歷史學和考古學的目的,是重現已消逝的生活。而歷史文本,則是心理學家眼中的「遺跡」和「化石」。
北京大學歷史系博士生、美國哈佛大學定量社會科學研究所聯合培養博士生陳鈺琪和合作者,則希望利用 AI 模型在大規模的歷史文本中測量那些已逝去的心靈。

圖 | 陳鈺琪(來源:陳鈺琪)
長期以來,文化心理學家對人類的歷史一直抱有強烈的興趣,因為文化和心理的演進並非一蹴而就,而是在漫長的歷史時段中形成的。他們的思想與行為是由社會塑造的,而社會是由歷史塑造的。
然而,問卷調查等科學實驗方法在面對已逝去的心靈時沒有用武之地,研究者們因歷史無法重現而束手無策。
而自然語言處理(NLP,Natural Language Processing)與文本定量分析方法的不斷更新,為相關研究帶來了越來越多的可能。
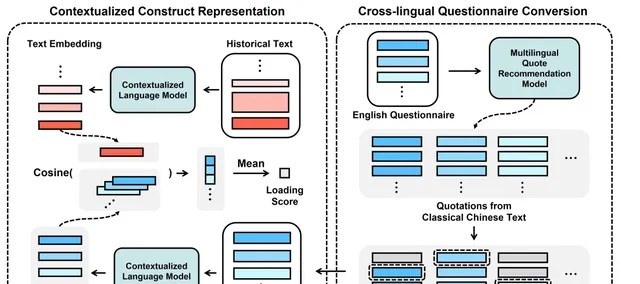
基於此,陳鈺琪等人開發了一種名為「情境化構念表征」(CCR,Contextualized Construct Representation)的框架,以用於測量帶有上下文情境的歷史文本中的心理構念,如集體主義、傳統主義、社會規範強度等。
(來源:arXiv)
CCR 方法的基本原理是利用 Transformer 模型,同時輔以心理學量表與待測量文本的文本嵌入,並透過相似度計算得到待測量文本在該量表主題下的「載荷分數」。
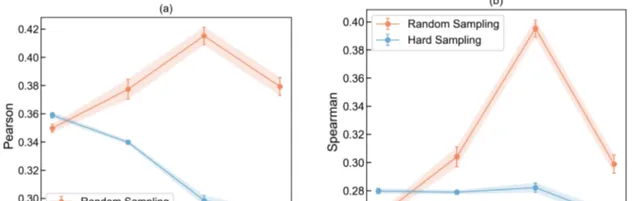
透過在專門測試集上執行語意文本相似度、量表分類和心理測量等任務,陳鈺琪和合作者針對 CCR 方法、過去心理學界主流采用的「分布式詞典表征」(DDR,Distributed Dictionary Representation)方法、基於生成式大模型的小樣本提示方法這三種方法,在不同模型上的表現進行了比較。
(來源:arXiv)
透過使用微調之後的模型,他們發現 CCR 方法在所有任務上的表現,均超過了傳統的 DDR 方法,並在大部份任務上也超過了使用 GPT-4(gpt-4-turbo-0125-preview 版本)的小樣本提示方法。
(來源:arXiv)
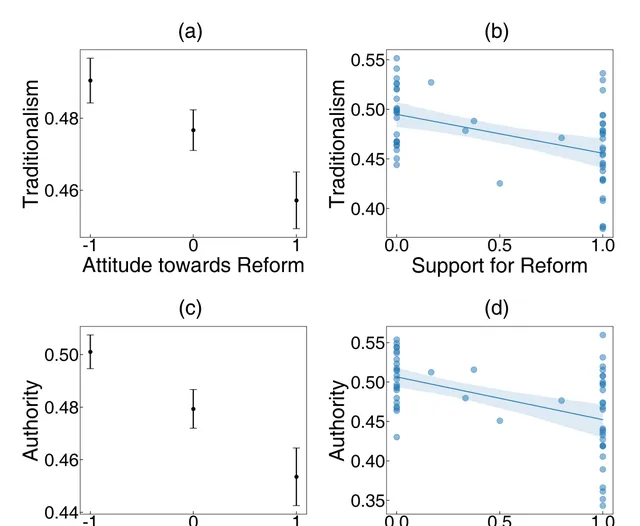
此外,他們也在由人工標註的真實歷史數據集上,驗證了 CCR 方法的可靠性。比如,透過 CCR 方法測量北宋時期不同官員所撰寫文章中傳統主義的心理指標分數,可以有效推測該官員是否在王安石新政中支持變法。
總的來說,該方法可以幫助心理學家、歷史學家以及任何對古代文化演變感興趣的研究人員,在相對較低的計算資源耗費下,針對不同的心理學構念或文化主題,對古代歷史文本進行大規模的測量和分析,進而驗證假說,揭示現代文化現象的歷史根源。
研究中,他們面臨的第一個問題是,受到廣泛認可的心理學量表絕大多數是英文的,因此需要先將英文量表與中國古代文言文進行對齊,才能進行下一步測量。
直接將英文轉譯為文言文可能是不妥當的,因為在相關語境差異巨大的情況下,很多詞匯難以找到合適的表達,由人工生造的句子往往顯得生硬。
為了解決這個問題,他們采用了清華大學孫茂松教授課題組之前的方法,使用多語言的引文推薦模型,將與量表中的英文句子語意相似度高的文言文引文放入備選池。
並進一步透過手工篩選去除噪音,得到與英文量表對應的文言文量表。這些引文均來自於實際歷史文本,而非轉譯或人工生成,因此自然而然地符合文言文的語境。
接下來的第二個問題是,要從中國古代歷史文本得到準確的文本嵌入需要合適的模型。目前,已有許多在文言文語料上預訓練的 Transformer 模型,但沒有針對語意相似度或心理測量這一特殊下遊任務的模型。
針對語意相似度等任務進行訓練的中文文本嵌入模型,則往往基於現代語料和數據集,因此並不適應於專門的心理測量任務。
而他們所需要的文本嵌入模型,要能夠對文言文、尤其是文言文中的心理構念及其上下文情境進行準確的表征,只有這樣才能勝任從道德價值判斷的角度進行語意相似度計算的任務。
(來源:arXiv)
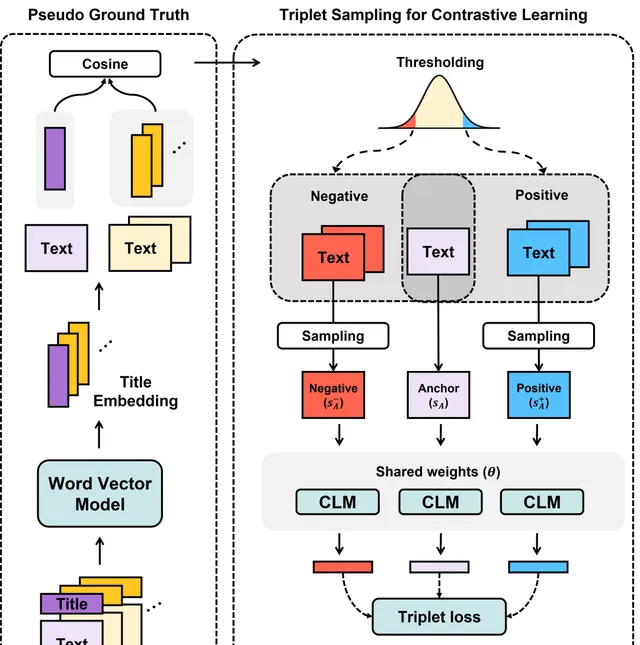
為了解決這一問題,他們提出一種基於間接監督和對比學習的訓練方法。
由於相關領域數據的缺乏,他們透過手工搜集的方式,構建了第一個中文歷史心理學語料庫(C-HI-PSY,Chinese Historical Psychology Corpus),該語料庫包括 667 個與心理或道德相關主題下的 21539 條文言文段落。
然後,他們透過在更大規模文言文語料上訓練的詞向量模型,獲取了不同主題的詞向量表示,借此計算不同主題詞向量之間的相似度,並將之作為不同主題所對應文本之間心理語意層面相似度的偽真值。
後又透過隨機采樣或困難采樣等不同的采樣方式,為 C-HI-PSY 訓練集中的每一個段落,采集 n 個相似度偽真值高的正樣本、以及相似度偽真值低的負樣本,借此構成 anchor-positive-negative 三元組,從而利用三元組損失函式對模型進行微調。
接著,他們在多個針對文言文或中文的 Transformer 模型上,根據不同的超參陣列合進行實驗,在 C-HI-PSY 驗證集和測試集上分別進行語意相似度任務的評估。結果發現,所有模型在微調後的表現都有顯著提高。
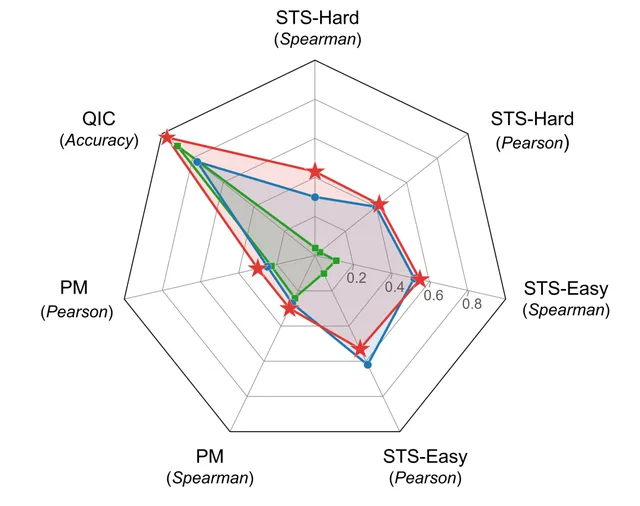
(來源:arXiv)
最終,相關論文以【審視死去的心靈:文言文語境化構念表征的歷史心理文本分析】(Surveying the Dead Minds: Historical-Psychological Text Analysis with Contextualized Construct Representation (CCR) for classical Chinese )為題發在 arXiv [1]。
陳鈺琪是第一作者,小蠅科技 AI Lab 研究員李思璇是第二作者,北京大學計算物理博士生黎穎是第三作者,美國麻薩諸塞大學阿默斯特分校心理與腦科學系助理教授穆罕默德·阿塔利(Mohammad Atari)擔任通訊作者。

圖 | 相關論文(來源:arXiv)
陳鈺琪表示:「多元化的背景是他們得以完成這樣跨學科的研究工作的重要因素之一。」
論文的前三位作者均為女性,在合作過程中大家的關系非常融洽。陳鈺琪說:「我們相信女性的力量,也相信女性的細膩、耐心的特質會為研究增色。
比如,第三作者黎穎曾參加過微軟亞洲研究院舉辦的面向女生的 Ada Workshop,接觸到了科技領域很多令人敬佩的女性榜樣,這讓她很受鼓舞。」
透過使用 CCR 方法,他們與哈佛大學團隊合作,在上萬本古籍中首次測量了集體主義、個人主義、忠誠、榮譽等十幾個作為文化心理和道德基礎的指標,在跨越數千年的中國歷史上的歷時演變及其空間分布,借此嘗試揭示東西方文化心理差異的根源。相關文章也即將釋出預印本。
另據悉,陳鈺琪本碩博階段均在北大歷史學系接受最傳統的人文學科訓練。對她來說,跨界研究 AI 模型原本是難以想象的事情。
博士階段,因研究面臨浩如煙海的考古材料,她開始尋找大規模分析的方法,由此接觸到量化研究和數位人文領域,新世界的大門開始對她開啟。
起初她也曾有過較為漫長的艱難探索階段,從最基礎的線性代數開始補習數學,透過 Coursera 學習編程,從參與數據標註到獨立設計資料庫,從呼叫模型到訓練模型,種種曲折,不一而足。
「期間受到了很多人的幫助,也非常感激我的博士導師在對待我的‘不務正業’時的開放胸懷。到現在,我已經在 GitHub 上開發了包括 OCR 文字辨識、異體字轉換、歷史地理編碼器等多個面向人文學者的開源計畫。」她說。
一路走來,電腦和相關領域的開源精神使她受益匪淺,跨學科研究的經歷則讓她深信:古老的學科也可以擁抱嶄新的技術,新的技術屬於所有人。
參考資料:
1.https://arxiv.org/abs/2403.00509
排版:希幔











