此前我們已經出過一篇超能課堂講述了新的Zen 5、RDNA 3.5和XDNA 2技術細節,那些內容是AMD在此前的技術日活動上介紹的,現在他們又放出了更多的資料,對Zen 5架構以及Granite Ridge和Strix Point進行了更詳細的介紹。

Zen 5架構的設計目標是提升單執行緒和2執行緒的效能,並為未來計算核心架構奠定新的基礎,並為AVX512運算提供完整的512位元數據位寬以提升吞吐量並提高AI運算效能。而平台方面,新架構包含Zen 5和Zen 5c兩種針對不同方向最佳化的核心,雖然現在Zen 5處理器都是用台積電4nm,但未來會有3nm的版本,Zen 5支持可配置的FP512/FP256數據,並新增了ISA功能指令集。

Zen 5直接升級成雙管道預取和解碼,最佳化分支預測與預取Zero-bubble分支,L1/L2分支目標緩沖區從上代的1.5K/7K大幅擴大至16K/8K,目標地址生成引擎也更大,返回地址堆疊現在擴大到52個條目,這些改動可提高處理器的分支預測準確性,減少分支重新導向的開銷,從而提升效能,現在每周期最多可采取2次預測,最多3個預測視窗。
記憶體管理采取了激進的取指隱藏了L2和表遍歷延遲,L2指令地址轉換緩存擴大到2048個條目。緩存延遲與頻寬方面現在每周期64字節的取指,並有兩個指令取指流。這些改動能讓處理器夠快速地從緩存中獲取指令,並且支持多個指令同時進行取指,從而提高了處理器的吞吐量和效率。
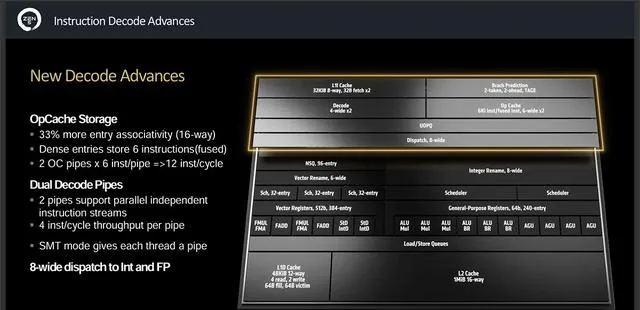
解碼部份同樣升級成雙管道,兩個管道支持獨立的並列指令流,每個管道每周期處理4條指令,在SMT模式則為每個執行緒提供一根管道,在工作分配上,有8-wide派遣到整數和浮點運算執行單元。Op Cache方面,條目關聯性從12-way增加到16-way,密集型條目儲存6個指令,由於采用雙管道設計所以每周期一共可儲存12個指令。
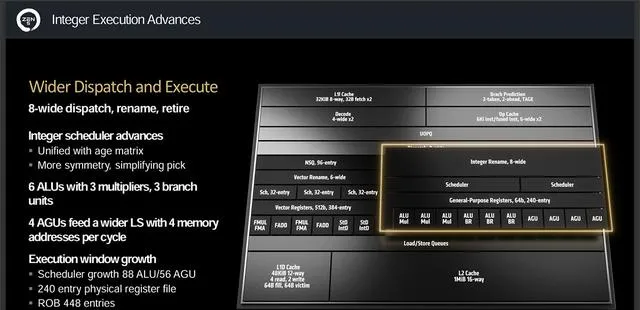
整數執行單元加寬了指令分派和執行通道,分配和引退從以往Zen架構的每時鐘周期6條指令增加到8條,整數排程聽過age matrix同一可以更堆成並簡化挑選。
以往的舊Zen架構整數執行單元包括4個ALU和3個AGU,而Zen 5則增加到6個ALU和4個AGU,而這6個ALU包含3個多乘法器和3個分支單元,4個AGU可每周期處理4個記憶體地址。執行視窗也顯著增長,排程器增長到88 ALU和56 AGU,並配備240條目的物理寄存器,在更復雜的計算工作負載下會有更好表現。
此外核心緩沖區從320條目增加到448條目,以更好地處理更廣的排程和執行所產生的更多的未命中。

浮點執行單元獲得重大更新,AMD自上代Zen 4開始支持AVX-512指令集,但那是使用256位SIMD用兩個時鐘周期來執行AVX-512指令的,而Zen 5則可提供完整的512位元數據位寬。新的執行單元擁有更高的頻寬與更低的延遲,擁有4條執行管線,2條LS/整數寄存器管線,每周期可執行2條512b的載入和1條512b儲存,並配備2周期延遲的FADD。
執行視窗也變得更大,NSQ伴隨8-wide派遣而有所增加,從64增加到96;排程器數量從2個增加到3個;物理寄存器從192翻倍到384;ROB/退休佇列從320增加到448。這些改動讓CPU可處理更多浮點指令,在CPU執行一些AI模型時,能夠顯著提高反應速度與效能,面對未來各種AI套用。
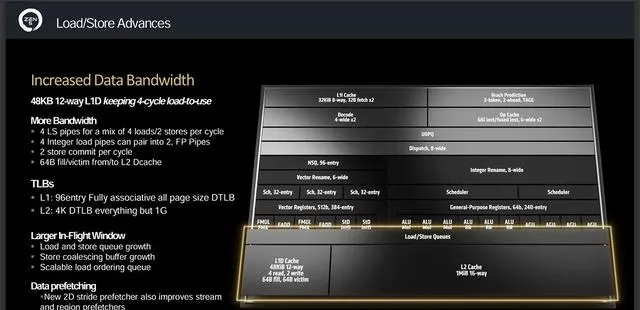
緩存方面,一級數據緩存容量從32KB增加到48KB,寬度也從8路增加到12路,4條L/S管道每周期4次讀取2次寫入;4條整數裝載管道可以配對到2條浮點管道;每周期2條儲存送出;與L2緩存的通訊位寬上下行均從32B翻倍到34B,讓L2頻寬直接翻倍。DTLB數據轉換旁路緩存也跟隨增長,L1從72條目增加到96條目,L2則從3072增長到4096。一級緩存與浮點單元的最大頻寬直接比上代翻倍,改善了數據預取的效率。

以上就是Zen 5架構的改進更新重點,改進方向大體可歸納為:每周期可執行更多指令;更寬的排程和執行單元;數據緩存頻寬翻倍;更強的AI加速效能。

新架構包含Zen 5和Zen 5c兩種采用同架構,但針對不同方向側重最佳化而設計不同的核心。Zen 5是針對單執行緒效能最佳化的核心,目標是更高的時脈,每核心更大的L3緩存,因此Zen 5核心會更為耗電並且會占用更大的芯片面積。Zen 5c則是針對可延伸性而最佳化,擁有相同的IPC和指令集但頻率會較低,而且每個核心的L3緩存也較少,所以芯片面積也更小,單個內核面積會比Zen 5少25%,算上L3的話縮小比例更多。
AMD這次為面向移動處理器的Strix Point同時配備了Zen 5和Zen 5c兩種內核,並透過簡單的軟體排程核心工作,由於Zen 5和Zen 5c擁有相同的IPC和特性,所以排程器不太需要擔心效能上的落差以及排程錯誤的問題,而且Zen 5和Zen 5c都支持SMT同步多執行緒,所以軟體只需要考慮核心的效能和效率即可。
至於桌面端的Granite Ridge,也就是銳龍9000,AMD認為不需Zen 5c核心來擴充套件多執行緒效能,用兩個Zen 5的CCD即可獲得較好的多執行緒效能。

Zen 5增加了ISA指令集,包括MOVDIR/MOVD64B可跳過緩存直接移動4、8或64字節數據至儲存;VP2INTERSECT和VNNI/VEK都是針對AVX512所增加的指令集,前者是AVX-512的向量對相交操作,後者則擴充套件AVX512指令到VEK編碼;PREFETCHI是軟體預取指令行到緩存階層。PMC虛擬化則是針對安全所增加的指令集。
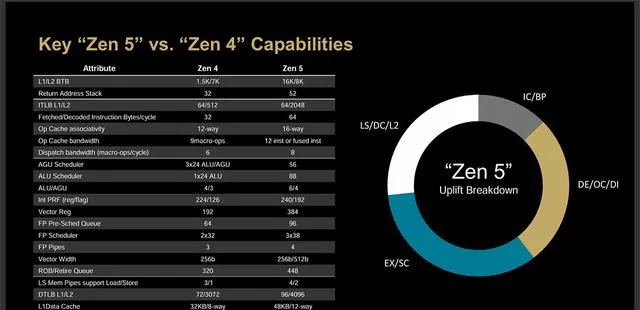
Zen 5對比Zen 4的改動匯總可見上表,Zen 5架構的效能提升主要由數據頻寬、執行/退休、解碼/指令緩存以及獲取/分支預測這四大部份改進相互促進而成的,根據此前給出的數據,Zen 5的IPC較Zen 4平均提升了16%之多。
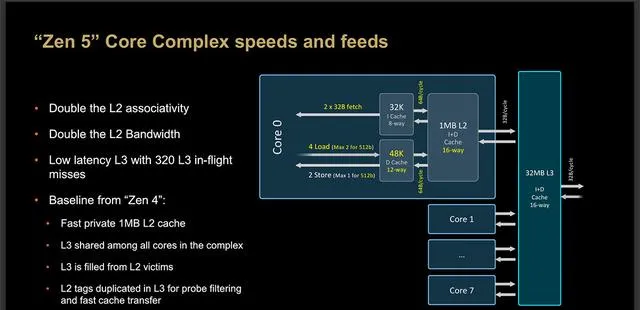
這是Zen 5 CCX的緩存結構圖,大致結構和Zen 4差不多,L1緩存的變動在上面內核介紹時已經說了,L2緩存容量依然是1MB,但從8-Way增加到16-Way,這直接讓L2緩存頻寬翻倍,L3緩存的延遲有所降低。
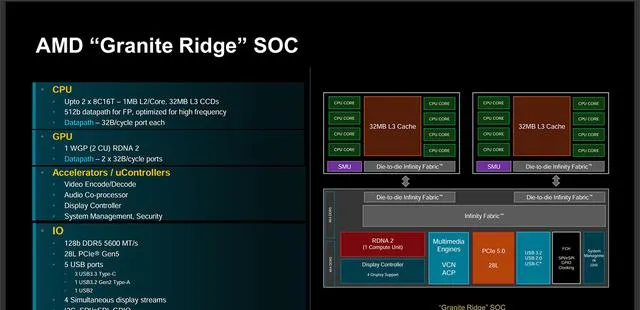
Granite Ridge其實沒啥好說的,SoC結構和Zen 4的Raphael完全一樣,繼續使用上代的6nm IOD,可配備兩個Zen 5 CCD,最多16核32執行緒,IOD支持128bit DDR5-5600記憶體,配備兩個RDNA 2架構CU的核顯,可提供4路顯示輸出,有28條PCIe 5.0,5個USB介面。

而面向移動端的Strix Point內部包含兩組CCX,一個擁有4個Zen 5內核,擁有16MB L3緩存,而另一個則擁有8個Zen 5c內核,擁有8MB L3緩存,兩者的緩存是相互獨立的,需要透過SoC內部的IF匯流排通訊。這設計就和此前的Phoenix 2很不一樣,它擁有的2個Zen 4和4個Zen 4c是在同一個CCX內的,6個核心共享16MB L3緩存。
此外Strix Point還有一個配備16組RDNA 3.5架構CU的核顯,一個4*8共32個AI引擎的XDNA 2架構NPU,IO方面,支持128bit LPDDR5-7500或DDR5-5600記憶體,提供16條PCIe 4.0通道,支持4路視訊輸出,一共可提供8個USB介面,包括兩個USB4。

Radeon 890M核顯有8組WGP,共16組CU,包含1024個流處理器、32個AI單元和16個光追單元、16個ROP,最高頻率2.9GHz,FP32吞吐量超過11 TFLOP/s,同功率下較上代核顯高出30%。
RDNA 3.5較原來的RDNA 3相比有兩倍的紋理取樣率和插值與比較速率,前者意味著GPU擁有前代的兩倍效能,在遊戲過程中紋理和圖形的細節和解析度得到增強,理論上有助於改善細節紋理,在高分辨率時更有冗余,而後者則可以更好地呈現高品質圖形細節。
還引進了更先進的記憶體管理技術,提高了記憶體每bit的操作效能,降低了對LPDDR5記憶體存取頻率,意味著讀寫更快,總體上也更節能,延長筆記本的電池續航力。

XDNA 2擁有32個AI引擎,每列擁有4個AI引擎,MAC數量較上代翻倍,緩存容量增加1.6倍,支持Block FP16塊狀浮點格式,支持非線性增強。NPU可根據任務的輕重程度以列為單位開啟AI引擎,在輕任務下可以關閉部份核心,從而節約功耗,能效比初代提高了一倍。效能方面,XDNA 2可提供50 TOPS的AI算力,是上代的5倍。

除了即將上市的兩款消費級處理器外,采用Zen 5內核的第五代EPYC也將會在今年下半年上市,目前的Zen 5 CCD以及銳龍AI 300將會采用台積電4nm工藝生產,而未來更緊湊、更節能的Zen 5c則會采用台積電3nm工藝。

總結一下,Zen 5帶來了16%的IPC提升,改良重點包括平衡的跨核單/雙執行緒指令和數據吞吐量;完整的512位元浮點數據路徑帶來了更好的AVX512吞吐量,讓AI效能提升;擁有各種高效能、高效能以及可延伸的解決方案。
沒啥意外的話搭載Strix Point的筆記本會在7月28日發售,但Granite Ridge桌面處理器就延期了,AMD今天剛發出公告推遲銳龍9000系列處理器的發售日期,其中銳龍7 9700X和銳龍5 9600X推遲至8月8日,而銳龍9 9950X和9900X則延期至8月15日。











