小明 發自 凹非寺量子位 | 公眾號 QbitAI
AI玩黑神話,第一個精英怪牯護院輕松拿捏啊。
有方向感,視角也沒有問題。
躲閃劈棍很絲滑。
甚至在打鴉香客和牯護院時,AI的勝率已經超過人類。
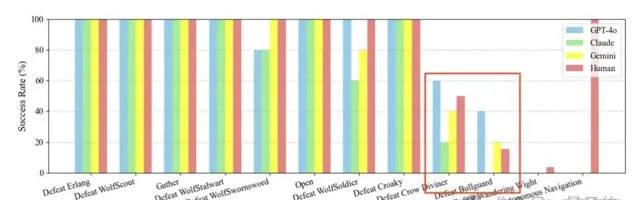
而且是完全使用大模型玩,沒有使用強化學習。
阿裏巴巴的研究人員們提出了一個新型VARP(視覺動作角色扮演)智慧體框架。
它能直接將遊戲截圖作為輸入,透過視覺語言模型推理,最終生成Python程式碼形式的動作,以此來操作遊戲。
以玩【黑神話·悟空】為例,該智慧體在90%簡單和中等水平戰鬥場景中取勝。
GPT-4o、Claude 3.5都來迎戰
研究人員以【黑神話·悟空】為研究平台,一共定義了12個任務,75%與戰鬥有關。

他們構建了一個人類運算元據集,包含鍵鼠操作和遊戲截圖,一共1000條有效數據。
每個操作都是由原子命令的各種組合組成的序列。原子命令包括輕攻、閃避、重攻擊、回血等。
然後,他們提出了VARP智慧體框架。
主要包含動作規劃系統和人類引導軌跡系統。
其中動作規劃系統由情境庫、動作庫和人類引導庫組成,利用 VLMs 進行動作推理和生成,引入分解特定任務的輔助模組和自我最佳化的動作生成模組。
人類引導軌跡系統利用人類運算元據改進智慧體效能,對於困難任務,透過查詢人類引導庫獲取相似截圖和操作,生成新的人類引導動作。
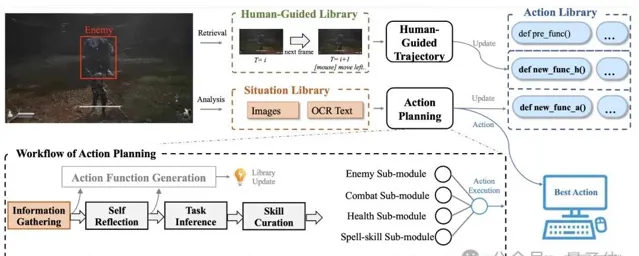
同時VARP還包含3個庫:情景庫、動作庫和人工引導庫。
這些庫中儲存了agent自我學習和人類指導的內容,可以進行檢索和更新。
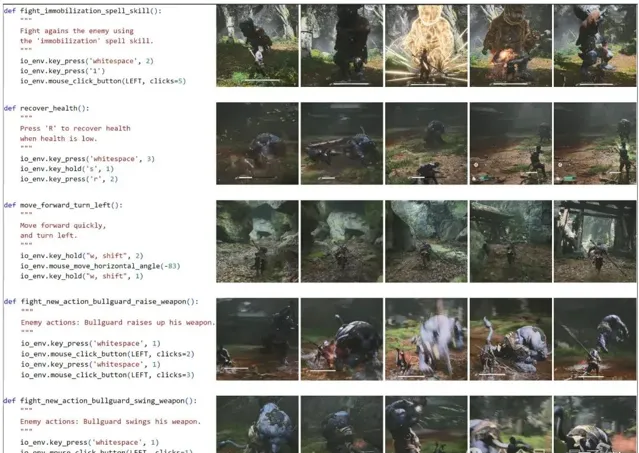
動作庫中,「def new_func_a()」表示動作計劃系統生成的新動作,「def new_func_h()」表示人導軌跡系統生成的動作。」def pre_func()」代表預定義的動作。
動作案例研究和相應的遊戲截圖。第一行和第二行中的操作是預定義的函式。第三行動作由人工制導軌跡系統生成。
SOAG會在玩家角色與敵人的每次戰鬥互動後總結第四行和第五行中的新動作,並將其儲存在動作庫中。
框架分別使用了GPT-4o(2024-0513版本)、Claude 3.5 Sonnet和Gemini 1.5 Pro。
對比人類和AI的表現結果,可以看到小怪部份AI們的表現達到人類玩家水平。
到了牯護院時,Claude 3.5 Sonnet敗下陣來,GPT-4o勝率最高。
但是對於新手玩家普遍頭疼的幽魂,AI們也都束手無策了。
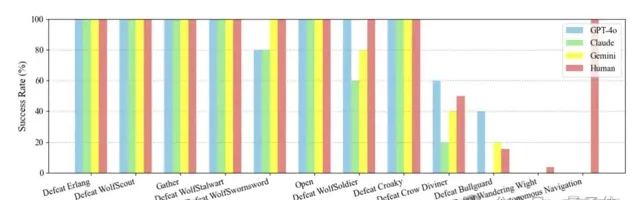
另外研究還提到,由於VLMs推理速度受到限制,是無法即時輸入每一幀畫面的。它只能間隔輸入關鍵幀,這也會導致AI在一些情況下錯過boss攻擊的關鍵資訊。
以及由於遊戲中沒有明確的道路引導且存在很多空氣墻,在沒有人類引導下,智慧體也不能自己找到正確的路線。
如上研究來自阿裏團隊,一共有5位作者。

後續相關程式碼和數據集有釋出計劃,感興趣的童鞋可以蹲下。
One More Thing
AI打遊戲並不是一個新鮮事了,比如AI基於強化學習方法打【星際爭霸II】已經可以擊敗人類職業高手。
利用強化學習方案,往往需要輸入大量對局。商湯此前訓練的DI-star(監督學習+強化學習),就用了「16萬場錄像」和「1億局對戰」。
但是純大模型也能打遊戲,還是很出乎意料的。在本項研究中,數據集中的有效數據為1000條。
論文地址:https://arxiv.org/abs/2409.12889
計畫地址:https://varp-agent.github.io/











