編輯:Aeneas 好困
【新智元導讀】 牛津劍橋的9次投毒導致模型崩潰的論文,已經遭到了諸多吐槽:這也能上Nature?學術圈則對此進行了進一步討論,大家的觀點殊途同歸:合成數據被很多人視為靈丹妙藥,但天下沒有免費的午餐。
AI時代,數據就是新的石油。全球人類數據逐漸枯竭的時代,合成數據是我們的未來嗎?
最近Nature封面一篇論文引起的風波,讓我們明白:重要的並不是「合成數據」,而是「正確使用合成數據」。
本周四,牛津、劍橋、帝國理工、多倫多大學等機構的一篇論文登上了Nature封面。
他們提出了AI的「近親繁殖」問題,即如果在訓練中不加區別地只用AI產生的內容,就會發生模型崩潰。

不過,讓人沒想到的是,論文一經刊出便引發了AI社群的大量討論。


一些人認為,問題的核心不在「合成數據」上,而是在「數據品質」上。
即使全部用的是人工數據,如果品質太差,那結果一樣也是「垃圾進垃圾出」。


甚至,有人覺得研究者故意采用了與實際操作不匹配的方法,實際上是在「嘩眾取寵」。

對此,馬毅教授表示,如今我們已經走進了缺少科學思想和方法的時代——
許多研究,不過都是重新發現一些科學常識。

如何避免模型崩潰?
那麽問題來了,在使用AI合成數據時,如何才能避免發生模型崩潰呢?
混合數據才是未來
對於這篇Nature封面的文章,Scale AI的CEO Alexandr Wang深表贊同。
他表示,利用純合成數據來訓練模型,是不會帶來資訊增益的。
通常,當評估指標因「自蒸餾」(self-distillation)而上升時,大機率是因為一些更隱蔽的權衡:
合成數據可以在短期內提升評估結果,但之後你會為模型崩潰付出代價
你在訓練或微調模型過程中積累了隱形的債務,而這些債務將很難償還

具體而言,在連續幾代的合成訓練中,錯誤主要來自三個方面:
統計近似誤差(statistical approximation error)
功能表達誤差(functional expressivity error)
功能近似誤差(functional approximation error)
也就是,每次你用上一個模型生成的數據來訓練新模型時,都會遺失一些資訊和精度,導致模型變得越來越空洞,最終無法正常工作。
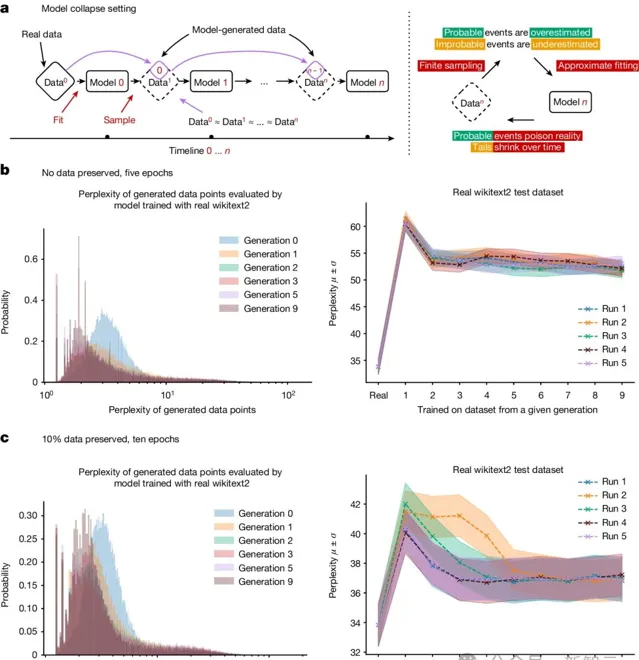
雖然這些實驗是在小規模模型(100M參數)上進行的,但觀察到的基本效應也會隨著時間的推移在更大規模的模型上出現。
例如,今天的大多數模型無法生成像Slate Star Codex風格的部落格文章,這也是由於模型崩潰的原因。隨著我們連續訓練模型,它們逐漸失去了在廣泛分布上進行預測的能力。

在Wang看來,混合數據(Hybrid Data)才是未來的發展方向,它能夠避免所有與模型崩潰相關的棘手問題。
也就是說,在合成數據的過程中,必須透過某種新的資訊來源來生成:
(1)使用真實世界數據作為種子
(2)人類專家參與
(3)形式邏輯引擎
相比之下,那些不慎使用了無資訊增益的合成數據來訓練模型的開發者,終將會發現他們的模型隨著時間的推移變得越來越奇怪和愚蠢。
強化學習is all you need
來自Meta、紐約大學和北京大學的研究人員,提出了一種透過人類或較弱模型的「排序-修剪反饋」方法,可以恢復甚至超越模型原來的效能。
對於這項研究,LeCun也進行了轉發,表示支持。

眾所周知,不管是對於人類還是機器來說,區分一個範例的好壞,要遠比從頭生成一個高品質的樣本容易得多。
基於此,作者提出了一種全新的方法——透過合成數據反饋來防止模型崩潰。

論文地址:https://arxiv.org/abs/2406.07515
為了研究這個問題,作者首先在理論環境中提供了分析結果。
在這裏,作者提出了高維極限下的高斯混合模型和線性模型作為分類器,並讓一個驗證者(例如人類或oracle)來選擇或修剪生成的數據。
結果顯示,當合成數據點的數量趨於無限時,基於選定數據訓練的模型可以達到與原始數據訓練相媲美的最佳結果。
在合成數據上的模擬顯示,與使用原始標註相比,oracle監督始終能產生接近最佳的結果。
此外,由於透過人類監督來分辨高品質數據比直接人類標註更簡單且成本更低,這為人類參與監督的有效性提供了有力的證據。
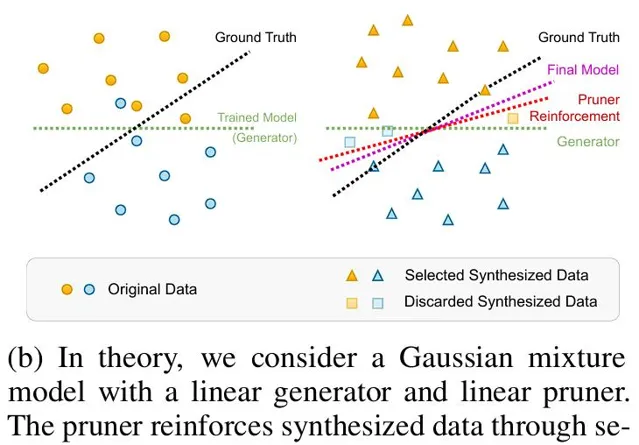
一個具有線性生成器和線性剪枝器的高斯混合模型:其中的剪枝器透過選擇強化合成數據來提高效能
接下來,作者進行了兩個大規模的實驗:
1. 在算術任務(矩陣特征值預測)上訓練Transformer,並使用與真實值的距離來修剪大量合成數據
2. 使用大語言模型(Llama 2)和有限的合成數據進行新聞摘要
結果顯示,在這兩種情況下,僅依賴生成數據會導致效能下降,即使數據量增加,也會出現模型崩潰。
並且,僅根據困惑度從生成池中選擇最佳解決方案並不會提升效能,即模型本身缺乏基於困惑度選擇最佳預測的能力。
相反,在oracle監督下,可以獲得一個基於反饋增強的合成數據集,其效能隨著數據量的增加而超過了原始數據集。
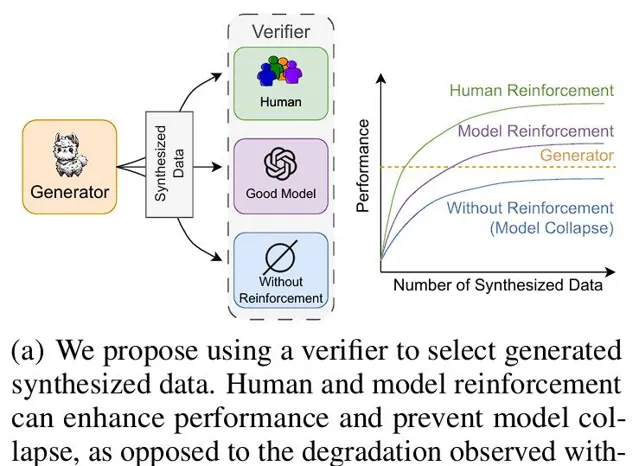
透過人類和模型的強化,可以提升效能並防止模型崩潰;而在沒有強化的情況下則會出現效能下降
因此,在用合成數據訓練新模型時,不僅要關註生成器的品質,還需要一個高品質的驗證者來選擇數據。
一句話總結就是:reinforcement is all you need!
真實數據+合成數據
對於讀者們對於這篇Nature封面論文的吐槽,史丹佛大學的博士生Rylan Schaeffer表示理解。
他指出,模型崩潰通常出現在研究人員故意采用與實際操作不匹配的方法時。
數據積累可以崩潰,也可以不崩潰,這完全取決於具體的操作細節。
你們故意把它弄崩潰,它當然就會崩潰了。 😂

在這篇史丹佛、馬里蘭和MIT等機構合著的論文中,Schaeffer研究了積累數據對模型崩潰有何影響。
經過實驗後他們確認,用每一代的合成數據替換原始的真實數據,確實會導致模型崩潰。
但是,如果將連續幾代的合成數據與原始的真實數據一起積累,可以避免模型崩潰。

論文地址:https://arxiv.org/abs/2404.01413
在實踐中,後代LLM會隨著時間推移,在不斷增加的數據中進行訓練,比如Llama 1需要1.4萬億個token,Llama 2需要2萬億個token,Llama 3需要15萬億個token。
從某種意義上說,這種數據積累設定是極其悲觀的——
在這個假設的未來中,合成數據被不受控制地傾倒在互聯網上,用於訓練模型的下一次叠代。
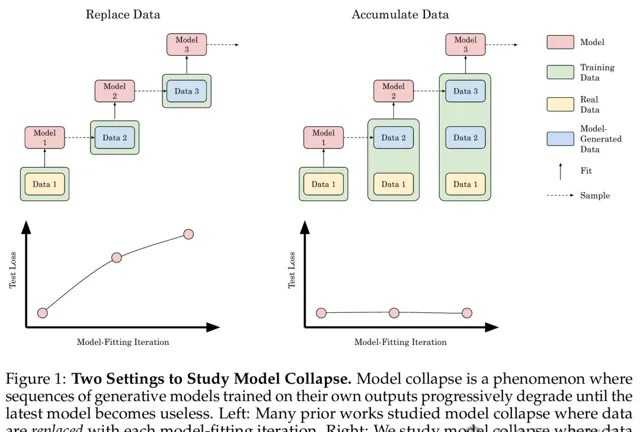
如圖右側所示,積累數據可以避免模型崩潰
研究者使用了因果Transformer、擴散模型和自變分編碼器三種不同的實驗設定,分別在真實文本、分子構象和影像數據集上進行了訓練。
他們發現,替換數據會導致所有模型和所有數據集的模型崩潰,而積累數據可以避免模型崩潰。
基於Tranformer的因果語言建模
首先,他們在文本數據上訓練了因果Transformer。
具體來說,就是在TinyS-tories上預訓練了單個epoch的9M參數GPT-2和 12M、42M和125M參數的Llama 2語言模型。
前者是一個470M token的,GPT-3.5/4生成的幼稚園閱讀水平的短篇故事數據集。
對於每次模型擬合叠代n≥2,研究者會從上一次叠代的語言型中采樣一個與TinvStories大小相同的新數據集,然後用新生成的數據集替換或連線以前的數據集。
在每次模型擬合叠代中,他們會來自上一次叠代的替換或串聯數據集來預訓練一個新的初始化模型。
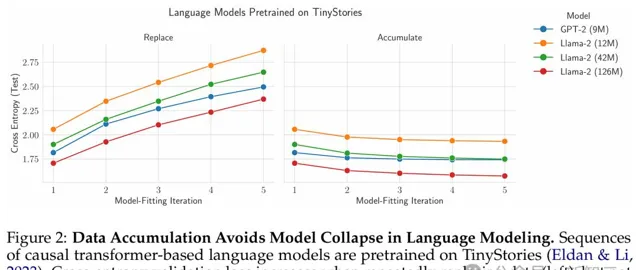
結果顯示,對於所有架構、參數計數和采樣溫度,隨著模型擬合叠代次數的增加,替換數據會導致測試 交叉熵 的增加(圖2左)。
同時他們還發現,對於所有架構、參數計數和采樣溫度,隨著模型擬合叠代次數的增加,積累的數據會導致測試交叉熵等於或更低(圖2右)。
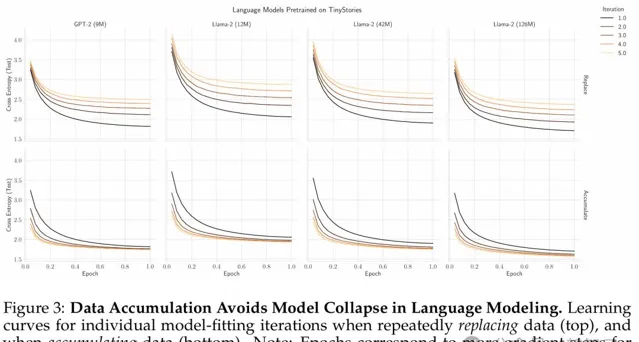
圖3是重復替換數據(頂部)和積累數據(底部)時各個模型擬合叠代的學習曲線。
結果顯示,數據積累避免了語言建模中的模型崩潰。
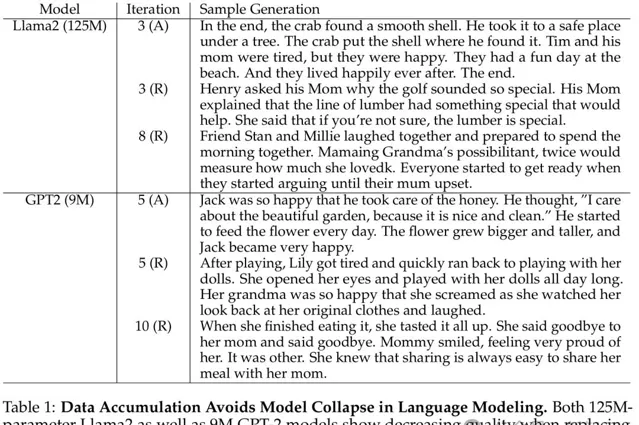
125M的Llama2和9M的GPT-2,在替換數據(R)時都表現出了品質下降,但在積累數據(A)時,卻保持了高品質的文本生成。
分子構象數據的擴散模型
接下來,他們在分子構象數據上訓練擴散模型序列。
具體來說,研究者在GEOMDrugs數據集上訓練了GeoDiff,這是一種用於分子構象生成的幾何擴散模型。
他們將GEOM-Drugs數據集的訓練部份下采樣到40,000個分子構象,將其用作初始訓練集,並為每個預測執行50個擴散步驟。
結果經過8次模型擬合叠代,研究者發現:替換數據時測試損失增加,這與我們的語言模型實驗相匹配,並且累積數據時測試損失保持相對恒定(圖4)。
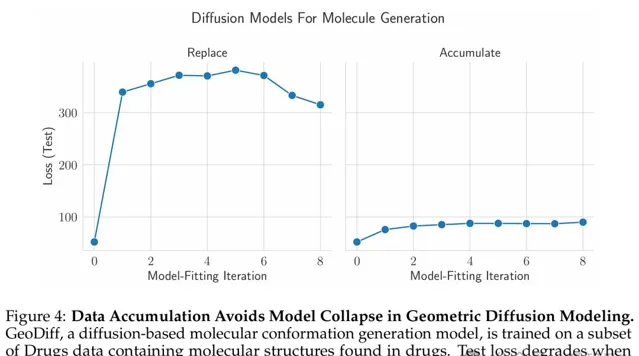
與語言模型不同,他們發現,當替換數據時,在合成數據訓練的第一次模型擬合叠代中,效能會顯著惡化,並且在後續叠代中不會進一步大幅下降。
影像數據的自變分編碼器
實驗最後,研究者在 CelebA 上訓練了自變分編碼器(VAE)序列,該數據集包含了20萬張人臉影像,分為訓練集和測試集。
這種選擇,在具有許多樣本、彩色影像和分辨率的現實數據集,和在累積數據上訓練模型多次叠代的計算可行性之間,達到了平衡。
結果他們發現,在每次叠代中替換數據再次表現出模型崩潰——
測試誤差會隨著每次額外的叠代而迅速上升,並且每次叠代產生的品質較低且生成的面孔多樣性較少,直到所有模型生成都代表單一模式。

相比之下,在每次叠代中,積累數據會顯著減緩模型崩潰——
隨著每次額外的叠代,測試誤差的增加速度顯著減慢。
雖然與圖6的中圖和右圖相比,世代的多樣性確實下降了,它仍然代表數據集中變化的主要軸,例如性別,但模型似乎不再沿著數據流形的更短軸生成其他細節,例如眼鏡和配件。
還有一個有趣的現象是,與語言建模不同,積累數據的測試誤差確實會隨著叠代次數的增加而增加(盡管比替換數據慢得多)。
為什麽會存在這種差異?這個研究方向就留給未來了。
參考資料:
https://x.com/alexandr_wang/status/1816491442069782925 https://x.com/RylanSchaeffer/status/1816535790534701304
https://arxiv.org/abs/2404.01413
https://arxiv.org/abs/2406.07515












