隨插即用的方法 OVMR 將新類別的多模態線索嵌入到VLM 中,以增強其在開放詞匯辨識中的能力。它最初利用多模態分類器生成模組將範例影像嵌入到視覺標記中,然後透過推斷它們與語言編碼器的上下文關系來自適應地融合多模態線索。為了減輕低品質模態的負面影響,透過一個無參數融合模組根據每個類別對這些分類器的特定偏好,動態地將多模態分類器與兩個單模分類器整合
來源:曉飛的演算法工程筆記 公眾號
論文: OVMR: Open-Vocabulary Recognition with Multi-Modal References
Introduction
開放詞匯辨識旨在辨識訓練集之外的未見過的物件,這是一項具有挑戰性的任務,因為模型對測試集中的新類別一無所知。除了盡量預訓練具有較強泛化能力的模型外,最近的研究還透過將新穎類別線索嵌入預訓練主幹模型來開發更輕量級的策略。在這些工作中,一種流行的策略是在小規模任務特定數據集上微調一個通用模型。這種少樣本微調策略能夠有效最佳化任務特定參數,但耗時、缺乏靈活性,並且降低了泛化能力。
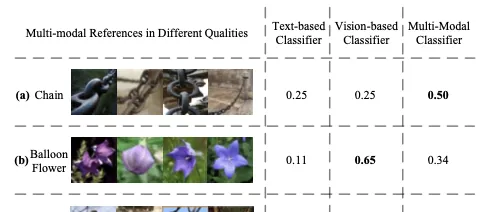
另一方面的研究是利用視覺-語言模型( VLMs )強大的泛化能力,透過提供影像或文本描述作為新類別線索。一些研究使用從文本描述中提取的文本嵌入作為新類別的分類器,但文本描述可能含糊不清,並且缺乏對視覺線索的詳細描述,降低該分類器的區分能力。例如,bat 這個詞既可以指體育器材,也可以指動物。收集範例影像可能是另一個提供類別線索的選項,但影像樣本可能表現出多樣化品質,容易受到域差異、混亂背景等問題影響。
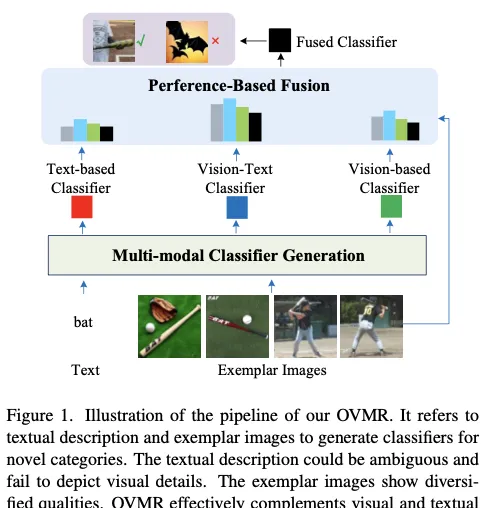
論文從不同的角度解決開放詞匯辨識問題,參考由文本描述和範例影像組成的多模態線索。換句話說,透過將文本描述和範例影像同時輸入 VLM ,挖掘文本和影像的互補線索,從而學習更強大的新類別分類器。如圖1 所示,在此過程中,期望文本模態提供可泛化的語意線索,而範例影像則被分析以提取視覺細節,這對生成分類器的區分能力至關重要。為了緩解低品質文本或影像範例的負面影響,論文還評估了這些單模態和多模態分類器的效能,以自適應生成最終分類器。論文將提出的方法命名為OVMR 。
如圖 1 所示,OVMR 以文本描述和描繪新類別的多個範例影像作為輸入,包括兩個模組來生成最終的分類器:
- 第一個模組動態地融合視覺範例和文本描述以生成多模態分類器,該模組一共包含兩個單模態分類器和一個多模態分類器。首先利用輕量級視覺標記生成器從給定的範例中提取視覺標記,隨後語言編碼器透過推斷它們之間的上下文關系來自適應地融合視覺和文本標記。這個多模態分類器生成模組由於其輕量級結構而非常高效,不需要訓練特定於類別的參數,確保其良好的泛化效能和對各種類別可延伸性。
- 第二個模組透過基於偏好的融合將上述三個分類器生成最終的分類器。為了緩解低品質分類器的負面影響,論文提出了一種透過評估效能來進行動態融合的策略。由於有多個範例影像,將它們作為驗證集來測試每個分類器的效能,最後作為學習融合權重的線索。如圖 1 所示,這個過程透過利用範例影像作為測試集來模擬測試階段,可以有效地保證最終融合分類器的穩健性。
論文進行了大量實驗來測試 OVMR 的效能,在11 個影像分類數據集和LVIS 目標檢測數據集上均明顯優於最近的開放詞匯方法,也優於那些僅簡單套用普通平均融合和文本引導融合來生成新分類器的相關工作。
論文的貢獻可以總結為三個方面:
- 提出了一個靈活的隨插即用模組,將新類別的線索嵌入 VLMs 中,以增強它們在開放詞匯辨識任務中的能力。補充多模態線索相對於僅依賴視覺或文本線索帶來了顯著優勢。
- OVMR 提出了一種從雙模態輸入生成穩健分類器的新型流程。它自適應地融合文本和視覺線索生成多模態分類器,並進一步提出了一個無需參數的融合模組,以緩解低品質模態的負面影響。
- 廣泛的實驗表明, OVMR 在開放詞匯分類和檢測任務中表現出優越效能,展示了其在開放詞匯辨識中的潛力。
Related Work
Open-Vocabulary classification
現有的開放詞匯分類方法可以總結為三類,即預訓練、提示學習和少樣本適應方法。
許多預訓練工作都致力於增強 VLM 在開放詞匯分類中的能力,包括大型策劃數據集和增強的訓練策略。它們需要從頭開始重新訓練模型,這需要相當多的時間、樣本和註釋。
為了有效地增強 VLM 在分類中的能力,業界提出了各種prompt 學習方法(編碼文本和待分類圖片,文本產生類別數個的輸出與圖片編碼計算相似度,取最大的文本)。CoOp 從少樣本數據集中學習靜態上下文標記,但傾向於過擬合訓練類別,在未見類別上效能下降。為了緩解這一問題,CoCoOp 從輸入影像中獲取動態的例項特定標記,旨在改善未見類別的分類。MaPLe 致力於跨不同層次學習視覺和語言分支的多模式提示標記。這些方法需要在每個下遊數據集上進行微調,而且傾向於過擬合已見類別,並且缺乏VLM 中的泛化能力。
Few-shot 分類包括一個訓練階段,在這個階段,模型在一個相對大的數據集上學習,以及一個適應階段,在這個階段,調整學習的模型以適應之前未見任務的有限標記樣本。在這個框架下,可以粗略地分為兩種方法:元學習方法和非元學習方法。最近的一項工作揭示了少樣本影像分類中的訓練和適應階段是完全解耦的。此外,它還表明,使用CLIP 的訓練演算法預訓練的視覺主幹比以前的少樣本訓練演算法表現更優秀。
在論文的工作中,將 CLIP 的預訓練視覺主幹作為基礎模型,並評估不同的適應方法。這些適應方法包括無需訓練的MatchingNet 、Nearest Centroid classifier (PN )以及需要訓練的MAML 、邏輯回歸、余弦分類器、URL 和CEPA 。
Open-Vocabulary Detection
最近的許多工作旨在將 VLM 的開放詞匯能力轉移到目標檢測領域。包括知識蒸餾和prompt 最佳化在內的技術已被用來訓練一個使用預訓練VLM 的開放詞匯檢測器。弱標記和偽框方法也被提出,以增強VLM 的物件級別辨識能力。此外,一些工作在VLM 或SAM 的預訓練視覺主幹頂部添加了新的檢測頭,無論是保持主幹凍結還是可微調。最近,為開放詞匯檢測預訓練視覺-語言模型是一個新方向。GLIP 和DetCLIP 在檢測、定位和字幕數據的組合上進行訓練,以學習單詞-區域對齊。RO-ViT 提出了預訓練區域感知位置嵌入,以增強VLM 在密集預測任務中的能力。
此外,最近的 MM-OVOD 和MQ-Det 引入範例影像以增強用於開放詞匯檢測的文本分類器。然而,MM-OVOD 同等對待兩種模態,並直接計算新學習的基於視覺的分類器與現有文本分類器在VLMs 中的算術平均值,以獲得多模態分類器。MQ-Det 使用文本特征作為查詢,從範例影像中提取資訊,並利用交叉註意機制最佳化原始文本分類器。這是基於文本模態更重要的假設。然而,受範例和文本品質的影響,對兩種模態的偏好應在不同類別之間動態變化。
Differences with Previous Works
OVMR 方法與先前的開放詞匯分類和檢測方法有幾個不同之處:
- 與傳統的需要大量資源的預訓練方法不同, OVMR 使用在較小數據集上預訓練的輕量級視覺令牌生成器。這使得能夠在不完全重新訓練模型的情況下,高效地將新的類別線索整合到模型中。
- OVMR 有效地避免了提示學習方法中固有的過擬合問題,因為它不學習類別特定的參數。此外,插拔內容使其能夠在預訓練後無縫地轉移到各種任務中。
- OVMR 利用語言模型的強大泛化能力,自適應地融合多模態線索。與像MM-OVOD 和MQ-Det 這樣同等對待模態或優先考慮文本的方法不同,OVMR 透過評估它們的效能進一步動態地整合單模態分類器和多模態分類器。這種兩階段的分類器生成流程對於具有低品質範例或文本描述的場景更加穩健,使得OVMR 在各種任務中表現更好。
Methodology
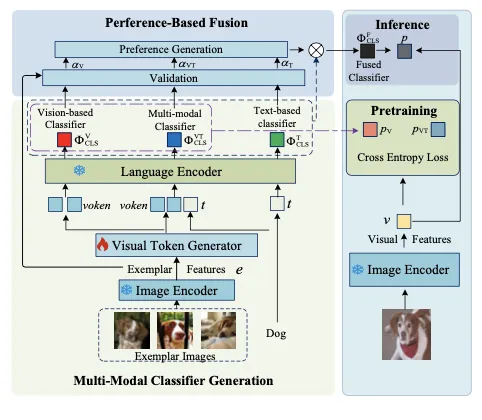
如圖 2 所示,OVMR 由兩個主要模組組成。第一個是多模態分類器生成模組,利用可通用的語言編碼器動態地整合文本和視覺範例。它還包括一個新預訓練的視覺標記生成器,將範例影像嵌入到語言空間中。第二個模組是測試時用的基於偏好的融合模組,不引入任何可訓練參數。
Multi-modal classifier Generation
多模態分類器生成模組旨在透過自適應地融合視覺範例和文本描述來生成多模態分類器。對於感興趣的新類別 ,將其視覺範例、目標影像和文本標記分別表示為 、 和 ,其中 是範例影像數量, 是目標影像數量, 是屬於 類別的文本標記長度, 是標記嵌入的隱藏維度。此外,視覺範例 和目標影像 透過 CLIP 影像編碼器 編碼為範例特征 和視覺特征 。
為了利用語言編碼器生成一個良好的多模態分類器,一個關鍵的先決條件是從視覺範例中提取出語言編碼器能夠理解的穩健的視覺標記,這些視覺標記需要準確地表示具有類別判別性的視覺細節。視覺標記生成器由 個與類別無關的可學習查詢 和四層全域自註意力 Transformer 塊組成。透過利用可學習查詢和範例特征之間的自註意力互動,可學習查詢 自適應地從範例特征 中提取出屬於 類別的視覺標記。這個過程可以形式化為:
其中 表示單詞級別的串聯, 是查詢標記 的相應輸出。
然後,使用語言編碼器分析視覺和文本標記之間的關系,並自適應地生成 類別的多模態分類器的權重 ,其計算方式為:
因此,多模態分類器 可以表示為(與權重計算相似度後的歸一化輸出):
這裏, 表示余弦相似度, 是溫度參數。
視覺標記生成器是 OVMR 中唯一可訓練的元件,從範例影像中提取類別判別性的視覺資訊,並影響多模態分類器的效能。因此,確保視覺標記盡可能包含類別判別性的視覺細節非常重要。將視覺標記分別輸入語言編碼器以生成基於視覺的分類器 ,然後將基於視覺的分類器與多模態分類器一起進行最佳化。目標影像 在基於視覺和多模態分類器上的預測機率計算為:
視覺標記生成器的整體預訓練目標可以表示為:
其中,表示交叉熵損失,是目標影像的真實標簽。
為了確保視覺標記生成器的泛化能力,論文設計了一種有效的預訓練策略。在每個訓練叠代中,從 ImageNet21k-OVR 中隨機抽取每個類別的K 張影像,這是ImageNet21k 的一個子集。從這些影像中,隨機選擇 張影像作為每個類別的視覺範例,並將剩下的 = - 張影像用作目標影像。範例數目 在範圍 內隨機變化,以模擬實際套用中遇到的多樣情況。重要的是要確保範例和目標影像之間沒有重疊,這可以引導模型學習具有類別區分性特征而不是例項特定細節。此外,在視覺標記生成器的註意力層和每個Transformer 塊中,還采用了諸如註意力路徑隨機dropup 和通道級別dropup 等技術來進一步增強其泛化能力。
Preference-Based Fusion
基於偏好的融合旨在模擬對範例影像進行測試時的驗證結果,以衡量基於文本、基於視覺和多模態分類器的偏好。因此,它根據預測的偏好生成了一個更強大的融合分類器。基於文本的分類器 ,可以透過將文本標記輸入語言編碼器來直接地獲取。
基於偏好的融合過程從對範例影像上不同分類器的驗證開始。類似於公式 4 ,透過將範例特征 (含多個範例影像)輸入到各種分類器中,可以獲得範例影像在不同分類器上的預測機率 、 和 ,分別對應於多模態、基於視覺和基於文本的分類器。然後,基於這些預測機率,可以得到每個類別對不同分類器的偏好:
其中, , , 分別表示基於文本、基於視覺和多模態分類器的偏好。 是範例影像的真實標簽。 表示選擇的評估指標,這裏是開放詞匯分類任務中的 F1 分數,可以透過全面考慮精確度和召回率穩定地反映了分類器的品質。對不同分類器的偏好可以表示為:
其中, 表示 softmax 函式, 是用於生成偏好的溫度參數, 表示在最後一個維度上的連線。
那麽,多模態分類器和單模態分類器的融合分類器可以表示為(僅融合分類器中類別對應的權重):
因此,可以得到目標影像在融合分類器上的最終預測機率 ,如下所示:
基於偏好的融合有效地利用範例影像來提升 VLM 的辨識能力,而不引入任何可訓練的參數。
Adaptation to Open-Vocabulary Detection
論文的方法不僅局限於開放詞匯分類,也可以靈活地適應其他開放詞匯辨識任務,如檢測。在這項工作中,使用基於 CenterNet2 的多階段檢測器,就像Detic 和MM-OVOD 中所做的那樣。為簡單起見,使用該分類器的兩階段變體。用 表示其輸出, 為提議的數量,可以表示為
每個輸入影像 首先被一系列操作依次處理:一個可訓練的影像編碼器 ,一個提議生成器 ,一個感興趣區域( RoI )特征池化模組 ,最終得到一組RoI 特征 。RoI 特征經過邊界框模組處理 以推斷物體位置,得到 。
此外,RoI特征經過分類模組處理,包括線性投影 和多模態分類器 ,得到 RoI 特征的預測機率 ,其中 。
在訓練過程中,多模態、基於視覺和基於文本的分類器保持凍結,而檢測器中的其他元件是可訓練的,透過為每個分類器引入了一個 sigmoid 交叉熵損失反向傳播。在基於偏好的融合中,檢測器以及多模態分類器用於辨識每個範例影像的GT 標簽中最準確的偽框。隨後,使用這些偽註釋計算每個類別的平均精度(AP ),這有助於計算不同分類器的偏好。
Experiments
Datasets
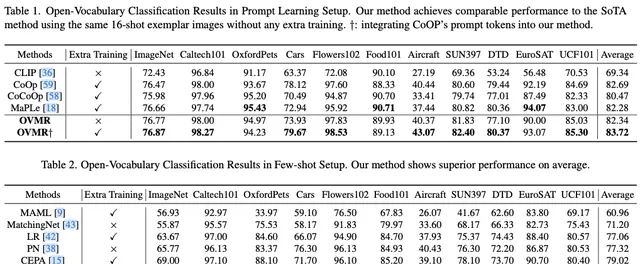
遵循 prompt 學習方法,使用了11 個影像分類數據集,涵蓋了多樣的辨識任務。具體來說,基準包括ImageNet 和Caltecp01 用於一般物件分類;OxfordPets 、StanfordCars (Cars )、Flowers102 、Food101 和FGVCAircraft (Aircraft )用於細粒度分類;SUN397 用於場景辨識;UCF101 用於動作辨識;DTD 用於紋理分類;最後EuroSAT 用於衛星影像辨識。
在開放詞匯檢測中,遵循以往的研究使用了包含 1,203 個類別的100,000 張影像的LVIS 數據集。這些類別根據訓練影像數量分為三組,即頻繁、常見和稀有。將337 個稀有類別視為新穎類別,並使用頻繁和常見類別作為基礎類別進行訓練。當使用影像分類數據作為額外的弱監督時,使用與LVIS 詞匯重疊的ImageNet21k 中的一部份類別子集,並將其表示為IN-L (如Detic )。
根據 ImageNet21k 構建了預訓練數據集。為了防止數據泄漏,從ImageNet21k 中刪除了在11 個分類數據集和LVIS 數據集中都存在的任何重疊類別。此外,限制每個類別的影像數量為64 ,以提高預訓練效率。因此,論文建立了一個名為ImageNet21k-OVR 的64-shot ImageNet21k 子集。該子集包含18,631 個類別,總共包含110 萬張影像,遠小於VLM 預訓練使用的數據集規模。
Implementation Details
根據 prompt 學習方法,選擇了CLIP 的ViT-B /16 作為基礎模型,並預訓練了一個隨插即用的視覺標記生成器,以增強其辨識能力。每個類別的樣本數 設定為8 ,每批次隨機選取192 個類別,總批次大小為1536 。在單個3090 GPU 上使用ImageNet21k-OVR 對視覺標記生成器進行30 輪預訓練,在12 小時內完成。采用Adam 最佳化器和余弦學習率排程器,其中學習率設定為0.0002 。視覺標記數量 設定為2 。偏好融合中的 設定為10 。
該架構和訓練方法幾乎與 Detic 和MM-OVOD 中的相同,使用了CenterNet2 模型,其主幹網路為在ImageNet21k-P 上預訓練的ResNet-50 或Swin-B 。值得註意的是,論文重新實作了Detic 的記憶體高效版本,限制每個影像中實際邊界框的最大數量為10 個,從而能夠在四個24GB 3090 GPU 上復現Detic 在實驗中的結果。基於記憶體高效版本,用論文提出的多模態分類器替換了原始分類器,並進一步引入了基於偏好的融合。此外,為了公平比較,按照以前的工作,在LVIS 基礎類別上為CLIP 的ViT-B /32 預先訓練一個新的視覺標記生成器,並使用ImageNet21k-OVR 進行訓練。在系統級實作中,采用Swin-B 作為主幹網路,並遵循Detic 使用額外帶標簽影像數據(IN-L )對檢測器進行訓練。
在開放詞匯分類中,選擇分類數據集中的前半部份類別作為基礎類別,並對基礎類別進行比較,以公平地與現有方法進行比較。在 prompt 學習設定中,先前方法在推理期間需要利用使用的相同16 張訓練影像作為範例影像。prompt 學習方法需要使用這些16 張訓練影像對每個下遊數據集進行微調,而OVMR 不需要任何額外的訓練。測試集也與prompt 學習方法保持一致。在傳統的少樣本設定中,遵循最近的工作,在相同的16 張範例影像設定下使用CLIP 的視覺編碼器作為基礎模型,並評估不同的少樣本適應演算法,就像prompt 學習方法一樣。在開放詞匯檢測方面,範例影像與MM-OVOD 中相同,即為每個類別提供5 張範例影像。主要評估指標是在「稀有」類別上平均計算得到的mask AP (平均精度),表示為mask AP 。
Comparison with Recent Works

Ablation Study

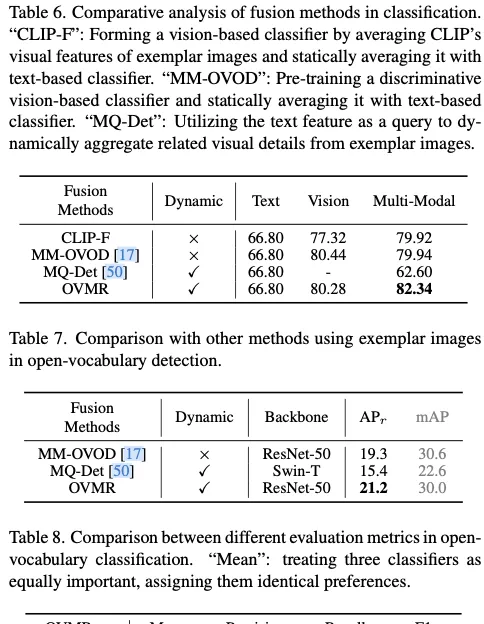
Analysis of Exemplar Images
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關註 微信公眾號【曉飛的演算法工程筆記】
work-life balance.











