按:基於x86處理器上,以系統啟動過程中記憶體管理的逐步構建為主軸,分析記憶體的管理方式與其相關的安全防護功能。
1、如何知道電腦記憶體布局?記憶體空間有多少?
春江水暖鴨先知,電腦上電啟動的時候,BIOS會檢測並計算實體記憶體大小。比方說現在通用的記憶體都是DIMM針腳插槽型別的,它的PIN針腳有兩百多個,各個針腳各有自己的定義,BIOS就是透過對不同針腳的高低電平設定,由記憶體反饋其規格資訊給BIOS,然後BIOS計算出容量。大概原理就這樣了。但是我們重點是作業系統需要感知主機的記憶體空間,它是怎麽知道的呢?它是透過BIOS提供的介面去詢問出來的。這個介面就是0x15中斷,其中參數重點參數是ax寄存器中需要設定值e820。然後透過intcall(0x15, &ireg, &oreg)中斷呼叫,由BIOS透過oreg.di出參將記憶體資訊返回回來。該實作在/arch/x86/boot/memory.c中的detect_memory,由於程式碼出參oreg.di也是ireg.di傳進去的值,所以程式碼裏面直接讀了buf空間記憶體。由於每呼叫一次intcall只會返回一條記憶體數據資訊,所以會迴圈呼叫多次才能夠探明整個記憶體空間。

2、何時去探明記憶體布局?由誰去探明呢?
記憶體探測必然是kernel嗎?答案是否定的。先說一下kernel的binary檔吧,它通常放在/boot/下面,名字通常命名為vmlinuz。這個檔是由setup.bin和vmlinux構造而成,其中vmlinux又由kernel編譯目錄arch/x86/boot/compressed下的cmdline.o、head.o、kaslr.o等連同壓縮後的vmlinux.bin.gz合並構成。其中檢測記憶體的detect_memory()函式就是在setup.bin裏面,但是這僅限於Grub legacy(即Grup 0.97到1.97版本)引導kernel的時候,setup.bin才會被執行到,也就是僅在該情況下記憶體探測才是由kernel引導的領頭羊去完成的。到了Grub2(即Grub 1.98到現在最新版本)引導linux系統的時候,則由Grub直接探明記憶體布局,然後解析vmlinuz檔,並且直接載入vmlinux部份的內容到記憶體中並跳轉執行head_32函式,而記憶體布局則透過參數boot_params傳遞執行。誰探明記憶體布局對記憶體管理有影響嗎?沒影響的,所以這裏是可以忽略的廢話。既然廢話就多說兩句,為什麽要分開setup.bin和vmlinux呢?這是因為setup.bin執行在真實模式下面,而vmlinux則執行在保護模式下面。所以也就是說grub2是進入了保護模式後才載入引導的kernel。
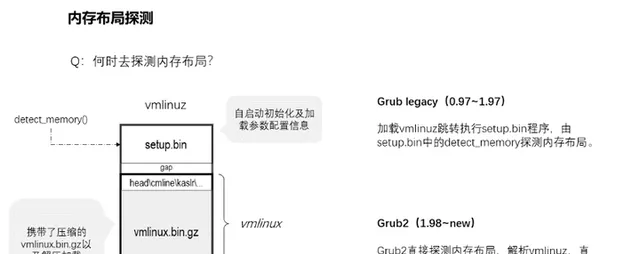
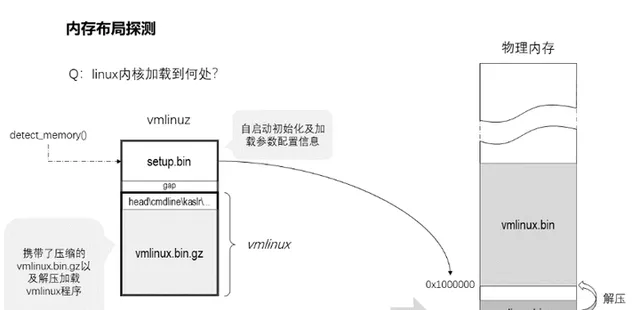
3、kernel會載入到何處呢?由什麽決定它的位置?
setup.bin的首部512字節是一段MBR程式碼,它可以實作kernel自引導。緊挨著這512字節後面是kernel的載入資訊,其中就包括了指示vmlinux的載入地址資訊,通常是0x100000。它也不僅有vmlinux的載入地址資訊,同時也攜帶了vmlinux.bin.gz解壓的地址資訊,通常為0x1000000。不過這都是建議值,可能會因一些狀況載入到別處。比如接下來要講的內核的自我防護。
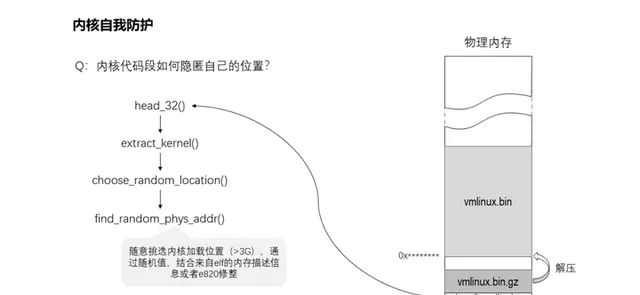
4、kernel映像如何隱匿自己的位置?
預設的情況下,kernel的映像是載入到了0x1000000的位置,由此攻擊者分分鐘可以透過地址偏移找到內核關鍵數據的位置,從而借助內核的越界、任意地址讀寫等漏洞發起攻擊。因此kernel隱匿自己的位置可以很好地增加攻擊者的難度,從而起到自我防護。所以引入了KASLR(kernel address space layoutrandomization),即內核地址空間布局隨機化。該功能實作在arch/x86/boot/kaslr.c,由head_32()呼叫extract_kernel()執行kernel映像解壓的時候,透過choose_random_location()呼叫find_random_phys_addr()使用隨機值計算出載入位置。在32位元環境下,它將隨意挑選內核載入位置(>3G),透過隨機值,結合來自elf的記憶體描述資訊或者e820修整。該功能配置項為CONFIG_RANDOMIZE_BASE,也可以透過內核啟動參數「nokaslr」進行關閉。
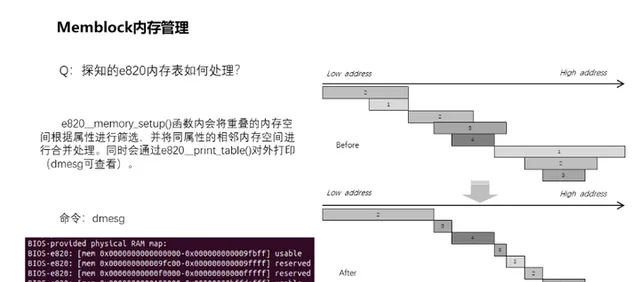
5、探知的e820表如何處理?
前面已經知道了如何探明記憶體空間得到e820圖,得知了記憶體的位置、大小和型別。在e820 memory_setup()函式內會將重疊的記憶體空間根據內容進行篩選,並將同內容的相鄰記憶體空間進行合並處理。整個處理過程如右側所示,雖然實作上會對記憶體進行分割合並處理,但是實際上記憶體並不會這麽錯亂重疊的。處理完畢後,會透過e820 print_table()對外打印。透過dmesg可以看到如圖左側所示的資訊。
6、記憶體是連續的嗎?
實體記憶體是連續的,但是細心的話,可以發現e820提供的數據中並不連續,中間0xA0000到0xFFFFF的記憶體並未在其中。這是歷史原因遺留下來的,它並非不存在,而是被BIOS保留下來用作顯卡視訊記憶體的對映以及BIOS自留給ROM使用的空間。所以呈現出來有一個空洞位置。
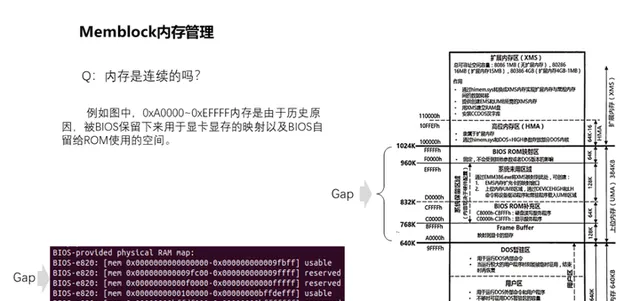
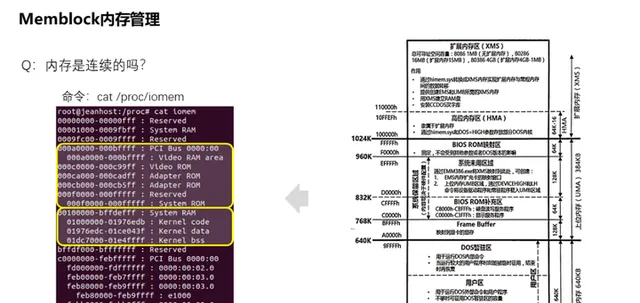
對此我們可以透過/proc/iomem檢視到這些實體記憶體被如何劃分分配。iomem主要呈現系統中裝置的物理布局,包括未被e820所呈現的,它甚至能夠將kernel在實體記憶體的載入位置呈現出來。
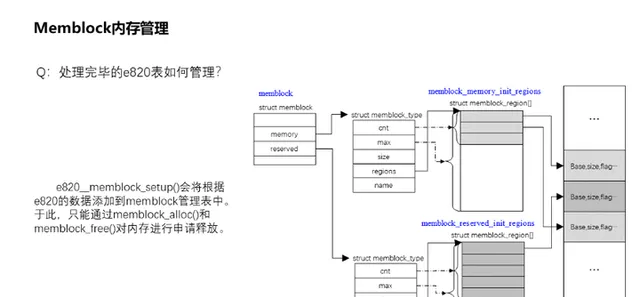
7、處理完畢的e820表如何管理?
經過按照型別的分割整合之後,e820__memblock_setup()會將根據e820的數據添加到memblock管理表中。memblock管理表由命名為memblock的全域數據結構變量管理,它主要透過可用記憶體memory和保留記憶體reserved兩個成員結構體變量區分管理。例如可用記憶體全部都掛入到memblock.memory.regions下,該可用記憶體同時又以全域變量陣列memblock_memory_init_regions而命名,該陣列成員主要記錄記憶體的基址、大小和型別,如圖顯示的是該演算法的管理結構關系。類似的被保留的記憶體則在memblock_reserved_init_regions全域陣列結構下管理。於此階段,我們可以透過memblock_alloc()和memblock_free()對記憶體進行申請釋放,而分配的方式很簡單,根據需要分配的size到可用的記憶體空間memblock_memory_init_regions中去尋找連續的等大小空間,然後將其分割開來,將分配出去的掛入到memblock_reserved_init_regions管理區中,而剩余的則放回到memblock_memory_init_regions。尤其是如果我們需要申請永久保留的記憶體可在此申請,即後續記憶體管理將不會對此記憶體進行分配回收管理。memblock記憶體管理只是一個過渡形態,不會長期存在,畢竟如此任意分割記憶體的分配方式長久執行後會導致嚴重的碎片化。因此後面將會建立記憶體對映,構造記憶體管理框架。
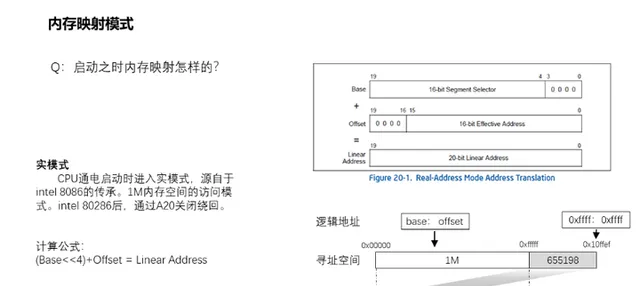
8、啟動之時記憶體如何對映的?
CPU通電啟動時預設進入真實模式,這是源自於intel 8086的傳承,向前相容。於intel 8086的時候,記憶體地址匯流排為20bit,而寄存器為16bit,地址匯流排的寬度一般是要大於寄存器的寬度,所以為了能存取整個地址空間,需要采取特殊的尋址計算——分段尋址。實體位址由段地址(segmentselector)與偏移量(offset)兩部份組成,長度各是16bit。其中段地址左移4位元(即乘以16)與偏移量相加即為實體位址。由於記憶體地址匯流排只有20bit,所以實際上只有1M記憶體空間可存取。但是如果base和offset都為0xffff的時候,可以存取最大的地址值為0x10FFEF,由於僅能夠存取到1M的記憶體空間,所以從0x100000到0x10ffef的記憶體空間實際上是0x0到0xffef,透過「wrapping」繞回回去了。而後演進到intel 80286,可以透過A20關閉繞回。但是開啟A20Gate後,只是在真實模式上使得處理器能夠最大化存取0x10ffef的地址空間,而不是wrap繞回去存取低地址空間。但是要想存取0x10ffef以上的記憶體,則必須進入保護模式。
相關視訊推薦
linux記憶體管理-龐雜的記憶體問題,如何理出自己的思路出來
面對記憶體再不發怵,手把手帶你實作記憶體池(準備好linux環境)
輕松解決記憶體泄漏問題,記憶體泄漏的定位,記憶體泄漏的解決方案
需要C/C++ Linux伺服器架構師學習資料加qun 812855908 獲取(資料包括 C/C++,Linux,golang技術,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,串流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK,ffmpeg 等),免費分享
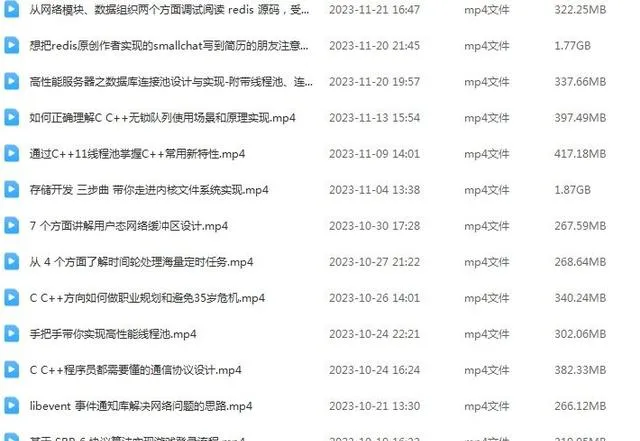
9、保護模式是怎樣的?相比真實模式有何特點?
了解過linux記憶體的都知道有頁保護模式,但是實際上對於x86而言,段模式已經是保護模式了。段模式是怎樣的呢?它的邏輯地址空間是由一組段構成。每個段都有名稱和長度。地址指定了段名稱和段內偏移。使用者需要透過兩個量來指定地址:段名稱和段偏移。如何啟動保護作用呢?尋址時根據不同的段寄存器內容尋找到對應的段描述符,描述符指明了此時的環境的可以透過段存取到記憶體基地址、空間大小和存取許可權。存取許可權則點明了哪些記憶體可讀、哪些記憶體可寫。如圖中DPL描述本段記憶體所需許可權。所以段模式就是保護模式了。不過實際上,linux並不使 用段保護功能。這裏只是略提一下。

10、頁保護模式是怎樣的?
X86的頁保護模式就是段頁模式,基於段模式的情況下,在每個段裏面又進行分級分頁,形成將分段和分頁組合起來使用的情況,可以參考上圖。x86是無法繞過段模式,而獨立開啟使用頁模式的。分析Linux最初進入保護模式的實作,可以看到linux開啟段模式僅是一種純段式的記憶體對映模式,並不會開啟段的保護模式。因為Linux是不使用段保護的,使用的是頁保護,所以Linux在後面還會構建頁表建立頁對映並開啟分頁管理。linux對段模式的處理就是每個段都是0~4G的地址空間,相當於什麽也沒有做一樣,剩下的管理全由分頁機制來實作。同時在分頁的過程中,頁目錄項和頁表項裏面的欄位都保留了R/W位用來保護是否可寫。篇外話,如果對CPU比較熟悉的話,可以留意到x86這種經典分頁模式並沒有提供執行許可權位的設定,也因此經典的x86 分頁是允許程式在棧上執行程式碼的原因,由此很容易利用棧緩沖區溢位。
11、頁面對映有何作用?都有什麽好處?
頁面對映,根據處理器的不同,可以劃分為不同大小的頁面,相比段模式,粒度更小,從而降低了實體記憶體的內部碎片化。同時頁目錄、頁表等如同橋梁一般,將實體記憶體和虛擬記憶體關聯起來。可以實作多行程隔離,每個行程都有自己獨立的地址空間,行程可以獨立載入執行,而無需考慮對其他行程的地址空間的影響。避免相互幹擾,增強容錯。此外也更易於實作記憶體共享,如同內核空間就是多行程共享。更重要的是提升了安全性,對所有行程暴露的僅有虛擬記憶體空間,而實體位址空間則被隱匿起來。

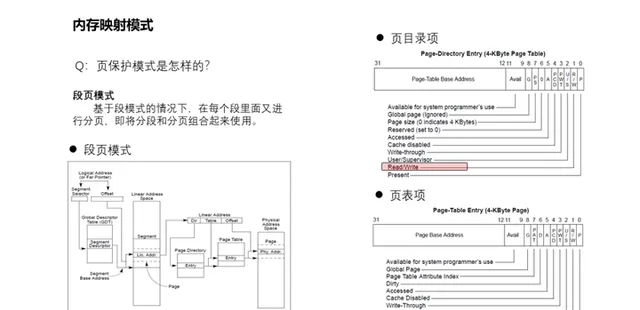
12、x86支持的對映模式都有哪些形式?如何分級的?
記憶體頁面的分級對映取決於所需對映的記憶體頁面大小。為什麽需要有不同的大小頁面呢?因為過小的頁面大小會帶來較大的頁表項增加尋址時TLB(Translation lookaside buffer)的尋找速度和額外開銷;過大的頁面大小會浪費記憶體空間,造成記憶體碎片,降低記憶體的利用率。例如32位元環境,其支持4k大小頁面,同時也支持2M的大頁面。如圖所示,4k頁面需要2級對映關系,而2M頁面僅需1級對映關系。而PAE(Physical Address Extension),即實體位址擴充套件實體位置延伸,是x86處理器的一個功能,讓中央處理器在32位元作業系統下存取超過4GB的實體記憶體,在4k頁面對映下就已經需要3級對映關系了。而到了64位元,則從4k頁面到2M頁面,甚至支持1G頁面的對映,進而演進到4k需要4級對映。
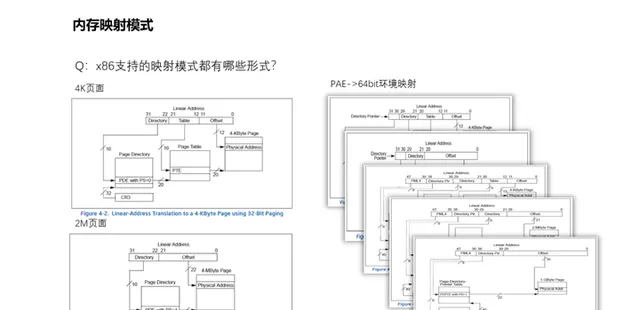
13、內核如何處理多樣式的頁對映?
Linux是一個支持多硬體平台的作業系統,各種硬體芯片的分頁層次以及分頁大小並非固定的,僅x86處理器而言,其32位元環境就存在2級分頁的情況,而到了64位元處理器的時候就成了最多4級分頁。對此Linux采取了以不變應萬變的形勢,劃分了頁全域目錄、頁上級目錄、頁中間目錄、頁表等,然後按需設定。例如x86的32位元環境對映4k頁面,則頁上級目錄和頁中間目錄的bit位設定為0,存取和設定時均空操作返回,僅余頁全域目錄和頁表的存在,對其設定相應的bit位長度,實作相應的設定功能,即可使基於分頁模式上的上層應 用無差異化執行。
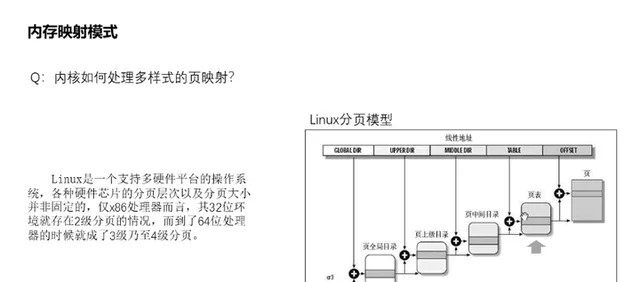
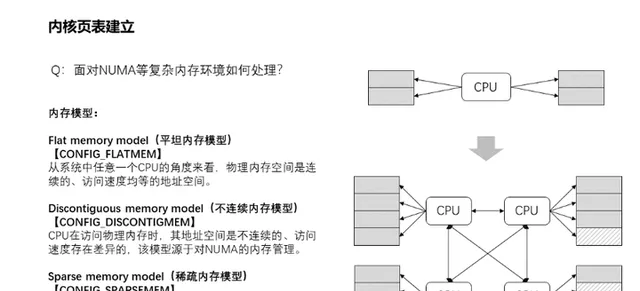
14、面對NUMA等復雜記憶體環境如何處理?
這裏主要講一下記憶體模型,所謂記憶體模型,其實就是從cpu的角度看,其實體記憶體的分布情況,在linuxkernel中,使用什麽的方式來管理這些實體記憶體。主要有三種記憶體模型:flat memory model,Discontiguousmemory model和sparse memory model。其中平坦記憶體模型(Flat memory model)主要特點是CPU存取系統的整個記憶體,其實體記憶體空間是連續的,並且存取任意點的時間和速度都是相同的。而管理上,每一個物理頁幀都會有一個page數據結構來抽象,因此系統中存在一個structpage的陣列(mem_map),每一個陣列條目指向一個實際的物理頁幀(pageframe)。物理頁面與page結構陣列關系是一一對應。隨著電腦發展,後面多CPU的出現,每個CPU都有自己獨立的記憶體通道,透過自己的記憶體通道存取與之連線的記憶體,其速度是均勻的。但是如果要是想存取其他CPU記憶體通道連線的記憶體,則時間上開銷就慢許多了,而且記憶體甚至不連續,由此造成了全域記憶體的存取速度差異以及不連續性。這就是NUMA架構的由來,為此引入了不連續記憶體模型(Discontiguous memory model)。該模型對記憶體的管理是平坦模型的延續,它將連續的存取速度一致的一片大記憶體歸為一個node,而node內的記憶體管理則采用了平台記憶體模型的管理方式,page結構陣列與物理頁面一一對應管理。其中每個node管理的實體記憶體page結構保存在structpglist_data 數據結構的node_mem_map成員中。但是技術永遠在進步,隨著hotplug記憶體熱插拔的出現,那麽node節點內的記憶體也可能出現不連續的情況,由此又演進出了稀疏記憶體管理模型(Sparse memory model),該模型下連續的地址空間按照SECTION(例如1G)被分成了一段一段的,其中每一p都是hotplug的。記憶體管理的時候,整個連續的實體位址空間是按照一個p一個p來切斷的,每一個p內部,其memory是連續的(即符合flatmemory的特點),因此,mem_map的page陣列依附於p結構(structmem_p)而不是node結構了(structpglist_data)。實際上不連續記憶體模型和稀疏記憶體模型都可以對NUMA架構進行記憶體管理,因為NUMA沒 有明確記憶體必須連續的,所以兩種模型都可以管理NUMA架構的記憶體。
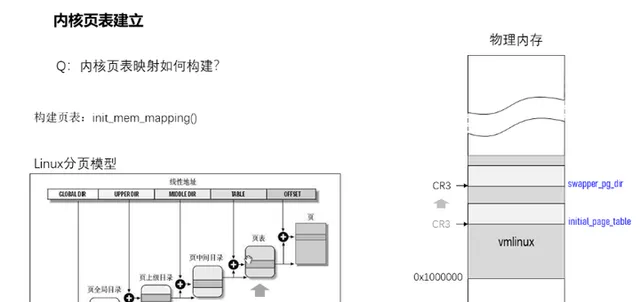
15、內核頁表如何建立?
進入start_kernel前,是透過initial_page_table構建的頁全域目錄,到了setup_arch的時候,會將其部份頁目錄資訊拷貝到swapper_pg_dir裏面,而頁表則是透過memblock記憶體管理分配而來,最後在init_mem_mapping透過init_memory_mapping把所有記憶體對映起來,包括0到0x100000的ISA記憶體以及它的空洞部份(即驅動及ROM保留的部份)。建立記憶體對映需要多少記憶體呢?以32位元系統為例,4G空間除以4k頁面大小(offset的12bit代表的空間)得到頁表項數,再乘以每項頁表4byte的大小,可以得到如果對映完了,需要4M大小的頁表空間。而頁全域目錄經過同樣的換算,可以得知僅需4k記憶體,一個記憶體頁而已。
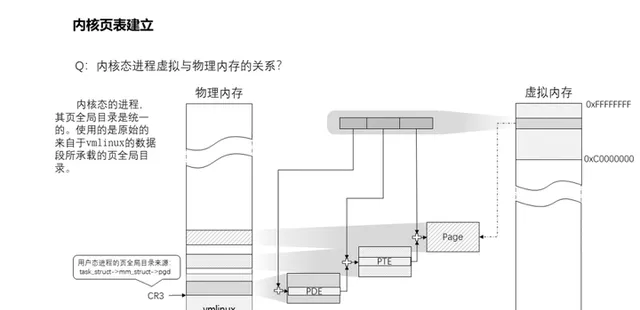
16、內核態行程虛擬地址與實體記憶體的對映關系?
內核態的行程,其頁全域目錄基本是統一的。雖然各個行程都有自己的管理結構task_struct,該結構內mm_struct結構成員pgd記錄著其頁全域目錄,但是只要它沒有過多的記憶體訴求的情況下,是不會觸發記憶體分配修改頁全域目錄的操作,因此使用的是原始的來自於vmlinux的數據段所承載的頁全域目錄,即swapper_pg_dir指向的位置。那麽頁表PTE也則是復用頁表對映時memblock分配的記憶體。如果涉及到驅動相關的內核行程,它們需要對裝置介面做記憶體對映,這時候就會觸發寫時拷貝動作,分配新的記憶體作為頁全域目錄,將所有表項拷貝過去,然後基於此進行修改。
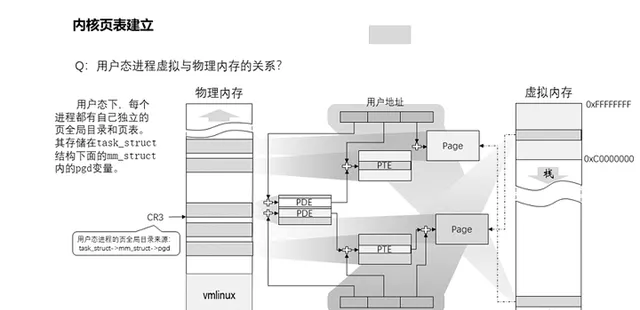
17、使用者態行程虛擬記憶體與實體記憶體的關系如何?
純內核態行程是不需要存取0到3G的記憶體空間的,因此其頁表對映不需要這部份的對映關系。但是使用者態行程則是需要的,因此它的頁全域目錄會有更多的頁表對映,除了內核空間的頁表對映項可以復用以外,也需要更多對映到使用者空間的頁表,所以使用者態下每個行程都有自己獨立的頁全域目錄和部份私有的頁表。同樣其頁全域目錄儲存在task_struct結構下面的mm _struct內的pgd變量。
18、記憶體管理框架如何構造?
NUMA:Non-uniform memory access,即非一致性記憶體存取。它引入了node的概念(儲存節點),把存取時間相同的儲存空間歸結為一個node節點。對於多CPU的復雜環境則需要多個node節點數據(structpglist_data)來管理,而透過宏定義NODE_DATA可以得到指定節點的structpglist_data(即pg_data_t)。後面將會基於單個node的情形進行分析。基於node的structpglist_data結構下則有著structzone用來管理具體的實體記憶體頁。zone的存在是由於32位元環境下記憶體空間限制,記憶體分配的用途和速度上的差異而存在的,64位元環境基本淡化了。其中ZONE_DMA(0-16MB)是某些ISA裝置所需的低地址範圍的實體記憶體,而ZONE_NORMAL(16MB-896MB)中的記憶體直接對映到線性地址空間的上部區域,高效能記憶體分配區域,至於ZONE_HIGHMEM (896MB以上)則是系統中剩余的可用記憶體,並不由內核直接對映,分配時還需要重新對映,效能略遜一籌。總而言之,linux的實體記憶體管理機制將實體記憶體劃分為三個層次來管理,依次是:Node(儲存節點)、Zone(管理區)和Page(頁面)。此外,NUMA強調的是memory和CPU的位置關系,和記憶體模型其實是沒有關系的。如果非要說關系的話,記憶體管理框架和記憶體模型的關系可以理解為:管理維度不同,記憶體管理模型類似於檔案式管理,每頁記憶體都有一個structpage的結構體檔案,而記憶體模型類似於軍隊編制化管理,按照軍團連方式層級劃分管理,直接是記憶體頁面。內 存管理框架的構建主要是在initmem_i nit()函式內實作。
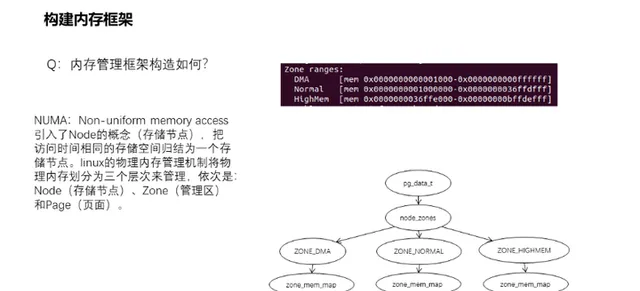
19、Kernel記憶體空間如何劃分?
前面講到了記憶體框架,kernel將zone分為了DMA、NORMAL和HIGH。從對映的角度而言,分為直接記憶體對映區和高端記憶體對映區。其中直接記憶體對映區是指3G到3G+896M的線性空間,直接對應實體位址就是0到896M(前提是有超過896M的實體記憶體),包括DMA和NORMAL兩個zone,其中896M是high_memory值定義的大小,該區記憶體使用kmalloc()/kfree()介面操作申請釋放;而高端記憶體對映區則是超過896M實體記憶體的空間,它又分為動態對映區、永久對映區和固定對映區。動態記憶體對映區,又稱之為vmalloc對映區或非連續對映區,是指VMALLOC_START到VMALLOC_END的地址空間,申請釋放操作介面是vmalloc()/vfree(),通常用於將非連續的實體記憶體對映為連續的線性地址記憶體空間;而永久對映區,又稱之為KMAP區或持久對映區,是指自PKMAP_BASE開始共LAST_PKMAP個頁面大小的空間,操作介面是kmap()/kunmap(),用於將高端記憶體長久對映到記憶體虛擬地址空間中;最後的固定對映區,也稱之為臨時內核對映區,是指FIXADDR_START到FIXADDR_TOP的地址空間,操作介面是kmap_atomic()/kummap_atomic (),用於解決持久對映不能用於中斷處理常式而增加的臨時內核對映。

20、64位元地址空間如何劃分?
x8686位環境,實際上使用的地址匯流排寬度為46位,因此其最大支持的記憶體空間為256T,相比32位元環境,記憶體更加寬裕了,因此內核與使用者態空間對半分,各占用128T。由於有了更廣闊的空間,所以記憶體布局和32位元相比,就有了很大的不同,但這也僅是布局上的不同而已,對於記憶體管理演算法機制還是基本一致的。這裏就不展開細講其布局了。

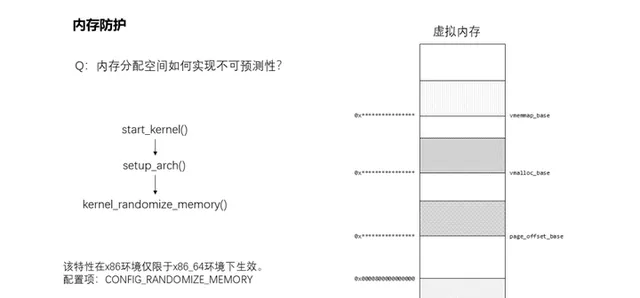
21、記憶體分配空間如何實作不可預測性?
記憶體分配空間的隨機性是在setup_arch()中,透過kernel_randomize_memory()來實作的,主要是將直接對映區域基址(page_offset_base)、vmalloc區域基址(vmalloc_base)、vmemmap區域基址(vmemmap_base)這三個地址進行隨機化。這三塊記憶體的基址變了,將會使得分配記憶體的位置不可預判,在哪個範圍都不確定,更何況位置。但是這功能僅能在地址空閑富裕的64位元環境上透過CONFIG_RANDOMIZE_MEMORY配置項使能,32位元環境則無該功能,畢竟地址空閑有限,不過前面提到的kaslr實際上也是會對32位元的記憶體分配地址空 間產生間接的影響。
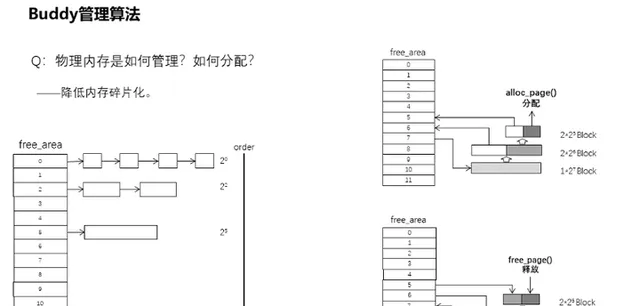
22、實體記憶體是如何管理的?怎麽分配的?
透過前面已經知道了e820的記憶體交給了memblock管理,一個很粗獷的管理方式,存在著碎片化的風險。所以為了降低記憶體的外部碎片化,記憶體將會交給Buddy管理演算法進行管理。該演算法特點是基於MAX_ORDER為11的情況,構造一個倍增型哈希表,各個表項下的頁面連結串列分別表示為:1、2、4、8、16、32、64、128、256、512、1024個連續的頁面,即按照翻倍的形式來遞進組織,而且每個頁面塊的第一個頁面的實體位址是該塊大小的整數倍。假設實體記憶體連續,各空閑頁面塊左右的頁面,要麽是等同大小,要麽就是整數倍,而且還是偶數,形同夥伴。分配的時候,先從滿足申請大小的連結串列中提取空閑頁面塊,如果連結串列為空,則會往高一階的頁面塊連結串列進行尋找,如果依舊沒找到,則繼續往高階進行尋找,直到找到為止,否則就是申請失敗了。如果在高階的頁面塊連結串列找到空閑的頁面塊,則會將其拆分為兩塊,如果拆分後仍比需要的大,那麽繼續拆分,直至到大小剛好為止。而釋放則放入到對應大小的連結串列中,同時判斷相鄰等大小的記憶體頁面塊是否存在,若存在則將兩者合並放入到高一階連結串列中,依此類推。alloc_ page()和free_page()則是實體記憶體的分配釋放入口。
23、Buddy管理演算法所處的位置?在什麽地方體現?
如前面的NUMA管理框架所言,由Node到zone,所有記憶體頁面歸在zone的管理。所以buddy演算法的管理結構在每個zone下面都有一個。由node管理結構structpglist_data下,存在著一個struct zone陣列結構,接著每個struct zone都有著自己獨立的buddy管理結構free_area[MAX_ORDER],這是一個structfree_area結構陣列。不過這還沒完,每個struct free_area下面又根據記憶體頁面的遷移型別進行分類管理,每個型別有著自己獨立的連結串列。這些型別有什麽用呢?這就涉及到接下來的記憶體頁面遷移特性了。此外補充一句,對於buddy管理的記憶體頁面狀況,可以透過/proc/buddyinfo介面檢視 ,它呈現了按階分布的頁面塊統計。

24、記憶體碎片化了怎麽辦?
雖然buddy管理演算法已經極力地避免了記憶體碎片化,但是系統長久執行,大小不一的實體記憶體分配,終究還是會將記憶體拖進碎片化的深淵,猶如右上圖。此時如果有裝置驅動需要連續的實體記憶體怎麽辦?於是就有了頁面遷移的功能。回歸前面提及的記憶體頁面型別是由enummigratetype定義的,主要有MIGRATE_UNMOVABLE,表示不可移動,針對的是kernel分配的記憶體頁面;MIGRATE_MOVABLE,表示可移動,來自於從使用者空間分配的記憶體和檔;MIGRATE_RECLAIMABLE,不可移動,但可以進行回收的;此外還有MIGRATE_PCPTYPES、MIGRATE_CMA和MIGRATE_ISOLATE等,其中MIGRATE_PCPTYPES表示該記憶體頁面處於percpu中,而MIGRATE_CMA和MIGRATE_ISOLATE則是用於連續記憶體分配中使用的。至於記憶體頁面遷移,主要涉及的就是可移動頁面的處理,而且是針對zone來進行的。當記憶體分配過程中,無法滿足分配需求時,將會喚醒kcompactd執行緒執行遷移動作,或者直接透過echo1 > /proc/sys/vm/compact_memory來觸發。其實作主要是透過freepages空閑連結串列和migratepages遷移連結串列實作的,其中自後往前檢索空閑塊插入空閑連結串列,自前往後檢索可遷移塊插入遷移連結串列。當前後兩檢索碰頭時,表明全部頁面檢索完畢,由此可以將可遷移的記憶體塊往空閑塊上 拷貝,將空閑頁面匯聚到zone的前面去,碎片化也由此得到了消減。
25、如何為驅動套用預留大塊連續記憶體?
CMA:Contiguous Memory Allocator,連續記憶體分配框架,它是在前面的頁面遷移功能的基礎上實作的。旨在解決視訊播放攝錄等需要預留大量連續記憶體導致執行記憶體緊張問題。其可以透過dts(裝置樹)、參數或者宏配置開啟。雖然有分配(cma_alloc())和釋放(cma_release())介面的定義,但是通常不會直接使用,更多的是嵌入到DMA中使用。它雖然標記了記憶體空間,但是並不會獨占,當分配migration型別記憶體時,會將其分配出去。分配出去之後如何需要使用的話,將會把其空間中已分配給migration的記憶體遷移走,給它騰出空間來進行分配,典型的一魚多吃。
26、LRU如何運作?
LRU,Least Recently Used,最近最少使用記憶體。是用於頁面回收置換的演算法,配合kswapd執行緒使用。其本質就是一個在node下面lruvec結構內的連結串列,這連結串列主要用於管理三種型別的記憶體,分別是:匿名頁,即沒有與磁盤檔存在任何對映關系的記憶體頁面,通常是行程的堆疊、數據段或共享記憶體空間;檔頁,即與磁盤檔存在對映關系的記憶體頁,例如行程程式碼段、檔的對映頁等;不可換出頁,通常為內核的程式碼數據段、內核棧及大部份內核使用的記憶體,或者幹脆是被釘選的頁面。然後在匿名頁和檔頁中,分別分為INACTIVE和ACTIVE兩類內容連結串列,如果記憶體頁經常被讀寫存取的情況下,將會放到ACTIVE連結串列中,反 之放在INACTIVE連結串列中。
27、記憶體回收是如何運作的?
安裝作業系統的時候,通常有個swap磁盤空間的大小設定和建立,那麽這個swap空間作何使用?這就涉及到了內核的記憶體交換執行緒kswapd,這是一個常規性睡眠的內核執行緒,僅當記憶體開銷達到臨界點時觸發。在此之前,我們需要知道struct zone結構中存在著一個陣列變量watermark,它包含著三組數據WMARK_MIN、WMARK_LOW和WMARK_HIGH,分別表示該zone在執行時的最低、低和高三個水平。隨著zone的記憶體陸續分配出去之後,空閑空間量緩慢下降,將會透過HIGH下降至LOW,此時將會喚醒kswapd執行緒對記憶體進行異步回收。如果kswapd執行緒因休眠等狀況使得空閑空間觸及WMARK_MIN最低量時,將會直接喚醒kswapd同步回收記憶體。kswapd執行緒主要透過kswapd()函式呼叫balance_pgdat()來完成回收動作,整個回收過程會持續到記憶體空閑量恢復至WMARK_HIGH最高水平才會進入休眠。至於這裏所謂的回收,主要有:1、將磁盤檔對映占用的記憶體直接釋放;2、匿名記憶體對映轉儲到swap磁盤分區。這是因為磁盤檔有磁盤作為儲存介質,因此可以直接釋放掉,需要時重新對映回記憶體中,當然如果檔對映記憶體被覆寫後成為臟頁則需寫回磁盤後方可釋放。至於匿名頁為行程執行所需的記憶體,但是又沒有直 接對應的磁盤檔可回寫備份,因此需要放到swap分區中臨時備份。
28、相同的記憶體浪費記憶體空間了?
對於檔對映到實體記憶體上,由於檔都由內核統一管理,多個行程讀取同一個檔相同片段時,內核實際只在實體記憶體上存了一份數據,各個行程的對映表都修改對映指向它,除非寫時拷貝復制出去的。於是對於檔這類的對映存取對記憶體的開銷是有限的。但是對於虛擬化而言,多虛擬機器執行,有很多虛擬機器的匿名對映的記憶體頁面其實是完全相同的,它與檔毫無關聯,所以內核不知道它們相同,也沒法將它們統一到一份物理對映上。為了解決這個帶來的記憶體浪費,於是引進了KSM功能,有人稱之為Kernel Samepage Merging,也有人稱之為Kernel Shared Memory。其作用就是將完全相同的匿名記憶體頁面的對映歸一,即透過修改記憶體對映,共同使用同一份實體記憶體,如果出現修改時,則透過寫時拷貝解決差異問題。該功能主要是由內核ksmd執行緒完成,執行緒入口為ksm_scan_thread(),主要實作由ksm_do_scan()完成。其邏輯是透過兩個紅黑樹分別對可合並的記憶體塊和待評估合並的記憶體塊 進行管理,周期評估待合並的記憶體,並將滿足條件的相同記憶體進行合並。
29、頁面空間監測手段有什麽?
Poisonpages,頁面註毒,透過對釋放的空閑記憶體進行統一格式化,要麽格式化成為0x00,要麽格式化為0xaa,則取決於配置項CONFIG_PAGE_POISONING_ZERO。格式化之後的記憶體當再次分配時將進行檢查,如果檢測到記憶體空間存在非格式化的數據時,則表明該記憶體曾在空閑時被修改,這就意味著發生了記憶體越界或記憶體釋放後使用等類似情況,同時將被篡改的數據記錄到日誌中。該功能實作很簡單,在記憶體頁面釋放free_page流程或者分配alloc_page流程都會呼叫到kernel_poison_page(),只是呼叫傳參不同,以表示當前動作是釋放記憶體頁面還是分配記憶體頁面,然後分別呼叫註毒和解毒函式。所有的格式化和檢測上報功能都是在該函式內完成。
30、如何降低頁面分配的可預測性?
當kernel_init()之時,在呼叫kernel_init_freeable()當中透過shuffle_free_memory()對所有空閑記憶體頁面連結串列的記憶體頁進行擾亂。采用的是Fisher-Yates shuffle洗牌演算法,核心思想是從1到n之間隨機一個數與第1個數交換,然後從2到n之間隨機一個數與第2個數交換,如右側圖所示的順序進行洗牌擾亂。可以透過配置項CONFIG_SHUFFLE_PAGE_ALLOCATOR開啟頁面分配隨機化該功能,除此之外還可以透過介面檔shuffle進行設定,該介面檔將會呼叫到page_alloc_shuffle()函式進行設定。不過這頁面擾亂是5.2以後版本才有的特性。
31、如何防範記憶體泄密?
記憶體頁面提供了分配前或者分配後對記憶體重設的功能,以防止UAF攻擊。當記憶體頁面分配返回前,將會呼叫want_init_on_alloc()函式,該函式將會判斷init_on_alloc變量是否為true,如若開啟將會對分配的記憶體進行為0的格式化,該功能可以透過CONFIG_INIT_ON_ALLOC_DEFAULT_ON配置項控制。記憶體格式化?這個聽起來和前面提到的poison pages很相似?是的,實作上是相近的,但是該功能不會對記憶體進行檢測,僅是格式化而已。此外該功能與poison page相沖突,如果poison page開啟,此功能失效。同樣,want_init_on_free()則是在記憶體頁面釋放時透過want_init_on_free()判斷檢測init_on_free變量,對應配置項為CONFIG_INIT_ON_FREE_DEFAULT_ON。此外也可以透過kernel的啟動參數init_on_alloc和init_on_free進行控制。
32、如何檢視Buddy管理演算法下的記憶體型別資訊?
對此,我們可以透過/proc/pagetypeinfo介面檔進行檢視。透過該檔,可以看到各個node的zone下面,以型別劃分,從0到10為階的頁面大小的統計情況。同時還提供了匯總數據。
33、小塊記憶體空間如何分配管理?
小塊記憶體采用的是slab演算法。slab演算法共有三種:SLAB、SLUB、SLOB,原因是SLAB最早出現,而SLOB和SLUB是後面出現的,但是繼承了SLAB的介面定義,所以現在都傾向於對該型別記憶體演算法稱為slab,實際上各有所長。SLAB是最早出現的分配演算法,記憶體塊管理采用的是紅黑樹;而SLOB是針對嵌入式場景而最佳化的,資源開銷最小;至於SLUB則是現在主流演算法,是針對SLAB的改良。三種演算法的介面統一,也就意味著不能共存,內核編譯時可以透過配置選項來控制選擇何種演算法。而slab的分配出來的記憶體被稱之為object物件。
34、SLUB如何管理記憶體的?
Slub分配管理中,每個CPU都有自己的緩存管理,也就是kmem_cache_cpu數據結構管理;而每個node節點也有自己的緩存管理,也就是kmem_cache_node數據結構管理。分配的時候,如果CPU的緩存存在滿足條件的freelist空閑連結串列不為空時,則直接取出一個物件分配出來。如果CPU緩存為空,那麽先會向buddy演算法申請記憶體頁面,接著將分配的記憶體頁面空間分割成一個個物件並放入到node節點中,然後填充CPU緩存,最後再從CPU分配出去。但是釋放流程就復雜多了,它需要考慮到釋放的物件和CPU的緩存物件是否來自同一個記憶體頁面,然後放到CPU緩存還是還回到node節點中,而且還需要考慮緩存物件過多時往buddy演算法歸還記憶體的情況。所以釋放流程實作會復雜一些,這裏就不展開了。總而言之,SLUB、SLOB、SLAB就是一個批發零售商的角色,從buddy演算法中批發記憶體然後零售。
35、如何檢視slab資訊?
可以透過cat /proc/slabinfo來檢視slab資訊。
36、如何防範slab空閑連結串列的攻擊?
Slab空閑連結串列freelist的指標加上隨機掩碼保護,以防止對freelist的攻擊利用。主要實作是在由slab的分配介面slab_alloc()和釋放介面slab_free()均會呼叫到的freelist_dereference()函式進去間接呼叫到freelist_ptr()裏面完成。透過encrypt_ptr = ptr ^ random ^ swap(&ptr)演算法完成加密,其中random數值來自於slab建立時生成的隨機數,所以各個slab池各不相同。由此隱藏了slab空閑連結串列上的真實指標值,避免slab空閑連結串列的利用攻擊。
37、SLUB分配如何防止被預判?
除了slab的freelist連結串列的地址隱藏外,其實還有連結串列的隨機化,用於防止被預測攻擊。在初始化之時,init_cache_random_seq()透過構造slab的map陣列,擾亂陣列編號,再乘以slab的大小構造成slab池的offset地圖。然後到了建立新slab池之時,則會在shuffle_freelist()中將透過隨機數從map陣列中隨機挑選一個作為freelist的頭部,繼而由此往後遍歷,將所有塊串到一塊去。如右圖所示。該功能可以透過配置項CONFIG_SLAB_FREELIST_RANDOM控制開啟。但僅限於擴充套件slab池的隨機化,最早初始化建立slab池的時候是沒有隨機化功能的。
38、kmalloc和kfree如何實作的?
kmalloc和kfree實際上是沒有管理演算法實作的,它只是實作了統一化入口,提供豐富的控制參數,便於內核開發者使用。對於小於KMALLOC_MAX_CACHE_SIZE的記憶體,將會透過slab演算法申請,否則都會進入到page頁面分配流程,即buddy演算法管理的物理頁面。
39、kernel的記憶體泄漏如何定位?
大概在2.6之前的內核版本,就已經存在一個記憶體泄漏檢測機制,稱之為kmemleak,相應的配置選項為CONFIG_DEBUG_KMEMLEAK。該功能旨在用於定位kernel記憶體泄漏問題,它的實作主要是透過記憶體分配時,創造相應的跟蹤塊,以紅黑樹的管理方式進行管理。觸發檢測時,將會遍歷內核記憶體空間,判斷記憶體記錄的地址數據是否與紅黑樹中記錄的記憶體地址相匹配,無匹配的記憶體則為疑似泄漏記憶體。整個實作與Java的垃圾回收機制中的記憶體檢測相似,但對kernel而言,該功能僅檢測不回收。
40、kernel有記憶體檢測機制嗎?
除了記憶體泄漏檢測機制kmemleak還有別的檢測機制嗎?有的,就是KASAN,Kernel Address Sanitizer,動態記憶體檢測機制。透過對分配的記憶體空間構造影子記憶體,即與分配的記憶體大小相同且有一一對應關系的記憶體空。透過偏移量KASAN_SHADOW_OFFSET即可存取到影子記憶體。透過申請和釋放時對影子記憶體註毒,也就是使用代表記憶體分配和釋放狀態的不同值來格式化影子記憶體,而在memset()、memmove()、copy_from_user()等介面中透過check_memory_region()對影子記憶體的註毒數據進行辨識當前記憶體操作錯誤型別。例如拷貝的記憶體是否為已釋放的記憶體,如果是,則表示可能發生了越界或UAF。這裏影子記憶體主要針對記憶體頁面及slab記憶體,當然還可以透過__asan_register_globals()去擴充套件到對全域變量的檢測。
41、支離破碎的記憶體如何得到大塊連續記憶體?
vmalloc的實作主要是透過 get_vm_area_node()從vmalloc空間中分配出一個空間大小相匹配的vm_struct結構虛擬地址空間,然後透過 vmalloc_area_node()迴圈申請頁面填滿申請的空間並將物理頁面和虛擬地址空間對映起來,由此完成分配。vmalloc的管理核心結構為vmap_area,該結構既有成員變數rb_node處於紅黑樹中,又有成員變數list在連結串列中,雙管理結構。其中連結串列在舊版本演算法中還起到輔助尋找虛擬地址空間的作用,現在最新版本已經淪為查詢時候遍歷的連結串列了。為了方便尋找空閑的虛擬地址空間,新增了free_vmap_area_root,它是管理空閑虛擬地址空間的紅黑樹。分配虛擬地址空間的時候,將會從free_vmap_area_root尋找合適的空間,然後插入到vmap_area_root紅黑樹中和vmap_area_list中。
42、如何檢視vmalloc資訊?
可以透過cat /proc/vmallocinfo來檢視vmalloc資訊。
43、Percpu記憶體空間如何管理的?
為什麽需要有percpu記憶體空間呢?這是針對CPU的緩存設計而來的,從主記憶體到CPU有多級緩存,對各個CPU而言,有獨占的緩存也有共享的緩存,如果要是對共享記憶體進行修改的話,那麽硬體需要去使其他CPU上對應的緩存進行失效處理,由此對效能影響較大,尤其是一些CPU自己使用的私有變量。故此設計了percpu變量及記憶體,目的就是降低cache失效的頻率,從而提高效能。那麽這些percpu記憶體空間如何管理?它們是透過給定義為percpu的變量劃分到統一段中,該段空間用 per_cpu_start及 per_cpu_end標明了起始位置,然後系統初始化時給每個CPU分配相同大小的記憶體空間作為每個CPU的私有記憶體空間。使用固定偏移__per_cpu_offset[*]的方式,即可存取到某CPU的自有獨立數據變量。執行的時候,原始的percpu變量定義空間數據僅初始化時設定過而已,後面基本上是不會變的。
44、從proc介面還可以看到什麽?
可以看到的分別有meminfo、vmstat、zoneinfo等資訊。
45、容器的記憶體如何管理?
cgroup對記憶體的管理關鍵是mem_cgroup結構體。該結構體承載了對容器記憶體使用的各項約束規格數據。本質上沒有特別的管理演算法,僅僅是記憶體分配過程中增加了額外的檢查。cgroup和css_set是多對多關系,cgrp_cset_link連結串列將兩者關聯起來。一個cgroup可以有多個行程,一個行程也可以加入多個cgroup中。而mem_cgroup是cgroup的一個子系統,並且一個cgroup只能掛載一個子系統,但子系統卻可以被掛載到多個cgroup中,前提是這些cgroup只能有這麽一個子系統。由此就誕生了如此的關聯關系。
46、內核如何防範資訊外泄?
透過增強內核態到使用者態以及使用者態到內核態的記憶體拷貝操作時的檢查,可以有效地降低堆疊溢位攻擊和kernel記憶體暴露的風險。其中check_object_size()作為一個入口,在多個跨使用者態內核態的操作函式中存在呼叫點,例如:strncpy_from_user()、check_copy_size()、 copy_from_user_inatomic()、 copy_from_user()、 copy_to_user_inatomic()及 copy_to_user()。其中該功能最終實作防護判斷的是__check_heap_object()函式,該函式主要辨識拷貝的記憶體是否為不合理地址範圍、是否完全處於slab物件範圍內,如果存在越界的情況將會中止拷貝。
47、實體記憶體頁面耗盡了如何處理?
記憶體頁面實際分配大部份是在缺頁異常中處理,或者直接的alloc_pages分配頁面。當記憶體頁面不足時,將會觸發OOM機制,它透過select_bad_process()中的演算法選擇最佳的行程,然後使用oom_kill_pages()將對應行程kill掉,騰出其占用的記憶體以繼續記憶體分配。
48、內核程式碼段如何進行自我防護?
內核啟動start_kernel()執行完畢即將結束的時候,可以透過mark_readonly()函式對 stext到 etext標識的程式碼段以及 start_rodata到 init_begin標識的唯讀數據段的記憶體空間設定為唯讀,由此防範堆執行以及程式碼段修改等型別的安全漏洞。該功能可以透過CONFIG_STRICT_KERNEL_RWX配置項進行開啟,但是它同時也限制了內核的軟體斷點,所以需要使用kdb的情況下需要關閉該功能。
49、內核程式碼段如何防護註入?
對內核程式碼段和唯讀數據進行記憶體唯讀保護設定mark_rodata_ro()收尾的時候,有一處debug_checkwx()函式呼叫,它將會對已經做了對映並且非系統程式的記憶體進行可寫可執行檢測。如果檢測到存在該型別記憶體空間,將會記錄至dmesg中。這裏檢測到此類記憶體空間的存在,並不表示該記憶體空間一定是一個安全漏洞,但是一個潛在的安全風險。該功能的作用主要是及早暴露這些易於被利用的未修復的內核模組。該功能由CONFIG_DEBUG_WX配置項控制開啟,且依賴於前面講述的CONFIG_STRICT_KERNEL_RWX文本及唯讀數據的唯讀設定。
50、kernel程式空間能否再壓榨?
為了盡可能地壓縮kernel程式占用的記憶體空間,內核設計了 init及 initdata內容定義,用於那些僅在系統啟動過程中才會使用到的函式和數據,例如start_kernel(),僅在系統啟動時使用,後面就廢棄了。透過使用編譯連線指令碼將這類函式及數據分別劃入到.init.text及.init.data段,並使用 init_begin和 init_end將其標識出來。然後在初始化的收尾階段,透過free_kernel_image_pages()將其釋放給系統記憶體,歸入到buddy演算法的管理當中。
51、面向使用者態程式,內核提供了哪些記憶體分配介面?
提供的介面主要由brk、sbrk、mmap以及munmap等。詳情參考圖文。
52、brk介面實作了什麽?
brk()介面是將緊挨著數據段.data的最高地址brk指標往高地址推,但僅僅是擴充套件了虛擬記憶體空間而已,並未實際對映,僅當對記憶體操作存取時,觸發缺頁異常才進行實質上的實體記憶體分配。
53、mmap介面實作了什麽?
mmap()則是在行程的虛擬地址空間(棧和堆中間,被稱為檔對映區域的地方)找到一塊空閑的虛擬記憶體空間。但同樣僅是分配了虛擬地址空間,並沒有實際對映實體記憶體,仍是由缺頁異常進行分配。
54、使用者態記憶體如何管理?
Glibc記憶體管理采用的是ptmalloc演算法,源自dlmalloc演算法演變而來,支持多執行緒及快速分配等。詳情後續獨立文章分析,這裏不展開。
55、glibc對brk和mmap如何使用?
1.malloc介面對於小於M_MMAP_THRESHOLD設定大小的記憶體分配,是透過brk來完成的;
2.malloc申請記憶體大小觸發的brk分配記憶體並非按照實際申請的記憶體大小來分配的,通常會分配得更大一些,而後每次的brk分配的空間會根據連續申請的情況調整,目的是減少系統呼叫次數,提高記憶體利用率;
3.如果malloc申請的記憶體超過M_MMAP_THRESHOLD設定大小,將會透過mmap從記憶體中分配。
56、如何檢視行程記憶體對映資訊?
透過/proc/<pid>/maps可以檢視到行程虛擬地址空間的對映以及對應許可權,但是也僅是能看到虛擬地址空間而已,並不能夠知道實體記憶體占用了多少,有多少記憶體頁面是已經對映了的。而/proc/<pid>/maps_files目錄下的檔則是對應於maps檔的對映,可以透過各個檔檢視到各塊虛擬記憶體的內容數據,不過有一點值得註意的是檢視檔對映是可以全部都看到的,但是看到的也不是表示它已經對映了,這是介面讀取檔的功勞。
57、如何檢視行程記憶體占用實際情況?
對此,可以檢視/proc/<pid>/numa_maps介面檔,該檔是基於maps的擴充套件,用於顯示每個對映的記憶體的位置、繫結策略以及記憶體使用的頁面數量。
58、如何檢視行程記憶體片段對映詳情?
參考圖文。
59、如何檢視行程記憶體對映匯總資訊?
參考圖文。
小結一下
粗略演示了一下內核啟動過程對記憶體的構建流程。
詳細流程圖等後續豐富內容後再補充。
如何學習linux內核?
- 第一階段: 先形成整體輪廓,比如對Linux的行程、記憶體、I/O、驅動模型有一些基本的認識,開始寫一些簡單的內核模組,比如hello-world模組、globalmem、globalfifo這樣的字元驅動,你一定要動手。這個時候你可以看的書是【Linux內核設計與實作】,還有驅動的書。
- 第二階段:從事具體的工作,在某個子系統(無論是行程、記憶體、IO還是驅動)從事工作,加新的功能,修bug,發patch,加深對知識的理解。這階段你如果有興趣,也有耐心,可以讀【深入理解Linux內核】、【深入Linux內核架構】這樣的書,不過懶得看也沒有關系,因為你工作的時候,會自然而然地自己進行代分碼析。
- 第三階段(回歸第一階段):你已經工作了一段時間,寫了一些程式碼,修復了一些bug,送出了一些patch,然後你重新回來叠代整體的知識框架,搞清楚各個子系統內在的聯系。這階段你如果有興趣可以讀【深入理解Linux內核】、【深入Linux內核架構】這樣的書,不過懶得看也沒有關系,因為你的工作讓你自己有了分析的能力。
- 第四階段(回歸第二階段):從事具體的工作,在某個子系統(無論是行程、記憶體、IO還是驅動)從事工作,加新的功能,修bug,發patch,加深對知識的理解。這階段你如果有興趣可以讀【深入理解Linux內核】、【深入Linux內核架構】這樣的書,不過懶得看也沒有關系,因為你的深入的工作,會讓你自己具備了理清脈絡和深入細節的能力。











