隨著大型語言模型(LLMs)的快速發展,醫學領域的套用也取得了顯著進展。但是大多數現有的醫學語言模型主要集中在英語語言環境中,限制了其在非英語國家和地區的套用潛力。為了填補這一空白,來自上海交大和上海人工智慧實驗室的研究團隊研發了一個開源的、多語言的醫學語言模型,旨在為全球多語言使用者提供高品質的醫學支持。
這個醫學模型的主要貢獻包括三個方面。研究團隊構建了一個名為MMedC的大規模多語言醫學語料庫,包含約255億個標記,涵蓋六種主要語言。團隊提出了一個名為MMedBench的多語言醫學多選問答基準,用於評估不同語言模型在醫學領域的表現。最後,團隊評估了多種開源大型語言模型,並透過自回歸訓練進一步提升了這些模型在多語言醫學問答任務中的表現,最終模型MMed-Llama 3在多個基準測試中表現優異。
這項研究由上海交通大學和上海人工智慧實驗室的研究團隊共同完成。主要成員包括Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang , Weixiong Lin, Haicheng Wang, Ya Zhang , Yanfeng Wang,Weidi Xie。研究團隊主要致力於人工智慧和自然語言處理領域的研究,特別是在多語言模型和醫學套用方面有著豐富的經驗和顯著的貢獻。他們透過構建大規模多語言語料庫和基準測試,推動了多語言醫學語言模型的發展,為全球醫學研究和臨床實踐提供了重要的技術支持。
他們的技術論文於9 月 27 日發表在【自然】期刊Nature communications上,展示了研究團隊在多語言醫學語言模型構建方面的最新成果。為了促進進一步的研究,團隊公開了MMedC數據集和MMedBench基準數據,未受版權保護的部份已儲存在Hugging Face上,受版權保護的部份提供了詳細列表供研究人員自行獲取。此外,原始碼和模型權重也在GitHub和Hugging Face上公開釋出,方便其他研究人員進行復現和擴充套件研究。
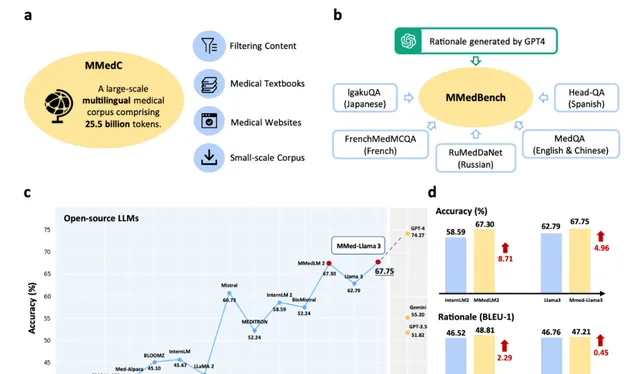
圖 1:貢獻概述。a圖中展示了研究團隊提出的大規模多語言醫學語料庫 (MMedC),包含 255 億個 token,涵蓋六種主要語言,從四個資料來源收集。b圖中展示了研究團隊全面的多語言醫學基準 (MMedBench) 的組成,該基準透過匯總不同語言的醫學問答案例並提示 GPT-4 提供理由句子而構建。MMedBench 能夠在零樣本或微調設定下對不同 LLM 的多選擇準確率和理由生成能力進行評估。c線圖顯示了研究團隊 MMedBench 上各種 LLM 的最終多選擇準確率,其中我們的最終模型 MMed-Llama 3 在所有現有開源 LLM 中表現出色。d比較欄進一步詳細說明了 MMedLM 2 與 InternLM 2 或 MMed-Llama 3 與 Llama 3 進行比較時,多項選擇準確性和推理生成能力的提升。考慮到研究團隊的模型與其基礎模型之間的主要區別在於對 MMedC 的自回歸訓練,這種比較凸顯了研究團隊所貢獻的醫學專用多語言語料庫的重要性。源數據以源數據檔的形式提供。
數據集構建
MMedC多語言醫學語料庫是一個包含約255億個標記的大規模數據集,涵蓋了六種主要語言:英語、中文、日語、法語、俄語和西班牙語。數據來源主要包括四個方面:首先,研究團隊從通用的大規模多語言語料庫中篩選出醫學相關內容,這些語料庫如CommonCrawl,包含了大量的網頁數據。其次,團隊收集了大量的醫學教科書,這些教科書經過嚴格的出版流程,確保了內容的品質。第三,團隊爬取了一些醫學相關的網站,包括醫學百科全書、醫學咨詢平台和醫學新聞網站。最後,團隊還整合了一些現有的小規模多語言醫學語料庫,如Wikipedia、百度百科和UFAL醫學語料庫。
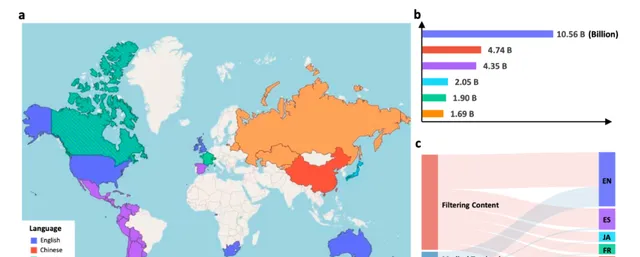
圖2:MMedC統計結果。a MMedC 收錄語言在世界各地的分布(此地圖僅用於演示,與政治無關)。地圖顯示我們收集的語料庫可以覆蓋全球大多數主要國家。b每種語言的 Token 分布。條形圖顯示了不同語言的詳細 token 數量。c四個來源對我們 MMedC 的六種語言的貢獻。桑基圖顯示了四個考慮的資料來源如何對不同語言做出貢獻,即過濾內容、醫學教科書、醫學網站和小規模語料庫。源數據以源數據檔的形式提供。
為了確保數據的品質和相關性,研究團隊采用了一系列數據過濾和處理技術。對於從通用語料庫中篩選醫學相關內容,團隊使用了啟發式演算法,透過關鍵詞匹配和密度計算來確定醫學相關文本。具體來說,團隊為每種語言選擇了200個醫學相關術語,透過關鍵詞匹配和密度計算來篩選出醫學相關的文本。對於醫學教科書,團隊使用了光學字元辨識(OCR)技術,將書籍內容轉換為文本,並排除封面、目錄和附錄等非必要頁面。對於醫學網站,團隊爬取了醫學百科全書、醫學咨詢平台和醫學新聞網站,確保數據的多樣性和時效性。
MMedC語料庫包含約255億個標記,覆蓋六種主要語言:英語、中文、日語、法語、俄語和西班牙語。具體來說,英語數據約為4B個標記,中文數據約為1.1B個標記,俄語數據約為0.4B個標記,法語數據約為0.3B個標記,日語數據約為0.1B個標記,西班牙語數據約為0.05B個標記。透過多種數據來源和嚴格的數據處理技術,MMedC語料庫為多語言醫學語言模型的訓練提供了豐富而高品質的數據支持。
MMedBench是一個綜合的多語言醫學問答基準,旨在評估模型在不同語言醫學領域的表現。研究團隊首先收集了現有的多語言醫學多選問答基準數據集,包括MedQA、IgakuQA、FrenchMedMCQA、RuMedDaNet和Head-QA。這些數據集涵蓋了英語、簡體中文、日語、法語、俄語和西班牙語。為了增強數據集的多樣性和復雜性,團隊使用GPT-4生成了每個問題的解釋,並進行了嚴格的人類驗證,以確保解釋的正確性和邏輯性。
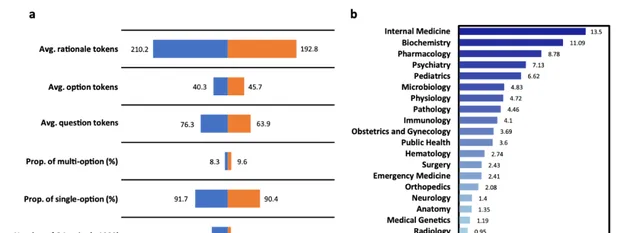
圖3:MMedBench的統計結果。a條形圖顯示了 MMedBench 的訓練和測試集上的基礎統計數位。術語「平均 tokens」表示其中各種成分中每個樣本的平均 token 長度。「Rationale」表示答案中的理由句子。「Option」表示選擇列表中的選項描述,「question」表示問題句子。然後術語「Prop. of multi-option」表示問題中有多個正確選項的比例,「Prop. of single-option」表示答案中只有一個選項的比例。最後術語「Number of QA pair」表示訓練或測試分割中有多少個 QA 對。b統計直方圖顯示了 MMedBench 測試分割中的主題分布,涵蓋了從普通和專科醫學到基礎醫學等廣泛的醫學方面。這使 MedQA 能夠全面衡量醫學模型的效能。源數據以源數據檔的形式提供。
在生成問答對的過程中,研究團隊首先收集了現有的多語言醫學多選問答數據集,並使用GPT-4生成每個問題的解釋。具體來說,團隊將問題、選項和正確答案輸入GPT-4,指示其生成詳細的解釋。生成的解釋隨後經過人工稽核,確保其與正確答案一致,並清晰表達邏輯。為了控制人工稽核的成本,團隊隨機選擇了每種語言的200個測試樣本進行稽核,最終生成了1136個人工稽核的樣本用於解釋評估。
MMedBench數據集包含53,566個問答對,涵蓋21個醫學領域,包括內科、藥理學、精神病學、微生物學、生理學、病理學、免疫學、婦產科、公共衛生、血液學、外科、急診醫學、骨科、神經學、解剖學、醫學遺傳學、放射學、皮膚病學和內分泌學等。數據集分為45,048個訓練對和8,518個測試對,提供了豐富的多語言醫學問答數據,用於評估和訓練多語言醫學語言模型。
模型訓練與評估
自回歸訓練方法
在構建多語言醫學模型的過程中,自回歸訓練方法是關鍵的一環。自回歸訓練的主要目標是透過預測下一個標記來最佳化模型,使其能夠生成連貫且上下文相關的文本。在具體的訓練過程中,研究團隊將醫學文本視為一系列標記,透過最佳化每個標記的預測機率來實作訓練目標。
為了處理大規模的多語言醫學數據,團隊采用了分段處理的方法,將文本分割成每段2048個標記的塊,並設定512個標記的重疊邊界。這種方法不僅提高了訓練效率,還確保了上下文資訊的連貫性。由於模型參數數量龐大,無法在單個GPU上執行,團隊采用了完全分片數據並列(FSDP)策略,將模型分布在多個GPU上進行訓練。此外,團隊還使用了BF16數據型別和梯度檢查點技術,以最佳化記憶體使用和計算效率。
在具體的訓練設定中,對於InternLM模型,團隊設定了全域批次大小為512,學習率為2e-5;對於BLOOM模型,設定了全域批次大小為512,學習率為8e-6。整個訓練過程在八個A100 GPU上進行,訓練了20,000次叠代,耗時約20天。
微調方法
在自回歸訓練之後,團隊進一步對模型進行了微調,以提升其在特定任務上的表現。微調方法主要分為參數高效微調(PEFT)和全量微調兩種。
參數高效微調(PEFT)是一種在低計算資源場景下最佳化模型效能的方法。團隊采用了最具代表性的LoRA方法,僅微調模型的一小部份參數,從而在保持計算資源消耗較低的情況下,顯著提升模型效能。在具體的訓練設定中,團隊使用了預設推薦的rank 16,並采用與全量微調相似的訓練設定。
全量微調則是對模型的所有參數進行微調,是一種更常規的做法。在全量微調過程中,團隊同樣采用了FSDP策略、BF16數據型別和梯度檢查點技術,以最佳化記憶體使用和計算效率。全域批次大小設定為128,學習率為1e-6。
基準測試與結果分析
在多語言問答任務的評估中,研究團隊采用了三種不同的評估設定:零樣本評估、參數高效微調評估和全量微調評估。
在零樣本評估中,團隊直接測試現成的大型語言模型(LLMs),無需進一步訓練。這種方法能夠快速評估模型在未見過的數據上的表現,特別適用於評估模型的泛化能力。然而,零樣本評估的結果顯示,盡管一些閉源模型如GPT-4表現出色,但開源模型在多語言醫學問答任務中的表現相對較差。
為了更好地評估模型之間的效能差異,團隊采用了參數高效微調(PEFT)的方法。透過微調模型的一小部份參數,團隊在低計算資源的情況下顯著提升了模型效能。LoRA方法在這方面表現尤為突出,使得模型在多語言問答任務中的表現得到了顯著提升。
全量微調是對模型的所有參數進行微調,這是一種更常規的做法。透過全量微調,團隊能夠最大程度地最佳化模型在特定任務上的表現。結果顯示,經過全量微調的模型在多語言問答任務中的表現顯著優於零樣本和參數高效微調的模型,特別是MMed-Llama 3在多語言和英語基準上的表現尤為突出。
在生成解釋能力的評估中,研究團隊采用了多種自動化評估指標和人工評分標準,以全面衡量模型的表現。
團隊使用了BLEU、ROUGE和BERT-score等經典的文本相似度評估方法。BLEU主要關註n-gram的精確度,ROUGE則結合了召回率和精確度,而BERT-score利用預訓練的BERT模型提取高層語意特征,透過余弦相似度計算文本相似度。這些指標能夠量化模型生成的解釋與參考解釋之間的相似度,從而評估模型的解釋生成能力。
為了進一步評估模型的解釋生成能力,團隊還進行了人工評分。評估標準包括準確性、推理能力和內部知識的整合能力。透過對六個代表性模型的50個樣本進行評分,結果顯示,MMed-Llama 3在人工評分和GPT-4評分中均取得最高分,表現優於其他模型。這表明MMed-Llama 3不僅在多語言問答任務中表現出色,其生成的解釋也具有較高的品質和邏輯性。

圖4:模型評級的比較分析。a分數條表示不同指標下的排名分數。BLEU 評分表示根據 BLEU 分數排名計算出的評分分數。人工評分是指人工提供的排名,而 GPT-4 評分是指 GPT-4 生成的排名。b擬合線表示人工評分結果與不同自動指標之間的相關性。τ是 Kendall 秩相關系數,而k是擬合線的斜率。源數據以源數據檔的形式提供。
在英語基準測試中,研究團隊使用了四個廣泛認可的多選問答基準數據集,以評估模型在英語醫學領域的表現。
團隊選擇了MedQA、PubMedQA、MedMCQA和MMLU-Medicine四個數據集。MedQA基於USMLE考試,PubMedQA基於PubMed摘要,MedMCQA包含大量高品質的醫學問題,MMLU-Medicine則涵蓋多個醫學學科。這些數據集提供了豐富的測試樣本,用於全面評估模型在英語醫學問答任務中的表現。
結果顯示,MMed-Llama 3在這些英語基準測試中表現出色,特別是在MedQA、MedMCQA和PubMedQA數據集上取得了顯著的效能提升。相比其他開源模型,MMed-Llama 3在多項指標上均表現優異,甚至在某些任務上接近或超過了GPT-4的表現。
研究影響與套用前景
多語言醫學語言模型的構建對通用醫學人工智慧(GMAI)的發展具有重要意義。GMAI致力於開發能夠直接套用於廣泛醫療場景的多模態人工智慧模型,其中大型語言模型(LLMs)常作為人機互動的介面。透過引入多語言支持,醫學多語言模型能夠充分利用全球範圍內的資料來源,擴充套件可用的多模態訓練數據,從而提高其他模態的表示品質。這不僅有助於提升模型的整體效能,還能促進醫學人工智慧在全球範圍內的套用和普及。
現有的LLMs在醫學領域的一個主要問題是幻覺,即生成的內容可能包含事實錯誤。為了解決這一問題,檢索增強生成技術被提出,透過從外部知識庫中檢索事實資訊,來減少生成內容中的錯誤。然而,目前大多數檢索增強生成技術主要集中在英語語言環境中,限制了其在其他語言中的套用。多語言醫學語言模型的開發可以顯著改善檢索過程,豐富潛在的知識庫,從而提高生成內容的準確性和可靠性。這對於醫學領域尤為重要,因為準確的醫學資訊對於診斷和治療至關重要。
多語言醫學語言模型在臨床實踐中有著廣泛的套用前景。首先,它們可以緩解語言障礙。在許多醫療系統中,患者和醫療提供者之間的語言障礙可能導致溝通不暢、誤診和治療不當。多語言醫學語言模型可以實作即時轉譯和解釋,確保患者能夠有效地表達癥狀並理解診斷和治療方案,從而提高醫療服務的品質和效率。
此外,多語言醫學語言模型還可以減少文化和法律敏感性。不同國家和地區在醫療互動中存在文化和法律差異,理解這些差異可以顯著增強對醫學語言模型的信任,進而改善健康結果。透過訓練模型辨識和處理這些文化和法律差異,可以提高模型在不同文化背景下的適用性和可靠性。
多語言醫學語言模型在醫學教育中也有著重要的套用價值。特別是在醫學教育資源匱乏的地區,這些模型可以提供多語言的教育材料和模擬,幫助標準化醫學培訓,確保全球範圍內醫療服務的一致性和品質。透過提供高品質的教育資源,多語言醫學語言模型可以幫助培養更多合格的醫療專業人員,提升全球醫療水平。
潛在局限性與未來工作
盡管MMedC多語言醫學語料庫在數據收集和處理方面進行了嚴格的篩選和過濾,但由於數據主要來源於網路爬取,難免會存在一些固有的偏見。這些偏見可能會對某些弱勢群體產生不利影響,特別是在醫學領域,這種偏見可能會導致診斷和治療建議的不準確。未來的研究需要進一步探索更嚴格和全面的安全控制措施,以減少數據集中的潛在偏見,確保模型在不同人群中的公平性和可靠性。
雖然研究團隊在模型中引入了生成解釋的能力,以幫助使用者理解模型的決策過程,但目前的解釋性仍然存在一定的局限性。現有的解釋生成方法主要依賴於模型生成的文本,這些文本可能無法完全反映模型內部的決策邏輯。此外,如何在復雜的醫學場景中提供清晰、準確且易於理解的解釋,仍然是一個亟待解決的問題。未來的研究需要進一步探索和開發更具解釋性的模型架構,如結合摺積塊或多層感知器(MLP)的解釋性方法,以增強模型的透明度和可解釋性。
MMedC語料庫涵蓋了六種主要語言,但仍然無法覆蓋全球所有語言。這限制了模型在某些語言環境中的套用,特別是在一些低資源語言的醫學場景中。未來的研究應致力於擴充套件數據集的語言覆蓋面,納入更多如德語和阿拉伯語等語言。此外,透過定義特定的過濾關鍵詞,可以從通用爬取數據集中高效提取醫學相關內容,進一步豐富低資源語言的數據集。
未來的研究可以從以下幾個方面進行改進和擴充套件。
擴充套件數據集的語言覆蓋面:透過引入更多語言的數據,特別是低資源語言的數據,進一步提升模型的多語言能力和適用性。
增強模型的解釋性:開發更具解釋性的模型架構,結合摺積塊或多層感知器(MLP)的解釋性方法,以提高模型的透明度和使用者信任度。
減少數據集的潛在偏見:探索更嚴格和全面的安全控制措施,減少數據集中的潛在偏見,確保模型在不同人群中的公平性和可靠性。
結合檢索增強生成技術:透過引入檢索增強生成技術,利用外部知識庫中的事實資訊,減少模型生成內容中的錯誤,提高生成內容的準確性和可靠性。
提升模型的臨床套用能力:透過進一步最佳化模型的訓練和微調方法,提升模型在臨床實踐中的套用能力,特別是在即時轉譯、解釋和醫學教育等方面。
透過這些改進和擴充套件,未來的多語言醫學語言模型將能夠更好地服務於全球醫療領域,推動醫學人工智慧的發展,為全球醫療服務的提升做出更大的貢獻。
多語言醫學語言模型的構建不僅推動了通用醫學人工智慧的發展,還改進了檢索增強生成技術,並在臨床實踐和醫學教育中展現了廣泛的套用前景。這項研究不僅展示了多語言醫學語言模型的潛力,也為未來的研究和套用提供了寶貴的經驗和參考。(END)
參考資料:https://www.nature.com/articles/s41467-024-52417-z

波動世界(PoppleWorld)是噬元獸數位容器的一款AI套用,是由AI技術驅動的幫助使用者進行情緒管理的工具和傳遞情緒價值的社交產品,基於意識科學和情緒價值的理論基礎。波動世界將人的意識和情緒作為研究和套用的物件,探索人的意識機制和特征,培養人的意識技能和習慣,滿足人的意識體驗和意義,提高人的自我意識、自我管理、自我調節、自我表達和自我實作的能力,讓人獲得真正的自由快樂和內在的力量。波動世界將建立一個指導我們的情緒和反應的價值體系。這是一款針對普通人的基於人類認知和行為模式的情感管理Dapp應用程式。











