執行大型語言模型 (LLM)(如 ChatGPT 和 Claude)通常涉及將數據發送到 OpenAI 和其他 AI 模型提供商管理的伺服器。雖然這些服務是安全的,但一些企業更願意將數據完全離線,以保護更大的私密。
本文介紹了開發人員可以用來在本地執行和測試 LLM 的六大工具,確保他們的數據永遠不會離開他們的裝置,類似於端到端加密保護私密的方式。

NSDT工具推薦: Three.js AI紋理開發包 - YOLO合成數據生成器 - GLTF/GLB線上編輯 - 3D模型格式線上轉換 - 可編程3D場景編輯器 - REVIT匯出3D模型外掛程式 - 3D模型語意搜尋引擎 - AI模型線上檢視 - Three.js虛擬軸心開發包 - 3D模型線上減面 - STL模型線上切割
0、為什麽要使用本地 LLM?
當使用者使用 LM Studio 等工具執行本地 LLM 時,它不會收集使用者數據或跟蹤使用者的操作。它允許你的所有聊天數據都保留在本地機器上,而無需與 AI/ML 伺服器共享。
根據你的具體用例,可以選擇幾個離線 LLM 應用程式。其中一些工具完全免費用於個人和商業用途。其他可能需要向他們發送商業用途請求。有幾種本地 LLM 工具可用於 Mac、Windows 和 Linux。以下是可以選擇的六種最佳工具。
1、LM Studio
LM Studio 可以執行任何格式為 gguf 的模型檔。它支持來自模型提供商(如 Llama 3.1、Phi 3、Mistral 和 Gemma)的 gguf 檔。要使用 LM Studio,請存取上面的連結並為您的機器下載應用程式。啟動 LM Studio 後,主頁會顯示要下載和測試的頂級 LLM。還有一個搜尋欄,用於過濾和下載來自不同 AI 提供商的特定模型。
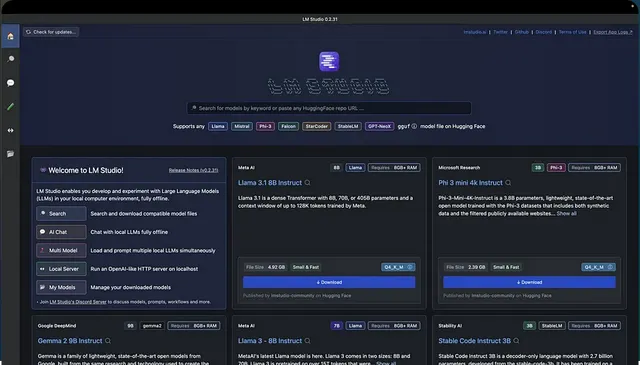
搜尋特定公司的模型會顯示幾種模型,從小到大量化。根據您的機器,LM Studio 使用相容性猜測來突出顯示可在該機器或平台上執行的模型。
1.1 LM Studio 的主要功能
LM Studio 提供與 ChatGPT 類似的功能和特性。它有幾個功能。以下重點介紹了 LM Studio 的主要功能。
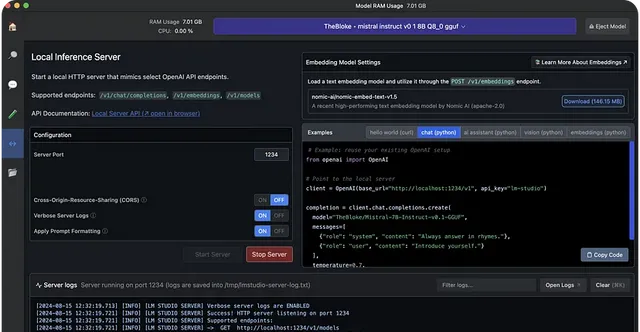
本地伺服器提供範例 Curl 和 Python 客戶端請求。此功能有助於使用 LM Studio 構建 AI 應用程式以存取特定的 LLM。
# Example: reuse your existing OpenAI setupfrom openai import OpenAI# Point to the local serverclient = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")completion = client.chat.completions.create( model="TheBloke/Mistral-7B-Instruct-v0.1-GGUF", messages=[ {"role": "system", "content": "Always answer in rhymes."}, {"role": "user", "content": "Introduce yourself."} ], temperature=0.7,)print(completion.choices[0].message)
使用上述範例 Python 程式碼,你可以重復使用現有的 OpenAI 配置並修改基本 URL 以指向你的本地主機。
1.2 使用 LM Studio 的好處
LM Studio可免費供個人使用,它允許開發人員透過套用內聊天 UI 和遊樂場執行 LLM。它提供了一個帶有過濾器的華麗且易於使用的界面,並支持連線到 OpenAI 的 Python 庫,而無需 API 金鑰。
公司和企業可以根據要求使用 LM Studio。但是,它需要 M1/M2/M3 Mac 或更高版本,或帶有支持 AVX2 處理器的 Windows PC。Intel 和 AMD 使用者只能使用 v0.2.31 中的 Vulkan 推理引擎。
2、Jan
Jan 是 ChatGPT 的開源版本,旨在離線執行。它由一個秉承使用者所有理念的使用者社群構建。Jan 允許你在裝置上執行 Mistral 或 Llama 等流行模型,而無需將其連線到互聯網。使用 Jan,你可以存取 OpenAI 和 Groq 等遠端 API。
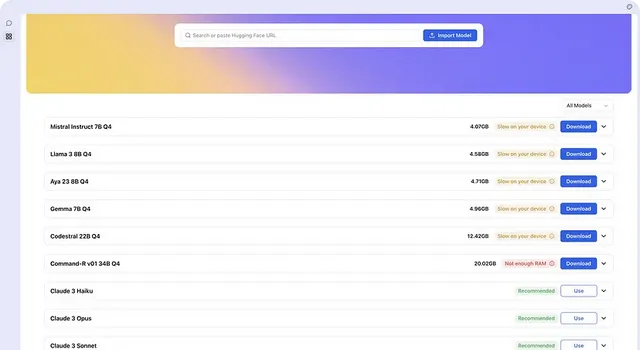
2.1 Jan 的主要功能
Jan 是一款電子應用程式,功能類似於 LM Studio。它透過將消費機器轉變為 AI 電腦,使 AI 開放並可供所有人使用。由於它是一個開源計畫,開發人員可以為其做出貢獻並擴充套件其功能。
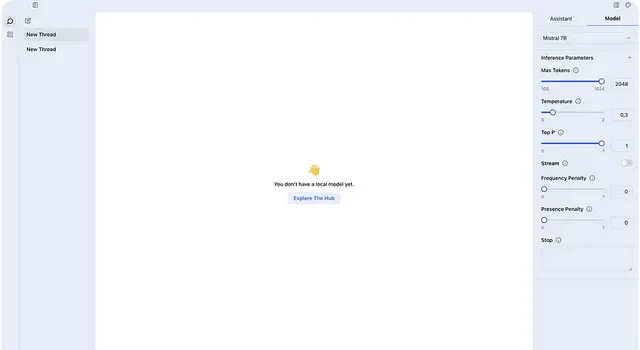
以下細分了 Jan 的主要功能。
2.2 使用 Jan 的好處
Jan 提供了一個幹凈簡單的界面來與 LLM 互動,它將你的所有數據和處理資訊保存在本地。它已經安裝了 70 多個大型語言模型供你使用。這些現成的模型的可用性使得連線和與 OpenAI 和 Mistral 等遠端 API 互動變得容易。Jan 還有一個很棒的 GitHub、Discord 和 Hugging Face 社群可以關註和尋求幫助。
但是,與所有 LLM 工具一樣,這些模型在 Apple Silicon Mac 上的執行速度比在 Intel 上更快。
3、Llamafile
Llamafile 由 Mozilla 支持,其目標是透過快速 CPU 推理(無需網路存取)支持開源 AI,並使每個人都能存取開源 AI。它將 LLM 轉換為多平台可執行連結格式 (ELF)。它允許你僅使用單個可執行檔執行 LLM,從而提供將 AI 整合到應用程式中的最佳選項之一。
3.1 Llamafile 的工作原理
它旨在將權重轉換為多個可執行程式,這些程式無需安裝即可在 Windows、MacOS、Linux、Intel、ARM、FreeBSD 等架構上執行。在底層,Llamafile 使用 tinyBLAST 在 Windows 等作業系統上執行,而無需 SDK。
3.2 Llamafile 的主要功能
存取或制作模型:你可以存取 OpenAI、Mistral、Groq 等流行的 LLM。它還支持從頭開始建立模型。
3.3 開始使用 Llamafile
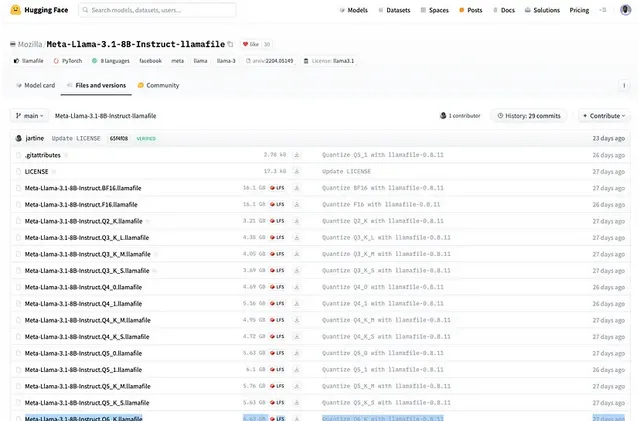
要安裝 Llamafile,請前往 Huggingface 網站,從導航中選擇「模型」,然後搜尋 Llamafile。你也可以從這個 URL 安裝你喜歡的量化版本。
註意:量化數越大,響應越好。如上圖所示,本文使用 Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile,其中 Q6 代表量化數。
步驟 1:下載 Llamafile
從上面的連結中,單擊任意下載按鈕以獲取你喜歡的版本。如果你的機器上安裝了 wget 實用程式,則可以使用以下命令下載 Llamafile。
wget https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/blob/main/Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
你應該將 URL 替換為喜歡的版本。
步驟 2:使 Llamafile 可執行
下載特定版本的 Llamafile 後,你應該使用以下命令透過導航到檔的位置使其可執行。
chmod +x Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
步驟 3:執行 Llamafile
在檔名前面添加句點和斜杠 ./ 以啟動 Llamafile。
./Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
Llamafile 應用程式現在可在 http://127.0.0.1:8080 上執行各種 LLM。
3.4 使用 Llamafile 的好處
Llamafile 透過使 LLM 易於存取消費者 CPU 來幫助實作 AI 和 ML 的民主化。與其他本地 LLM 應用程式(如 Llama.cpp)相比,Llamafile 在遊戲電腦上提供最快的即時處理體驗和更好的效能。由於它具有更快的效能,因此它是總結長文本和大型文件的絕佳選擇。它 100% 離線且私密地執行,因此使用者不會將數據共享給任何 AI 伺服器或 API。
Hugging Face 等機器學習社群支持 Llamafile 格式,因此可以輕松搜尋與 Llamafile 相關的模型。它還有一個很棒的開源社群,可以進一步開發和擴充套件它。
4、GPT4ALL
GPT4ALL 建立在私密、安全和無需互聯網的原則之上。使用者可以在 Mac、Windows 和 Ubuntu 上安裝它。與 Jan 或 LM Studio 相比,GPT4ALL 的每月下載量、GitHub Stars 和活躍使用者更多。
4.1 GPT4ALL 的主要功能
GPT4All 可以在主要的消費硬體上執行 LLM,例如 Mac M 系列芯片、AMD 和 NVIDIA GPU。以下是其主要功能。
4.2 開始使用 GPT4All
要開始使用 GPT4All 在本地執行 LLM,請下載適用於你的作業系統的所需版本。
4.3 使用 GPT4ALL 的好處
除了 Ollama 之外,GPT4ALL 擁有最多的 GitHub 貢獻者,每月活躍使用者約為 250000 名(參考nomic數據)。該應用程式收集有關使用情況分析和聊天共享的匿名使用者數據。但是,使用者可以選擇加入或結束。
使用 GPT4ALL,開發人員可以從其龐大的使用者群、GitHub 和 Discord 社群中受益。
5、Ollama
使用 Ollama,你可以輕松建立本地聊天機器人,而無需連線到 OpenAI 等 API。由於一切都在本地執行,因此無需支付任何訂閱或 API 呼叫費用。
5.1 Ollama 的主要功能
5.2 開始使用 Ollama
首次使用 Ollama 時,請存取 https://ollama.com 並下載適用於您機器的版本。您可以在 Mac、Linux 或 Windows 上安裝它。安裝 Ollama 後,您可以使用以下命令在終端中檢視其詳細資訊。
ollama
要執行特定的 LLM,您應該使用以下命令下載它:
ollama pull <modelname>
其中 <modelname> 是你要安裝的模型的名稱。在 GitHub 上檢視 Ollama 以獲取一些範例模型以供下載。pull 命令也用於更新模型。一旦使用它,只會獲取差異。
下載例如 llama3.1 後,在命令列中執行 ollama run llama3.1 即可啟動該模型。
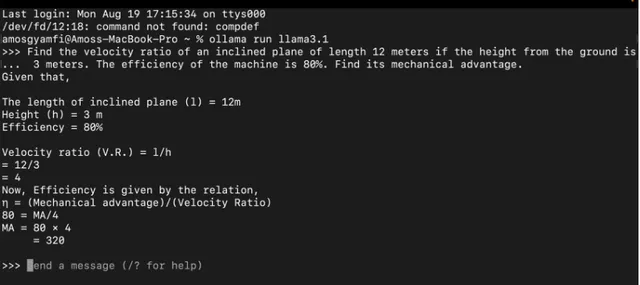
在上面的例子中,我們提示 llama3.1 模型解決物理工作和能量問題。
5.3 使用 Ollama 的好處
Ollama 在 GitHub 上有超過 200 名貢獻者,並且積極更新。在上面討論的其他開源 LLM 工具中,它擁有最多的貢獻者,並且可延伸性更強。
6、LLaMa.cpp
LLaMa.cpp 是底層後端技術(推理引擎),為 Ollama 等本地 LLM 工具提供支持。Llama.cpp 支持大量大型語言模型推理,配置最少,在各種硬體上具有出色的本地效能。它也可以在雲中執行。

6.1 LLaMa.cpp 的主要功能
6.2 開始使用 LLaMa.cpp
要使用 llama.cpp 執行你的第一個本地大型語言模型,應該使用以下命令安裝它:
brew install llama.cpp
接下來,從 Hugging Face 或任何其他來源下載您想要執行的模型。例如,從 Hugging Face 下載Mistral模型並將其保存在你的機器上的某個位置。
使用你喜歡的命令列工具(如終端),進入您剛剛下載的 .gguf 模型檔的位置並執行以下命令:
llama-cli --color \ -m Mistral-7B-Instruct-v0.3.Q4_K_M.ggufb \ -p "Write a short intro about SwiftUI"
總之,您首先呼叫 LLaMa CLI 工具並設定顏色和其他標誌。-m 標誌指定您要使用的模型的路徑。-p 標誌指定您希望用來指示模型的提示。
執行上述命令後,您將在以下預覽中看到結果。
7、本地LLM的典型用例
在本地執行 LLM 可以幫助想要了解其效能及其詳細工作原理的開發人員。本地 LLM 可以查詢私人文件和技術論文,以便有關這些文件的資訊不會離開用於查詢它們的裝置,而流向任何雲 AI API。本地 LLM 在沒有互聯網的地方和網路接收較差的地方很有用。
在遠端醫療環境中,由於私密問題,本地 LLM 可以對患者文件進行排序,而無需將其上傳到任何 AI API 提供商。
在本地使用大型語言模型之前了解其效能對於獲得所需的響應至關重要。有幾種方法可以確定特定 LLM 的效能。以下是幾種方法。
要回答上述問題,你可以檢視 Hugging Face 和 Arxiv.org 等優秀資源。此外,Open LLm Leaderboard 和 LMSYS Chatbot Arena 為各種 LLM 提供了詳細資訊和基準。
8、結束語
正如本文所討論的,選擇和本地使用大型語言模型有多種動機。如果你不希望透過互聯網將數據集發送給 AI API 提供商,您可以微調模型以在遠端醫療應用程式中執行專門的任務。許多開源圖形化使用者介面 (GUI) 本地 LLM 工具(如 LLm Studio 和 Jan)提供了直觀的前端 UI,用於配置和試驗 LLM,而無需像 OpenAI 或 Claude 這樣的基於訂閱的服務。您還發現了各種強大的命令列 LLM 應用程式,如 Ollama 和 LLaMa.cpp,它們可幫助您在本地執行和測試模型,而無需互聯網連線。檢視 Stream 的 AI Chatbot 解決方案,將 AI 聊天整合到您的應用程式中,並存取所有相關連結以了解更多資訊。
原文連結:Top 6大模型本地執行工具 - BimAnt











