

資料來源:Ceva
利用 AI 推理並列性的六大路徑
與所有並列性問題一樣,我們首先從定義的 AI 推理目標的資源集開始,這些資源包括一些可用的加速器,具有本地 L1 緩存,共享 L2 緩存和 DDR 介面,每個緩存的緩沖區大小都已定義。接下來的任務是將應用程式要求的網路圖對映到這種結構,最佳化總吞吐量和資源利用。
有一種明顯的策略是處理需要分割成多個瓦片的大輸入影像 – 透過輸入地圖劃分,其中每個引擎被分配一個瓦片。在這裏,多個引擎並列搜尋輸入地圖,尋找相同的特性。相反,您可以透過輸出地圖劃分 – 將同一瓦片並列輸入多個引擎,並使用相同的模型但不同的權重在同一時間檢測輸入影像中的不同特性。
神經網路通常在子圖中進行並列訓練,如下方範例所示。資源分配時通常先最佳化廣度,再最佳化深度,每次都最佳化到當前步驟。顯然,這種方法不一定能在一次傳遞中找到全域最優處理方法,所以演算法必須允許回溯以便探索改進之處。在這個例子中,3 個引擎能夠提供的效能是只有一個引擎提供的效能的 230% 還多。
資料來源:Ceva
上圖中的一些 AI 推理模型或子圖可能顯得很可並列化,也有其他一些 AI 推理模型或子圖的長執行緒操作並不顯得很可並列化,但仍然可以進行流水線處理,這在考慮透過網路執行流操作時可能會有益。另一個例子是深度神經網路 (DNN) 中的逐層處理。簡單地組織每個影像的層操作以最小化每個引擎的上下文切換可以提高吞吐量,同時允許後續的流水線操作稍後但仍然比純順序處理要早地切入。基於轉型器的生成性 AI 網路提供了另一個好例子,註意和規範化步驟的交替使得可以對連續的辨識任務進行流水線處理。
批次分區也是一種方法,支持在多個引擎上執行同一個 AI 推理模型,每個引擎由一個獨立的傳感器「供食」。這可能支持一台監控裝置的多個影像傳感器。並且最後,您也可以透過讓不同的引擎執行不同的模型進行分區。這個策略尤其有用於語意分割,例如,對於自動駕駛而言,部份引擎可能會檢測車道標線。其他引擎可能處理開放(可駕駛)的空間分割,而另一部份可能會檢測物體(行人和其他車輛)。
規劃
在最佳化吞吐量和利用率方面有很多選擇,但是您應該如何決定最佳的 AI 推理套用調優方法呢?這一架構規劃步驟必須在模型編譯和最佳化之前進行。這裏,您需要在分區策略之間做權衡。例如,一個子圖可能先並列,然後進行一系列的操作,有時最好僅透過流水線處理,而不是並列和流水線處理的組合。每種情況下的最佳選擇將取決於圖、緩沖區大小,以及上下文切換中的延遲。
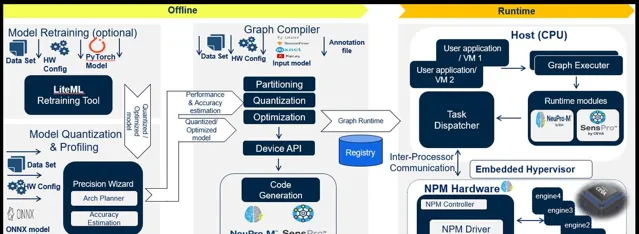
資料來源:Ceva
如果您一直努力研究如何在多核 NPU AI 推理子系統中盡可能好地最佳化您的 AI 工作負載,請檢視我們的 NeuPro-M 平台,並向我們致電,交流有關邊緣具有挑戰性的 AI 推理工作負載的並列性的意見。











