
出品丨虎嗅汽車組
作者丨肖漫
頭圖丨電影【天才槍手】
一次全行業的端到端切換,讓車企們的智駕競賽又回到同一起跑線上。
隨著特斯拉基於端到端路線的 FSD v12.5 版本在北美地區已經取得了令人驚艷的效果,今年以來,國內的玩家從中領悟了智駕升級的「武功秘籍」。(關於端到端的技術原理,虎嗅汽車團隊曾在 【特斯拉,要跟華為開戰了】 一文中有過詳細解析)
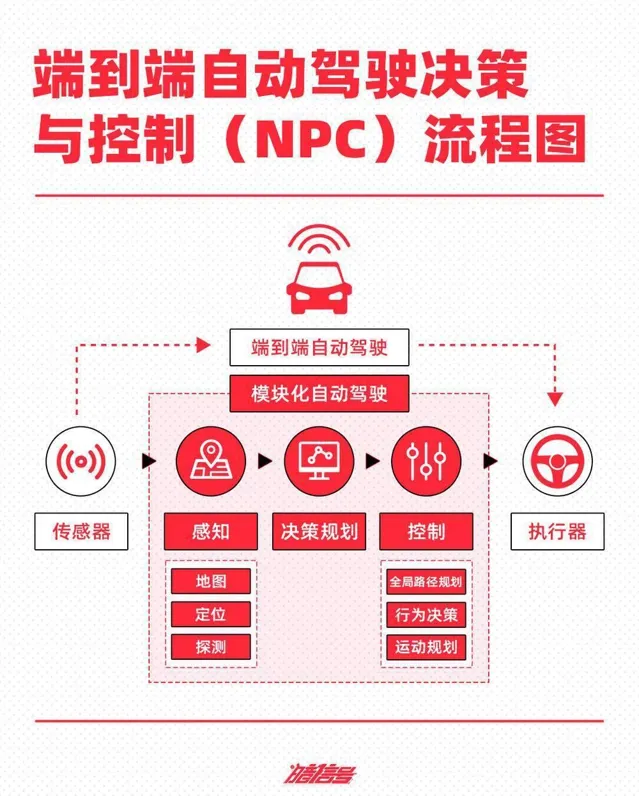
在模組化堆規則時期,程式碼bug修復能力越強,智駕能力表現越好,同時場內玩家透過開城和落地速度也隨之分野。但問題在於,僅憑傳統的智駕規則無法從根本上解決現實世界的理解和推理問題,沒辦法解決許多復雜場景和 Corner case。
因此,「上限不高」的規則時代很快被大模型和端到端的到來取代,尤其是後者近乎「一日千裏」的叠代速度,更是讓一眾車企紛紛其規則轉投端到端技術路徑,這其中便包括蔚小理華等玩家。
端到端已經成為智駕行業下一代共識方案,雖然沒有人能明確端到端是否是自動駕駛的終局方案,但目前沒有比端到端更好的智駕技術方案。
基於此,本期暗訊號旨在梳理目前場內頭部玩家是如何進行「端到端技術路線」布局,透過不同玩家的不同做法和落地進度,窺見車企智駕能力的演進以及接下來智駕行業的競爭錨點。
理想:雙系統協同,「世界模型」外掛
理想其實是端到端路線的激進派。
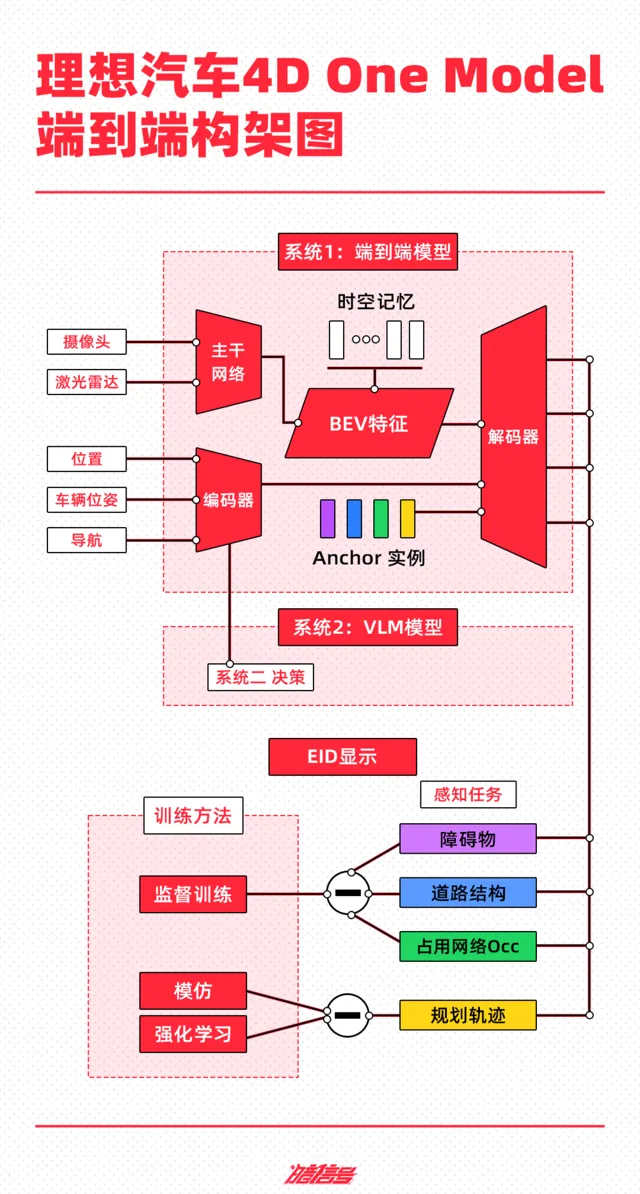
根據理想汽車公開的技術架構,其端到端自動駕駛技術方案分為端到端模型、VLM 視覺語言模型、世界模型三部份。
基於快慢系統理論,理想汽車形成了自動駕駛演算法架構的原型——
系統 1 由 One Model 端到端模型實作,透過接收傳感器輸入,並直接輸出行駛軌跡用於控制車輛;
系統 2 由 VLM 視覺語言模型實作,其接收傳感器輸入後,經過邏輯思考,輸出決策資訊給到系統 1。
雙系統構成的自動駕駛能力將在雲端利用世界模型進行訓練和驗證。
端到端模型的輸入主要由網路攝影機和雷射雷達構成,多傳感器特征經過 CNN 主幹網路的提取、融合,投影至 BEV 空間,疊加車輛狀態資訊和導航資訊,經過 Transformer 模型的編碼,與 BEV 特征共同解碼出動態障礙物、道路結構和通用障礙物,並規劃出行車軌跡。
目前,系統 1 的訓練資料庫已有 3 億多參數,其這一模型在實際駕駛中能夠具備更高的通用障礙物理解能力、超視距導航能力、道路結構理解能力等。
系統 2 的VLM視覺語言模型主要面向的是 5% 的特殊交通場景,如遇到分時段限行、潮汐車道等負責的交通規則理解,相當於副駕坐了個駕校的教練時刻監督駕駛行為,目前已有 22 億參數。
VLM視覺語言模型的工作原理是,將Prompt(提示詞)文本進行Tokenizer(分詞器)編碼,並將前視相機的影像和導航地圖資訊進行視覺資訊編碼,再透過圖文對齊模組進行模態對齊,最終統一進行自回歸推理,輸出對環境的理解、駕駛決策和駕駛軌跡,傳遞給系統1輔助控制車輛。
在實際套用場景中,如果系統二發現行駛過程中地面路面非常坑窪不平時候,其會給系統 1 發一個降速的提醒,並會像ChatGPT一樣告知駕駛員路面資訊,最終輸出駕駛建議,類似「車輛將慢速行駛,以減少顛簸」。
在兩大系統之外,理想利用重建+生成式的世界模型,為自動駕駛系統能力的學習和測試創造了虛擬環境,相當於透過生成真題題庫,讓系統 1、2 在虛擬世界進行考試,以驗證和提高系統能力。
小鵬汽車:「三網融合」
小鵬聲稱是國內第一個量產上車的端到端大模型,但其並非采用「一體化」的「端到端智駕大模型」,而是包括三個部份——神經網路Xnet+規控大模型XPlanner+大語言模型XBrain。
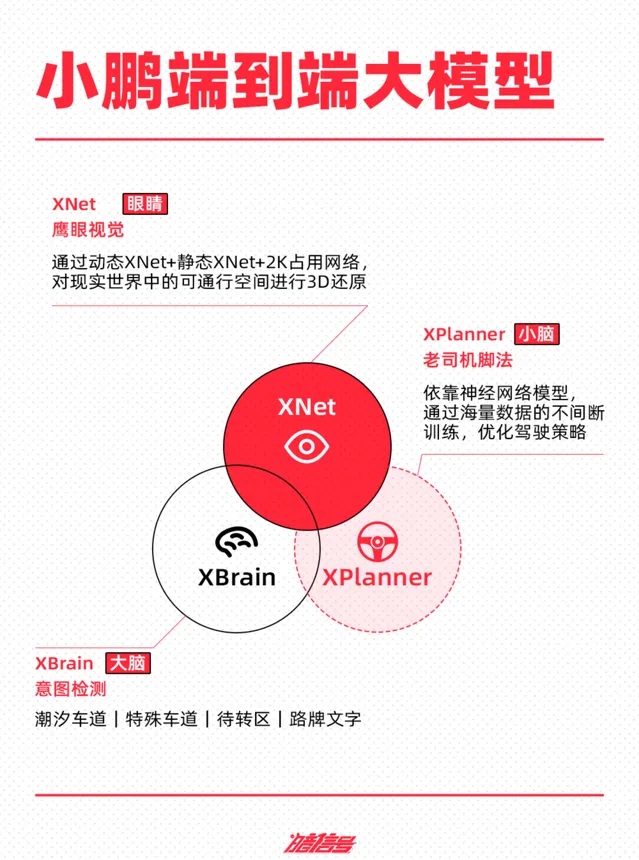
其中,神經網路XNet實作的是「感知」層面的功能,相當於眼睛。
神經網路XNet能將網路攝影機采集到的資訊,透過動態XNet+靜態XNet+2K占用網路,用超過200萬個網格重構世界,對現實世界中的可通行空間進行3D還原,包括動態障礙物(行人、車輛等)、靜態障礙物(水馬、路障等)、路面標識(箭頭、車道線等)等資訊,進行純視覺感知辨識。
據官網數據,其感知範圍面積可達1.8個足球場大小,同時辨識50+個目標物。
基於影像數據的感知輸入,規控大模型XPlanner負責「模組化」智駕路線中的「決策規劃」和「控制執行」功能,類似於小腦。
相比「模組化」智駕路線中的「決策規劃」模組,規控大模型XPlanner的優勢在於不需要人類手寫規則程式碼,完全依靠神經網路模型,透過海量數據的不間斷訓練,最佳化駕駛策略,讓車輛有更類人的駕駛習慣和駕駛思維。
AI大語言模型XBrain充當「大腦」的角色,相當於給了智慧駕駛輔助系統超越感知的「認知能力」。這其實與理想的系統二的功能有相似之處。
XBrain能夠認識待轉區、潮汐車道、特殊車道、路牌文字等路上交通資訊。例如,面對「前方道路施工,請換道」等環境資訊,其能夠看懂並理解從而讓車輛執行對應的操作。
小鵬方面表示,端到端大模型上車後,每2天進行一次叠代,18個月內小鵬智慧駕駛能力將提高 30 倍。
華為:兩網協同,用安全網路兜底
和小鵬一樣,華為的端到端技術架構同樣是分段式——感知部份采用 GOD網路(General Object Detection,通用障礙物辨識),決策規劃采用PDP網路(Prediction-Decision-Planning,預測決策規控)實作。
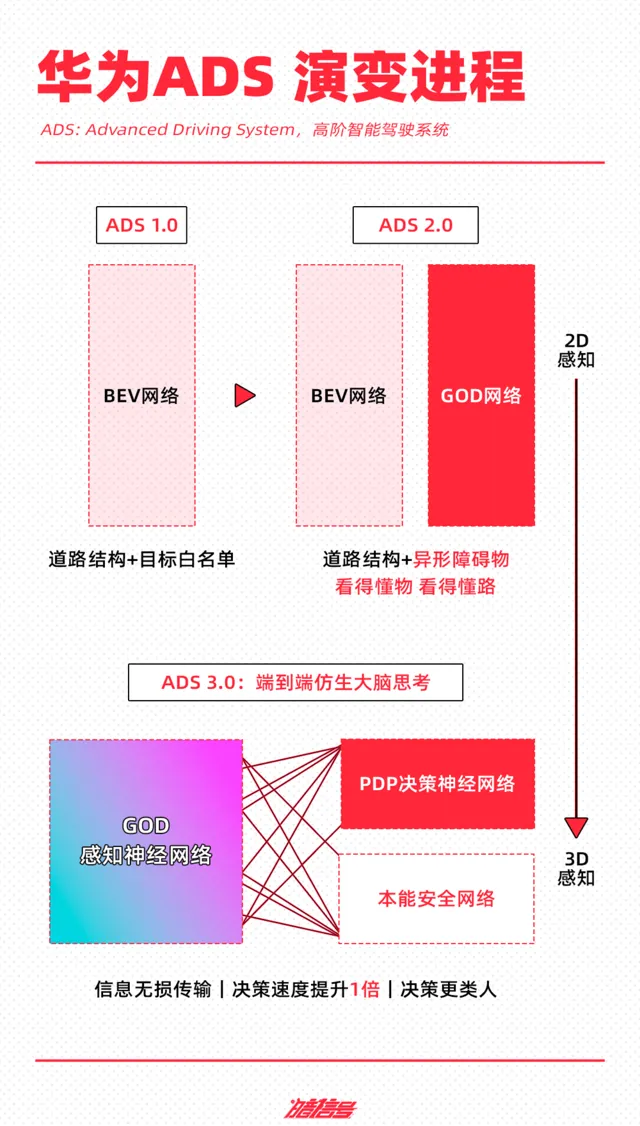
先看感知層面。在華為 ADS 2.0 時期,其采用的是BEV+GOD+RCR網路,BEV負責看到(BEV, Bird's Eye View,視覺為中心的鳥瞰圖),GOD負責「看懂物」(GOD, General Obstacle Detection Network,通用障礙物檢測網路),RCR負責看懂路(RCR,Road Cognition & Reasoning,道路拓撲推理網路),由此實作感知層面的辨識。
不過,這個階段依舊是規則堆疊的階段,如果傳感器辨識的路況資訊是曾經訓練過的特征資訊,則能夠直接輸出給規控一個正確方案,但如果遇到一些未曾訓練好的場景,智駕系統就容易出錯或是不工作。
由此到了 ADS 3.0 階段,華為將 GOD 和 RCR 的演算法納入到一個完整的 GOD 感知神經網路之中,實作了從簡單的「辨識障礙物」到深度的「理解駕駛場景」。
另外,華為采用PDP(預測決策規控)網路實作預決策和規劃一張網,基於感知數據規劃行車路線。
有了GOD+PDP 神經網路模型之後,華為再利用雲端 AI 訓練平台進行大量的數據訓練,讓模型得以叠代升級。
華為同樣認為「讓 AI 去開車」這件事十分激進,目前的人工智慧都會AI幻覺,有30%左右的錯誤率,於是其在端到端模型中加入了「本能網路安全」進行兜底,提供誤踩油門防碰撞功能,路面自適應 AEB,在濕滑路面、雨雪路面可提前舒適制軔等功能。
蔚來:引入NWM世界模型的端到端架構
關於端到端,蔚來沒有公開過這一方面的技術架構。從已有的公開訊息來看,其對端到端的套用目前在主動安全功能層面。
今年7月,蔚來推播了基於端到端演算法實作的AEB系統,透過讓模型學習真實環境下的優秀避險數據,覆蓋更多「不規則」的危險場景,目前已積累了超過20億公裏的事故數據和緊急避險數據。相較於標準AEB,端到端架構的AEB在路口場景方面的緊急制軔正確響應提升了5.2倍。
在蔚來智慧駕駛研發副總裁任少卿看來,自動駕駛的大模型需要拆解成若幹個層級,第一步是模型化,第二步是端到端,去掉不同模組間人為定義的介面,第三步是大模型。
2023年,蔚來在高速NOA的規控裏加入AI神經網路,雖然任少卿曾表示蔚來的端到端智駕方案是將感知模型與規控模型合並,實作資訊無失真傳遞,但在其看來,只是端到端給出規劃路徑還不足夠,智慧駕駛走向大模型化需要具備認知和預測能力,即預判、推演其他交通參與者行為和交通環境的變化。
由此,蔚來在今年 NIO IN 上釋出了蔚來世界模型 NWM——NIO World Model。從蔚來智慧駕駛技術架構NADArch 2.0來看,蔚來已在演算法層升級為引入NWM世界模型的端到端架構。
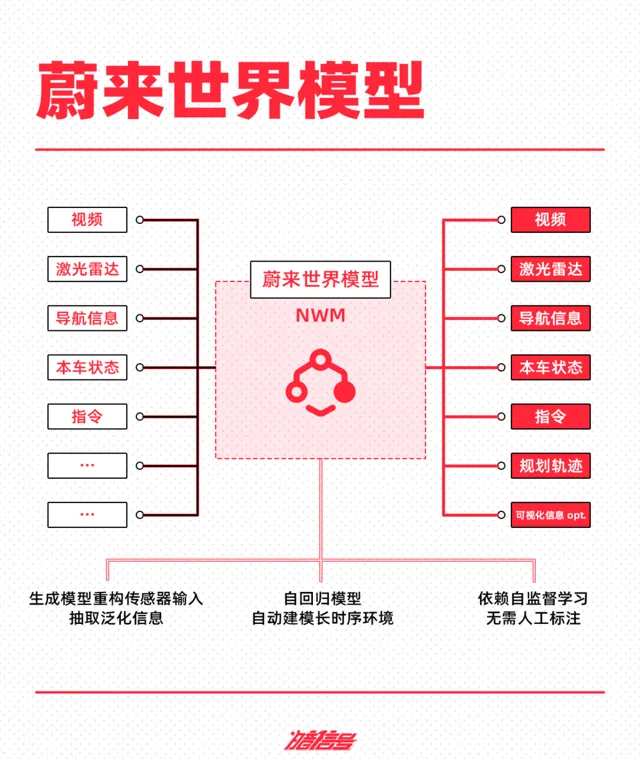
據了解,NWM是一個多元自回歸生成式的具身駕駛模型,可全量理解數據,具備長時序推演和決策能力,能在 100 毫秒內推演出 216 種可能發生的場景。另外,作為生成式模型,NWM 能基於 3 秒的駕駛視訊,生成 120 秒的想象視訊。
目前業內對於世界模型有著不同的套用思考,國內廠商多是把世界模型作為驗證的一環,例如上述提到理想的技術架構中,就引入了世界模型以重建+生產的方式生成模擬數據,作為獨立的架構存在。
雙方對於世界模型在智駕上套用出現分歧的核心因素在於,蔚來看到了世界模型對於智駕推演、預測的可能性和可行性,但理想認為,世界模型能力還不夠成熟,例如在生成上會出現幻覺等。
可以確定的是,將世界模型引入智駕領域是車企們下一步探索的方向。
端到端沒有標準答案
透過頭部自研廠商的技術路徑可以看到,圍繞端到端這一概念,不同廠商設計出不同的技術路線和模型架構,無論是 One Model 的端到端還是分段式的「部份端到端」都有玩家押註。
由於技術仍處在探索階段,目前業內也沒有一個可供參考的實踐案例(特斯拉雖然在北美推播了 V12.5版本,但其端到端網路架構至今還未對外披露),在當前的發展階段,行業內對端到端的路徑還沒有形成共識。
雖然沒有標準答案,但這並不妨礙車企給出各自的解題思路。
當然,空談技術路線並無過多意義,技術的價值在於落地,對於消費者來說,端到端技術的落地,帶來最直觀的感受便是智駕能力的提升。
從部份早鳥使用者的使用感受以及媒體評測視訊來看,搭載端到端的車型能夠適應更多的城市路況,例如能夠在路邊開啟智駕功能、實作環島通行、在遇到障礙物時能夠借道繞行等。
與此同時,端到端帶來的「門到門」體驗也是升級的一部份。諸如小鵬、華為等玩家都已透露將推播能夠暢通ETC、小區入口檔桿、工廠內部道路等場景的智駕版本,實作從家門口到辦公室門口的「門到門」。
另外,人工接管次數也有了明顯的下降。在規則驅動時期,車輛開啟智慧駕駛後,遇到規則以外的突發路況、或是稍微復雜的城市路況時都需要人工接管,但端到端大模型具備更高上限的理解能力和處理能力,能夠有效降低接管次數,更為絲滑地處理不同路況。
當然,端到端目前還只是起步階段,車企也在透過測試、叠代以最佳化其模型效果。可以預見的是,當下的汽車產業正迎來全新的智駕技術競賽。
相較於規則階段,端到端架構需要投入更多資源和資金。優質數據的篩選、清洗、標註、儲存,模型訓練所需的算力基礎設施,部署大模型能力等,無不需要投入。
特斯拉CEO馬斯克就曾強調過數據對端到端的重要性:「用100萬個視訊case訓練,勉強夠用;200萬個,稍好一些;300萬個,就會感到Wow(驚嘆);到了1000萬個,就變得難以置信了。」
何小鵬也曾提到,「自動駕駛有非常大的數據門檻,而且越往後越難成功,頭部效應會越來越明顯。」
數據量是一方面,對國內車企而言,算力訓練也是一大競爭維度。不同於特斯拉能夠大肆采購輝達的顯卡儲備算力,在國內,用於雲端訓練的芯片一卡難求,不少車企都在高價收購。
郎鹹朋就曾在交流中透露,去年年底花了大量資金買卡。據理想汽車初步估算,要從 L2+ 走向L3,甚至是L4階段,起碼需要30 EFLOPS的算力儲備。
從算力層面來看,根據公開資訊,部份廠商的訓練資源如下:
特斯拉 100 EFLOPS(預計 2024 年年末可達到)
華為 5 EFLOPS(2024 年 8 月)
蔚來 1.4 EFLOPS(2023 年 9 月)
理想 4.5 EFLOPS(2024 年 7 月)
小鵬 2.51 EFLOPS(2024 年 7 月)
資源投入背後其實也是關乎資金的戰役。小鵬汽車對外表示在AI訓練上已投入了35億費用,今後每年還將投入超過7億元用於算力訓練。郎鹹朋更是直言沒有10億美元利潤,未來玩不起自動駕駛。
誰家的數據更多,誰家的數據更有價值,誰家的算力更高,叠代效果更好等,都會影響端到端路徑的實際套用表現。這是一場關乎數據量、算力和投入的戰役,車企的智駕能力最終也將走向落地之時實作分野。
對使用者而言,在不久的將來,端到端技術帶來的產業變化和智駕功能升級也將有更為具象化的感知。
正在改變與想要改變世界的人,都在 虎嗅APP











