
四足機器人憑借其卓越的穿越崎嶇地形能力和在復雜路面維持穩定的顯著特性,結合先進傳感器套件,已在工業環境中廣泛部署,扮演著自主巡檢的重要角色。然而,盡管它們展現出諸多優勢,
當前大多數四足機器人的運動能力仍局限於高度結構化的地形,面對人造環境中多樣且普遍的基礎設施挑戰,顯得力不從心。
以典型障礙梯子為例。作為工業基礎設施中普遍存在的元素,其卻成為了四足機器人難以逾越的屏障。這一局限性不僅阻礙了四足機器人深入檢查那些可能存在危險的位置,從而迫使人類工作人員涉險作業,增加了安全風險,還直接影響了工業現場的整體作業效率與生產力提升。
據探索前沿科技邊界,傳遞前沿科技成果的X-robot投稿,來自蘇黎世聯邦理工學院機器人系統實驗室的研究人員前不久針對這一挑戰進行深入研究,並透過巧妙地結合基於強化學習的控制策略與創新的互補鉤式末端執行器,成功教會了四足機器人攀登梯子這一新技能。
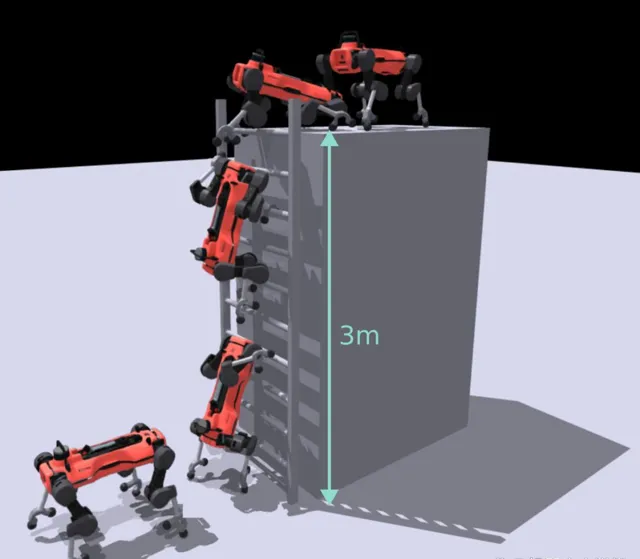
研究人員不僅設計了這一方案,還全面評估了機器人在不同梯子傾斜角度、梯級幾何形態以及梯級間距下的模擬穩健性,確保技術的可靠性。在硬體實驗階段,即便在未經特定訓練的情況下, 機器人也能夠成功攀登角度從70°至90°的梯子,總體成功率高達90%。 同時,在面對未建模的外部擾動時,機器人亦展現出穩定的攀爬效能, 其攀爬速度達到了前所未有的高度,比當前最先進技術快了232倍。
那麽,該研究團隊具體是如何教會四足機器人爬梯子的呢?接下來,一起來和機器人大講堂深入探索這一研究成果!
▍四足機器人爬梯,難度何在?
機器人爬梯技術,作為一個蘊含高度復雜性與挑戰性的研究領域,長久以來一直是科研人員探索的熱點。盡管該領域已取得一定的研究成果,但當前的研究大多聚焦於人形機器人,這類機器人爬梯速度緩慢,且其套用場景受到嚴格限制,通常只能在如完全垂直且無外界幹擾的梯子這類特定結構化環境中運作。
例如, 在某研究中,其具備靈巧雙手及預設運動軌跡的人形機器人攀爬垂直梯子其垂直上升速度僅為26公釐/小時, 且在面對擾動時缺乏魯棒性。而在另一項研究中,即便研究者將運動規劃器與柔順控制器相結合,從而在一定程度上增強了機器人的抗幹擾能力, 但在實際操作中,機器人爬過五個梯級仍需耗時長達七分鐘。

在四足機器人領域,盡管也有爬梯的嘗試,但這些研究同樣多局限於完全垂直的梯子,且爬梯速度同樣不盡如人意,每爬升一個梯級都需要兩分鐘之久。四足機器人在適應各種工業地形時面臨的困境,主要歸咎於其缺乏完成此類復雜任務所需的適當形態或高效控制策略。
仍是以爬梯子為例, 深入剖析四足機器人的爬梯難題,可以發現其背後的幾個關鍵因素: 四足動物的腿部設計,通常采用球形或扁平的腳部結構,這種設計嚴重阻礙了機器人在爬梯過程中產生穩定且可靠的錨定力。此外,爬梯的力學原理要求機器人能夠全身協調,以穩定重心並在較大的傾斜角度下順利向上移動,而這是當前的運動控制器在復雜、未建模或「嘈雜」的環境中難以可靠實作的。再者,梯子的總長、梯級間距、梯級型別、梯級半徑以及傾斜角度等參數可能存在巨大的差異,這就要求控制器必須具備強大的魯棒性和泛化能力。
針對機器人爬梯領域長期存在的這些挑戰,研究團隊成功 開發出了一種用於精確跟蹤位置命令的強化學習(RL)框架, 這一框架極大地提升了機器人攀爬梯子的穩健性。

同時,研究團隊還 設計了一種鉤狀末端執行器,該執行器能夠產生出安全、可靠攀爬所需的關鍵力量。 在此基礎上,研究團隊對成功爬梯進行了跨越多種配置的廣泛模擬測試,這些測試涵蓋了梯子尺寸、梯級間距、梯子傾斜角度、梯子材料參數以及機器人動力學參數等多方面的變化。最終,成功展示了迄今為止速度最快、適用性最廣的機器人爬梯硬體演示,該演示在不同梯子配置以及未建模的擾動條件下均展現出了卓越的效能。
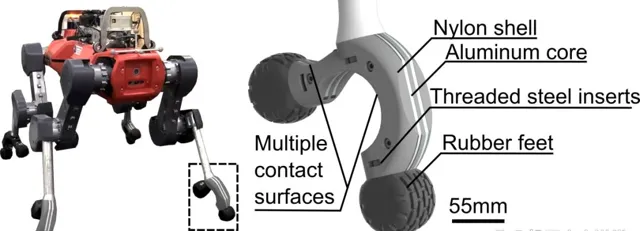
▍控制策略的訓練
四足動物在自然環境中具有出色的移動能力,且基於模型的非線性控制方法在稀疏地形中表現不俗,但這些方法易受建模不確定性、外部幹擾和感知誤差的困擾。相比之下, 無模型的強化學習(RL)方法在實作模擬到現實的遷移、崎嶇地形的穩健性以及解決稀疏地形問題上展現出巨大潛力。 然而,在四足機器人快速、穩健且通用地爬梯方面,研究成果仍相對匱乏。
在本研究中,研究團隊首先為配備掛鉤末端執行器的機器人開發了一個教師策略,該策略在模擬環境中進行訓練,能夠獲取無雜訊的本體感受觀測值、慣性測量單元(IMU)歷史記錄、機器人周圍的高度掃描以及特權狀態資訊。隨後,團隊提煉出一個學生策略,該策略僅能獲取有雜訊的機載觀測值。學生策略以50 Hz的頻率輸出關節位置目標,由真實機器人上以400 Hz頻率執行的PD控制器進行跟蹤。
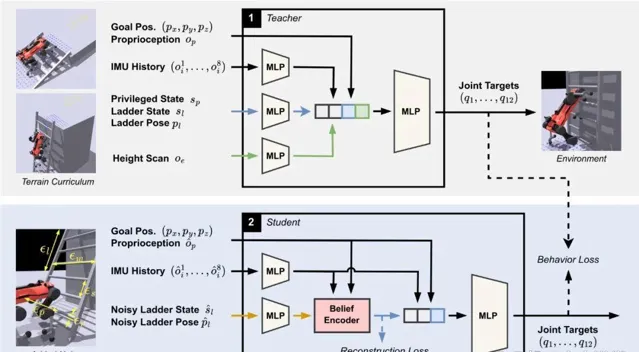
在策略觀測值方面, 本體感受觀測值包括指令目標位置、目標航向、基座框架中的重力方向等,同時還提供IMU測量的歷史記錄。在教師訓練期間,還會輸入機器人周圍的高度掃描,以加速策略訓練。特權狀態資訊則包括身體接觸狀態、腳部的接觸力等。在學生訓練期間,將有雜訊的梯子狀態作為觀測值給出。
教師策略 由四個具有ELU啟用函式的多層感知器(MLP)組成,使用具有自適應約束閾值的IPO進行訓練。訓練地形包括崎嶇地形和具有不同梯子的地形,訓練課程是自適應的,隨著代理達到早期目標,它們會進步到更困難的地形。代理在隨機配置中生成,並被指令到達隨機目標位置和航向。
學生策略 在與教師相同的環境中進行訓練,但僅能存取有雜訊的本體感受觀測值和梯子狀態。學生策略透過復制教師的匹配網路權重進行預熱啟動,並使用行為損失和重建損失進行訓練。特權教師-學生訓練的一個關鍵優勢是,教師可以相對較快地進行訓練,而直接在學生觀測值上進行訓練則難以學習有效且穩健的策略。
所有模擬均在LeggedGym中進行,使用大量並列環境進行訓練。教師訓練15,000個回合,學生訓練5,000個回合,在RTX 3090上訓練總共需要約4.5天。使用掛鉤末端執行器的訓練比使用球足慢約30%,這是由於額外的碰撞體所致。
▍仿真結果/實驗
透過 在不同傾斜角、梯級半徑和存在雜訊及外部幹擾的情況下,對配備掛鉤末端執行器和傳統球足設計的機器人在不同配置的梯子上的表現進行對比, 研究團隊就提出的策略和創新設計進行了評估。
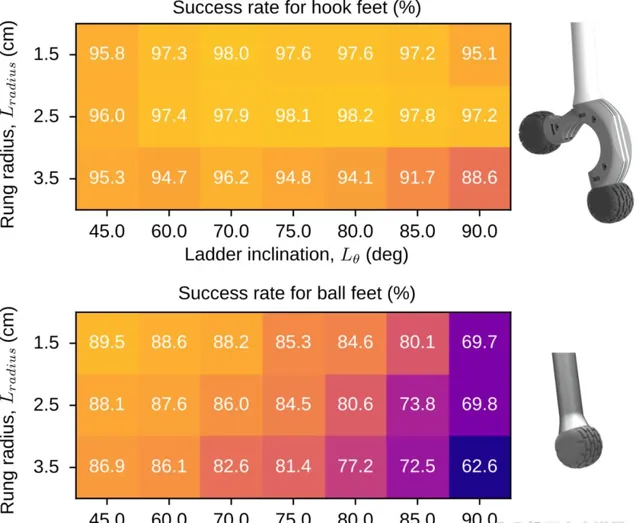
他們隨機選擇了梯子的尺寸和梯級間距,共測試了50種不同配置,並對結果進行了平均。 配備掛鉤末端執行器的機器人在所有測試中的平均成功率高達96%, 即便在添加雜訊和外部幹擾的情況下也能成功攀爬,表現出優異的穩健性。相比之下,傳統球足設計的平均成功率僅為81%。
當梯級半徑減小或傾斜角增延長,兩種設計的效能都會受到影響,但掛鉤末端執行器在提供更穩定性方面表現出明顯優勢。特別是在無雜訊的情況下,掛鉤和球足的成功率都超過了99%,但 掛鉤的設計使機器人能夠在不確定性中更好地泛化,實作平穩且快速的攀爬。
為驗證模擬訓練策略的實際套用效果,研究團隊直接將未經微調的策略部署在ANYmal D機器人上,並在各種傾斜角的梯子上進行了測試。實驗設定包括使用運動捕捉系統估計梯子姿勢和傾斜角,其他梯子狀態則直接測量並作為輸入。
測試結果顯示,機器人在70度和80度傾斜角下均成功攀爬,90度時因未建模的碰撞問題導致部份失敗。模擬與現實之間的數據表現出一致性,且機器人在攀爬過程中的關節位置和環境接觸與模擬相似。 機器人的平均攀爬速度為0.44公尺/秒,比現有最先進的四足機器人快了232倍。 此外,研究團隊還測試了策略對未建模擾動的穩健性,發現機器人能夠從推梯級切換到用掛鉤產生拉力來支撐自己,表現出持續的恢復和重試行為。
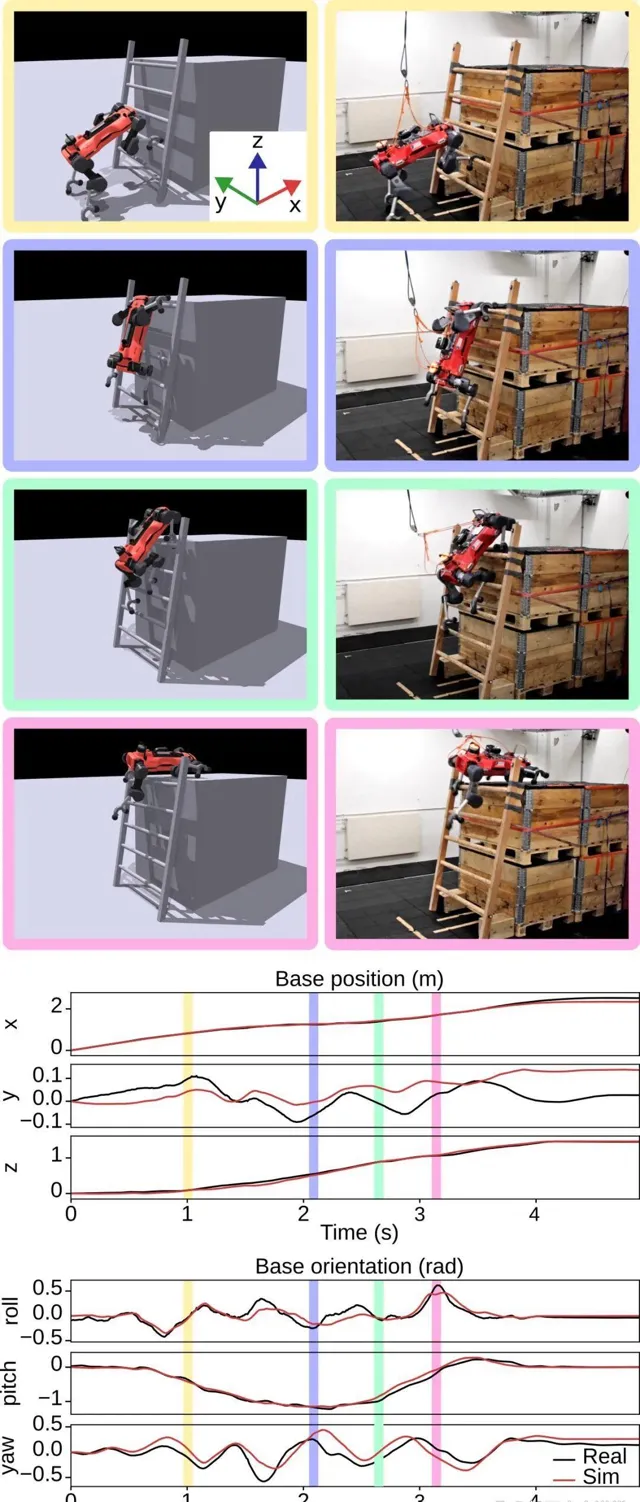
而與人類攀爬梯子的類比則顯示,四足機器人攀爬梯子的動作與人類相似,後腿產生向上的推力,而前腿的掛鉤主要保持穩定。這表明人形和四足機器人在功能形態和控制策略上可能存在統一的描述,並可能共享大部份相同的任務空間。
▍關於X-robot
X-robot是中關村機器人產業創新中心與機器人大講堂聯手打造的權威性資訊釋出品牌專欄,集前沿探索、產業研究、知識普及於一體,致力於積極推動新質生產力的生成與發展,助力中國乃至全球機器人行業的蓬勃繁榮。X-robot立足國際化視野,透過全方位、多角度的挖掘與追蹤,生動展現機器人前沿技術與尖端成果,為學術界、產業界及公眾提供一個洞見未來、共享科技的重要視窗。











