版本暫時未開。
- 構建上下文內容池 Context Pool
提高 AI 搜尋的準確度,上下文的控制也是一個非常重要的手段。
比如可以構建一個上下文內容池(Context Pool) = 歷史搜尋結果(Search Results)+ 歷史對話訊息(Chat Messages)
每次搜尋後追問,都帶上這個 Context Pool 做意圖辨識 / 問題覆寫,拿到新的檢索結果後更新這個 Context Pool,並帶上最新的 Context Pool 內容作為上下文請求大模型回答。
Context Pool 裏的 Search Results 可以根據連結做去重,Chat Messages 可以根據相似度匹配做過濾。
需要保證 Context Pool 的內容有較高的資訊密度,同時要控制 Context Pool 的內容長度,不要超過大模型的 context 極限。
對 Context Pool 的構建和動態更新,是一個非常有挑戰性的事情,如果能做好,對搜尋結果的準確度提升也能起到非常大的幫助。
- 提示詞工程 Prompt Engineering
提升 AI 搜尋的準確度,在提示詞的設計和偵錯方面也需要花很大的功夫。
上述的很多個環節,都需要用到提示詞,比如:
提示詞工程是一個很系統的學科,有實操指南,有方法論。不能一招通吃,只有經過大量偵錯,才能設計出一套適合自身業務的提示詞。
- 多模態檢索 Multi Mode
提升 AI 搜尋的關鍵步驟是保證檢索到的資訊密度。只拿資訊源檢索返回的摘要內容肯定不夠,前面我們也提到了要並列獲取多個連結的詳情內容。
多模態檢索是提升資訊密度的一個重要措施。隨著 5G 的發展,互聯網上的資訊越來越多元化,圖片/視訊/音訊占了很大的比重。多模態檢索就是為了盡可能多的獲取不同形式的資訊,再聚合起來作為參照參考。
多模態檢索的實作是非常困難的。涉及到海量資訊源的處理和辨識。現階段可以在谷歌搜尋的基礎上完成多模態檢索的需求。
第一步我們可以使用谷歌的圖片/視訊檢索 API,拿到跟 query 匹配的圖片/視訊內容。第二步要做的工作是透過 OCR 圖片辨識 / 音視訊轉錄等方法,拿到多模態資訊的文本內容。
第一步檢索多模態內容很簡單,有現成的 API 可以用。第二步提取多模態內容要麻煩一些,可以在 huggingface / modelscope 等平台找到可用的圖片辨識 / 音視訊轉錄模型。或者使用 gpt-4-o / gemini-1.5-pro 等模型做多模態內容辨識和資訊提取。
作為一個套用層產品,現階段我們在多模態資訊處理層面能做的事情是非常有限的。隨著基座模型的能力提升,後續對多模態的處理會越來越簡單。
AI 搜尋如何提升可玩性
AI 搜尋引擎,最重要的是準確度。
在保證較高準確度的前提下,也要盡可能提升 AI 搜尋產品的可玩性。讓 AI 搜尋整合更多的能力,允許第三方創作,覆蓋到更多的使用場景。
提升 AI 搜尋可玩性的關鍵是讓 AI 搜尋平台化。走 AI Search + Anything 路線。
AI 搜尋平台化主要包括以下幾個層面:
- 開放介面 API
AI 搜尋相比於 ChatBot 類套用,普遍的感知是加上了聯網檢索功能,再由大模型完成回答。
AI 搜尋類產品,可以把聯網判斷 / 意圖辨識 / 問題覆寫 / 資訊源檢索等步驟封裝進一個黑盒,匯出一套標準 API,讓 ChatBot 類產品可以快速整合。
最常見的做法是定義一個 /chat/completions 介面,請求參數跟響應參數與 OpenAI 的 /chat/completions 介面完全相容。
開放 API 之後,ChatBot 類套用只需要修改 API 的網域名稱字首,就可以快速整合聯網檢索功能。
對於 AI 搜尋產品自身,也多了一條 to 小 B 的路子,在增加營收方面會有幫助。
- 自訂資訊源 Source
前面講到了多個資訊源的整合檢索,是提升 AI 搜尋準確度的一種有效手段。
資訊是海量的,遍布在各個孤島。依靠 AI 搜尋產品自身去整合所有的資訊源肯定不現實。AI 搜尋平台化的關鍵之一是允許使用者自訂資訊源,滿足更加個人化的搜尋需求。
比如,允許第三方創作者自訂資訊源,透過 Form 表單填寫資訊源的網域名稱 / 路由資訊 / 參數資訊 / 鑒權方式等內容,偵錯透過後完成對自訂資訊源的整合。
普通使用者使用 AI 搜尋的時候,可以透過主動選擇或者意圖辨識的方式路由到自訂資訊源,檢索得到更加精準的數據。
自訂資訊源甚至可以掛載私域數據,比如透過 Oautp 協定讓使用者授權對 Notion 筆記 / Github 程式碼倉庫的存取,拿到使用者的私有數據。
當然這裏最大的挑戰是私密問題和使用者信任問題,需要設計安全的鑒權方式,同時要讓使用者點選私密協定,允許對私域數據的存取。
- 自訂提示詞 Prompt
前面講到了 Prompt Engineering 在提升 AI 搜尋準確度方面的重要性。
Prompt Engineering 在 AI 搜尋平台化和個人化方面也能發揮很大的作用。
使用者可以透過提示詞自訂 AI 搜尋的輸出格式。比如有人喜歡簡短直接的答案,有人需要長篇大論的研究報告,有人喜歡結構化的輸出。透過自訂提示詞,控制大模型最後的回復格式,把提示詞保存為個人喜好,可以做到搜尋回答千人千面,極具個人化。
AI 搜尋平台要做的,是提供一個好用的提示詞偵錯面板,和範例的提示詞參考,降低使用者建立 / 偵錯提示詞的門檻,保存使用者的個人化設定。
- 自訂外掛程式 Plugin
可以在 AI 搜尋平台偏好設定一些勾點 Hook,用來掛載外掛程式 Plugin 做能力補齊和自訂輸出。
比如,可以偏好設定一個 before_retrieve 勾點,在發起資訊源檢索請求之前,把使用者 query 發給一個第三方外掛程式,由第三方外掛程式來做意圖辨識和問題覆寫。
比如,可以偏好設定一個 after_answer 勾點,在大模型回答完使用者 query 之後,把請求大模型的上下文資訊和大模型的回答內容一起發給第三方外掛程式,第三方外掛程式可以把內容整理成文章 / 思維導圖等格式,再同步到第三方筆記軟體。
在整個搜尋回答的全流程,有很多節點可以做 Hook 埋點,每個 Hook 可以掛載零至多個外掛程式,多個外掛程式構成了 AI 搜尋的可插拔架構,這套架構讓 AI 搜尋的全流程變得高度可客製,可玩性更高。
一些常用的功能,可以由 AI 搜尋平台自身或第三方創作者抽離成標準外掛程式,用在AI 搜尋主流程或者智慧體 / 工作流等輔助流程。
比如,自訂一個思維導圖摘要外掛程式,輸入內容是一段文本,輸出內容是基於 toc(table of contents)構成的思維導圖。使用者可以在搜尋的步驟中選擇這個自訂外掛程式,實作用思維導圖輸出搜尋結果。
- 自訂智慧體 Agent
智慧體是現階段 ChatBot 類產品經常用到的一種輔助產品形態。
智慧體一般是對一些自訂操作的封裝,用於解決某個場景的某類問題。
以 ChatGPT 的 GPTs 舉例,一個智慧體套用由以下幾部份自訂操作組成:
AI 搜尋的智慧體也大體如此,外掛 API 的操作實際上就是掛載自訂資訊源做檢索。
以 Kimi+ 的「什麽值得買」智慧體舉例,假設使用者輸入「我想買個膝上型電腦」,智慧體會先做 Query Rewrite 提取出「膝上型電腦」關鍵詞,再透過「什麽值得買」的 API 檢索對應的商品資訊,拿到檢索結果後,跟智慧體內建的提示詞組裝成上下文,請求大模型回答。於是這個智慧體便成了一個電商導購類的垂直搜尋套用,在商品推薦方面有更好的回答效果。
- 工作流 Workflow
工作流 Workflow 也可以理解為多智慧體協作 Multi-Agents,透過多個智慧體的組裝,解決一些復雜場景的搜尋問題。
比如:給新產品取名,我習慣的步驟是
這裏涉及到一個回溯的問題,也就是在其中某個步驟發現產品名不可用,要回到第一步重新選擇名字,再繼續走後面的檢測步驟。
人工去做這件事,毫無疑問是很費時間的。
AI 搜尋 + Workflow 的模式,可以有效解決這個問題。
首先定義幾個智慧體,每個智慧體完成一項功能。比如 A 智慧體只負責給出建議的名字,B 智慧體負責檢索谷歌是否有同名,C 智慧體負責檢索 Twitter 是否有同名,D 智慧體負責檢測 Github 是否有同名,E 智慧體負責檢測可用的網域名稱...
另外還需要有一個排程中樞,協調每個智慧體的工作,需要做決策,決定是繼續下一步還是回溯到之前的步驟。
工作流編排除了有很復雜的邏輯判斷之外,也會有很復雜的前端互動。比如多個智慧體的拖拽 / 排序 / 連線等。
工作流編排讓 AI 搜尋的可玩性最大化,能夠覆蓋到足夠多,足夠復雜的場景,想象空間很大。
AI 搜尋與內容生態
對於 AI 搜尋,還有一個普遍的認知是:僅靠單邊檢索,用大模型問答來做檢索資訊的整合摘要,價值點是非常低的,也很難實作顛覆傳統搜尋引擎的目標。
因此 AI 搜尋 + 內容生態也是目前很多產品在探索的一個方向。
比如 Perplexity 推出了 Pages 功能,允許使用者把搜尋結果整理成一個內容頁面,作為文章發表。比如最近進入國內使用者視野的 Genspark,主打一個 Sparkpage 功能,也是基於使用者的搜尋行為,用 AI 生成結構化的內容(包括文字 / 圖片等多模態內容),並允許使用者編輯,匯出成 Page。
❝
AI 搜尋產品發展自己的內容生態,是一個非常有價值的方向,內容自產自銷,形成一個有效的閉環,依靠數據飛輪構建產品的護城河。
這裏的關鍵問題,在於 AI 生成的內容品質要高,有一個使用者信任的建立過程。
關於 AI 搜尋的另一個思考,要從我們與資訊打交道的全流程做拆解:
包括資訊獲取 / 資訊摘要 / 資訊生產 / 資訊分發這幾個步驟。
AI 搜尋的單邊檢索,解決的是資訊獲取 + 資訊摘要的問題。
AI 搜尋透過 Pages 生成內容,允許使用者編輯內容,解決的是資訊生產的問題。
AI 搜尋平台化,允許把內容同步到第三方平台,解決的是資訊分發的問題。
使用者訂閱關鍵詞獲取某類資訊的定時推播,可以理解為資訊匹配與資訊分發的結合,是一個雙邊操作。
充分理解使用者與資訊之間的關系與互動流程,用高品質的內容滿足使用者需求,能夠進一步提升 AI 搜尋產品的價值。
AI 搜尋當前的競爭格局
AI 搜尋無疑是今年開年以來最卷的一個賽道。
Perplexity 被認為是全球市場的第一個 AI 搜尋產品,起步於 2022 年 12 月,在 ChatGPT 還沒有席卷全球之前,率先以搜尋 + 模型問答作為切入點,做出了 AI 搜尋的產品雛形。
經過一年多的發展,Perplexity 已經成長為全球市場最大的 AI 搜尋引擎產品,最新估值高達 30 億美金。
在 Perplexity 之後,AI 搜尋領域不斷有新的產品湧現。我主要從以下幾個維度對這個市場的競爭格局做一個簡單的分析。
AI 搜尋目前主要有兩類產品形態。
一類是大模型廠商或第三方推出的 ChatBot,主要互動是一個對話方塊 + RAG 聯網檢索。
這類產品包括 ChatGPT / Kimi Chat 等。
另一類是專門做 AI 搜尋的產品,主要互動是一個搜尋框 + 搜尋詳情頁。
這類產品包括 Perplexity / 秘塔 等。
以上兩類產品形態,除了在互動形式上有所差異。在產品側重點方面也有所不同。ChatBot 類產品依賴的是大模型的理解能力提供問答服務,RAG 檢索作為一個補充手段,彌補大模型在即時資訊獲取方面的不足。
而專門做 AI 搜尋的產品,主要側重點在檢索,優先保證檢索召回的資訊品質,在首次回答的準確度方面有所要求。而對話(Chat)則作為一個補充步驟,方便使用者對檢索結果進行追問或二次檢索。
很難下結論這兩種產品形態哪種更好,跟使用者的喜好和使用習慣有關,因人而異。
這兩類產品都可以歸類於 AI 搜尋的大賽道,在做競爭分析的時候,難免要對比分析大模型廠商推出的 ChatBot 套用。
從今年二月份以來,AI 搜尋賽道不斷有新的產品出來,在市場定位有所差異。
我們看到的,大部份聚焦在國內。比如大模型廠商推出的 ChatBot 產品(智譜清言 / Kimi Chat / 百小應 / 海螺 AI 等),比如搜尋廠商或創業團隊推出的 AI 搜尋產品(360 AI 搜尋 / 秘塔 / 博查 AI / Miku 等)
海外也有很多成熟的和新出的泛 AI 搜尋產品(Perplexity / You / Phind 等)
中國公司和團隊也有面向全球市場的出海產品(ThinkAny / GenSpark / Devv 等)
關於市場定位的問題,跟創始團隊的背景或認知有關,沒有絕對的好壞。
ThinkAny 選擇出海做全球市場,主要考慮的是:
- 國內競爭太激烈,卷不過
- 國內使用者付費意願不高,不太好做商業化
- 國內有些政策風險,沒有成熟的法務合規團隊,不太敢嘗試
除了市場定位,從解決的需求或面向的群體分類,可以分成通用搜尋和垂直搜尋兩類。
比如 Perplexity / ThinkAny 是通用搜尋。
Phind / Devv / Reportify 是垂直搜尋。
通用搜尋一般可以認為,沒有明顯的受眾傾向,任何人可以搜任何問題,都能得到一個相對還不錯的搜尋結果。
垂直搜尋跟通用搜尋比,一般會面向特定的人群或特定的領域,對特定的資訊源做索引和最佳化,在某類問題的搜尋上會有更好的結果。比如 Devv 主要面向的是開發者人群,問編程相關的問題,搜尋結果和回復準確度都比較高,問旅遊或其他型別的問題,回答品質則不如通用搜尋。
通用搜尋和垂直搜尋的好壞,也沒有客觀的評判標準。普遍的認知是:
通用搜尋覆蓋的場景更多,面向的人群更廣,天花板更高,能做到更大的規模。
垂直搜尋面對的市場相對小眾,但是可以更加聚焦,在資料來源整合 / 回復最佳化方面實作起來更容易,對某類特定的問題回答的更好,會有更強的使用者黏性和付費意願。
可以拿獨立的滴滴打車 App,和在微信錢包裏的滴滴打車小程式做一個類比。使用者在需要打車的時候可能更習慣使用滴滴打車 App,但是回到行動網際網路初期,創業者會更想要做一個微信。
AI 搜尋賽道不斷有新的產品出現,競爭非常激烈。
對於後來者,為了搶占市場,會選擇開源的路線。比如 Perplexica / LLM-Anser-Engine 等計畫。
開源是一種有效的增長手段,可以短時間內積累大量使用者,依靠口碑傳播,對品牌曝光 / 流量增長都有很大的促進作用。
ThinkAny 選擇了走商業搜尋的路線,同時也開源了一個 RAG-Search 計畫,把 API 能力開源了,積累了一定的影響力,對 ThinkAny 的品牌曝光也起到了一定的促進作用。
後續的計劃,還是會持續叠代 ThinkAny SaaS 產品。同時也會保持開源計畫的更新,把通用能力抽離出來,賦能到更多的 AI 搜尋場景。
ThinkAny 四月份數據出來之後,增長還不錯。因此我有了找投資的想法。
最近一個多月也陸陸續續聊了一些投資機構。總結了一些投資人對 AI 搜尋賽道的看法,以及當前的資本環境。
- 大環境惡化,經濟下行,基金的數量和規模都大不如前了;
- 基座模型拿走了太多的錢,資本在套用層領域出手非常謹慎;
- 資本很關註大廠的競爭,AI 搜尋是傳統大廠(谷歌 / 百度 / 360)和大模型廠商的戰略方向,必定會重點投入的,小規模團隊沒什麽優勢,面臨的競爭非常大;
- 資本比較關註團隊配置,個人獨立開發不太行得通,這是一場比較大的仗,需要精兵強將;
- AI 搜尋最大的壁壘在於數據,拼的是資源整合能力。所有人都在明牌,講故事的邏輯行不通了;
- 打鐵還需自身硬,比起講故事,最重要的還是自身做增長,盡快找到 PMF,自給自足;
- 資本雪中送炭的機率更低了,更多的是錦上添花的作用;
我對 AI 搜尋的看法
之前傳出 ChatGPT 要做 AI 搜尋引擎,有人問我對這件事情的看法,我在社交平台分享了一些個人觀點:
- AI 搜尋引擎的第一要義是準確度。
準確度的決定性因素主要是兩個:問答底座模型的智慧程度 + 掛載上下文的資訊密度。
做好 AI 搜尋引擎的關鍵,選用最智慧的問答底座模型,再對 RAG 的檢索結果進行排序去重,保證資訊密度。
第一個步驟容易,第二個步驟很難。所以現在市面上大部份的 AI 搜尋引擎,包括 Perplexity,準確度也就 60% 左右。
- ChatGPT自己做搜尋,首先保證了問答底座模型的智慧程度。
其次在檢索聯網資訊層面會做黑盒最佳化,包括 Query Rewrite / Intent Detection / Reranking 這些措施。
最終依賴自身模型的 Long Context 特性,效果就能做到比其他純 Wrapper 型別的 AI Search Engine 要好一點。
- 我並不覺得大模型廠商自己做 AI 搜尋 就一定會比第三方做的好。
比如我做 ThinkAny, 首先接入 claude-3-opus,在模型底座智慧程度方面,就不會輸 gpt-4,第三方甚至能有更多的選擇,針對不同的場景切換不同的模型。
其次,Long Context 也有很多模型能夠保證。
再者,工程層面對 RAG 掛載上下文內容的最佳化,ChatGPT 能做,第三方也可以做。
- 做好 AI 搜尋引擎,最重要的三點是準 / 快 / 穩,即回復結果要準,響應速度要快,服務穩定性要高。
其次要做差異化創新,錯位競爭。比如對問答結果以 outline / timeline 等形式輸出,支持多模態搜尋問答,允許掛載自訂資訊源等策略。
- AI 搜尋引擎是一個持續雕花的過程。
特別是在提升準確度這個問題上,就有很多事情可以做,比如 Prompt Engineering / Query Rewrite/ Intent Detection / Reranking 等等,每個步驟都有不少坑。
其中用 function calling 去做 Intent Detection 就會遇到辨識準確度很低的問題。
用 llamaindex + embedding + Vector DB 做 Reranking 也會遇到排序效率低下的問題。
- AI Search + Agents + Workflows 是趨勢。
AI Search 做通用場景,透過 Agents 做垂直場景,支持個人化搜尋需求。
透過 Workflows 實作更加復雜的流程編排,有機會把某類需求解決的更好。
使用 GPTs 做出的提示詞套用或知識庫掛載型套用,價值點還是太薄。
- 我個人不是太看好垂直搜尋引擎。
一定程度上,垂直搜尋引擎可以在某個場景做深做透,但是使用者的搜尋需求是非常多樣的,我不太可能為了搜程式碼問題給 A 產品付費,再為了搜旅遊攻略給 B 產品付費。
垂直搜尋引擎自建 index 索引,工程投入比較大,效果不一定比接 Google API 要好,而且接入的資訊源太有限。
- AI 搜尋是一個巨大的市場,短時間內很難形成壟斷。
海外 Perplexity 一家獨大,國內 Kimi/秘塔小範圍出圈。各家的產品體驗,市場占有率還沒有達到絕對的領先,後來者依然有機會。
- AI 搜尋引擎需要盡早考慮成本最佳化。
主要支出在於大模型的 token 成本和搜尋引擎的 API 請求費用。
成本最佳化是個持續的過程,比如可以自行部署 SearXNG 來降低搜尋的成本,部署開源模型來降低大模型的 API 呼叫成本。
day one payment,趁早向使用者收費也許是一種 cover 成本的好辦法,但是也要考慮使用者流失的問題。
總結
以上內容分享了 ThinkAny 這款產品的發展歷程以及我對 AI 搜尋這件事的一些看法和認知。
AI 搜尋是一個很性感的賽道,很多的創意可以加上,也有機會做大做強。
ThinkAny 接下來的重點投入方向主要兩個:
- 提升 AI 搜尋的準確度;
- 提升 AI 搜尋平台的可玩性;
個人能力有限,認知不足,很難完全 cover 住,希望能找到一些誌同道合的朋友一起來做這件有意思的事情。

20240625155143
❝
做難而正確的事情,長期主義。
雖然前路艱險,依然砥礪前行。
The only limit to our realization of tomorrow is our doubts of today.

20240625160249











