Transformer 是一種深度學習模型,由 Ashish Vaswani 等人在 2017 年的論文【Attention Is All You Need】中首次提出。它主要用於處理序列數據,特別是在自然語言處理(NLP)領域取得了巨大成功,例如在機器轉譯、文本摘要、問題回答等任務中表現出色。以下是對 Transformer 模型的關鍵點解釋:
1. 自註意力機制(Self-Attention)

2. 多頭註意力(Multi-Head Attention)
3. 前饋網路(Feed-Forward Networks)
4. 位置編碼(Positional Encoding)
5. 層歸一化(Layer Normalization)
6. 殘留誤差連線(Residual Connections)
7. 訓練和套用
8. 變體和發展
範例程式碼(使用 PyTorch 和 Hugging Face 的 Transformers 庫):
python
import torch from transformers import TransformerModel , BertTokenizer
# 載入預訓練的 Transformer 模型和分詞器
model = TransformerModel . from_pretrained ( 'bert-base-uncased' )
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-uncased' )
# 準備輸入數據
text = "The quick brown fox jumps over the lazy dog" encoded_input = tokenizer ( text , return_tensors = 'pt' )
# 獲取模型的輸出
output = model ( ** encoded_input )
# 輸出的 'last_hidden_state' 包含了序列的最終隱藏狀態
hidden_states = output . last_hidden_state
在這個範例中,我們使用了 Hugging Face 的 Transformers 庫來載入預訓練的 BERT 模型,並對其進行了簡單的文本輸入處理和前向傳播。
Transformer 模型的提出標誌著 NLP 領域的一個重要進展,其自註意力機制和多頭註意力的設計使得模型能夠更好地處理序列數據中的長距離依賴問題。
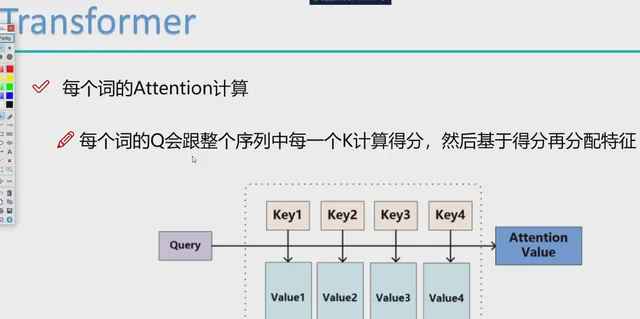
在 Transformer 模型中,"query"(查詢)、"key"(鍵)和 "value"(值)是在自註意力機制中使用的術語,它們是透過以下方式獲得的:
- 輸入嵌入 :
- 首先,模型接收輸入序列(例如,文本句子中的單詞或字元),這些輸入首先被轉換為嵌入表示。這通常涉及到一個可訓練的嵌入矩陣,它將輸入的離散符號(如單詞ID)對映到連續的向量空間。
- 權重矩陣 :
- 輸入嵌入隨後被分別乘以三個不同的權重矩陣,生成查詢(Q)、鍵(K)和值(V)。
- 這些權重矩陣是模型在訓練過程中需要學習的參數。
- 計算註意力得分 :
- 對於序列中的每個元素,模型計算其查詢(Q)與所有鍵(K)的點積,得到一個註意力得分矩陣。這個點積反映了不同元素之間的相似性或相關性。
- 通常,這個得分會透過一個縮放因子(通常是鍵向量維度的平方根)進行縮放,以防止梯度消失或爆炸。
- Softmax 歸一化 :
- 然後,使用 softmax 函式對註意力得分進行歸一化,使得每一行的和為1。這樣,每個元素的輸出都是其對應值(V)的加權和,權重由歸一化的註意力得分決定。
- 多頭註意力 :
- 在多頭註意力中,上述過程被重復多次,但是每個「頭」都有自己的權重矩陣。這樣,每個頭學習到的是輸入數據的不同方面或表示。
- 拼接和線性層 :
- 各個頭的輸出被拼接在一起,並透過另一個線性層進行處理,以產生最終的輸出。
-
範例程式碼(使用 PyTorch):
python
import torch import torch . nn as nn
# 假設輸入嵌入的大小為 embedding_size
embedding_size = 256
# 定義權重矩陣
W_q = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
W_k = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
W_v = nn . Parameter ( torch . randn ( embedding_size , embedding_size ))
# 假設輸入序列的嵌入表示為 embedded_input
embedded_input = torch . randn ( 10 , 32 , embedding_size )
# (序列長度, 批次大小, 嵌入大小) # 計算查詢、鍵和值
Q = torch . matmul ( embedded_input , W_q )
K = torch . matmul ( embedded_input , W_k )
V = torch . matmul ( embedded_input , W_v )
# 計算註意力得分並套用 softmax
attention_scores = torch . matmul ( Q , K . transpose ( - 2 , - 1 )) /
sqrt ( embedding_size )
attention_probs = torch . softmax ( attention_scores , dim =- 1 )
# 計算加權的值
output = torch . matmul ( attention_probs , V )
在這個範例中,我們首先定義了生成查詢、鍵和值的權重矩陣。然後,我們透過矩陣乘法計算了它們,並使用 softmax 函式對註意力得分進行了歸一化。最後,我們計算了加權的值,這代表了自註意力層的輸出。
在實際的 Transformer 模型實作中,這個過程會更加復雜,包括多頭註意力的處理、層歸一化、殘留誤差連線等。但是,上述範例提供了自註意力機制的基本框架。