
证明自己不是机器人,几乎是每个网络冲浪人的日常小考。
有太多这样的瞬间:你正在网上订票,准备支付时,界面出现一个弹窗要求你确认你是人类:

为了给程序证明我不是程序 ——
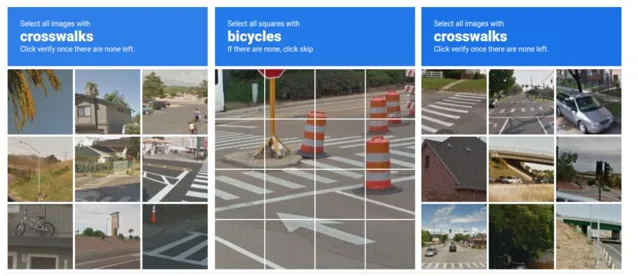
你在5秒内找出了所有的十字路口,
在3秒内点击了混在草丛后的自行车,
以超过全民85%的速度把滑块移到了正确的位置……
最终,以人类身份光荣地通过了系统的考验!
那么,这个验证是如何判断区分真实人类的?机器人难道就无法勾选「我不是机器人」的复选框吗?
首先,我们来介绍一下这场人机战的关键裁判—— reCAPTCHA。
01
什么是reCAPTCHA
reCAPTCHA是Google开发的一种安全机制,核心任务就是区分真人用户和自动化程序(比如「爬虫」或机器人等)———
每当你在网上点击那个「我不是机器人」的小方框,就是在参与一场人机较量
。
reCAPTCHA就是较量中的裁判,通过用户的点击进行判断,把恶意程序挡在门外,确保只有真正的用户才能通过。

02
reCAPTCHA的演变历程
reCAPTCHA最早诞生在20年代初期,随着互联网的兴起,网络开始面临越来越多的垃圾信息和恶意程序的威胁。当时,卡内基梅隆大学的路易斯·冯·安(Luis von Ahn)在研究恶意程序防御时开发了reCAPTCHA。
这种技术最初通过让用户识别扭曲的文字或图像,来验证其是否为人类。
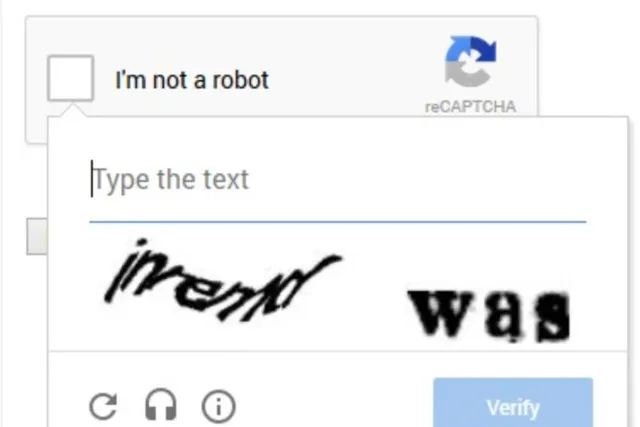
比较典型的验证
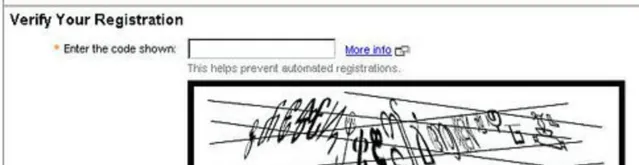
偶尔也会遇到特别离谱的……
研究过程中,冯·安意识到这项技术还可以应用于帮助转录旧手稿。为此,冯·安进一步改进了reCAPTCHA:不仅使用验证码,也同时把老旧文档文献中的单词展示给用户,借助用户的验证过程完成标注,助力历史文献的数字化。(这些文献中的字迹仅靠光学字符识别系统(OCR)无法很好地识别)

reCAPTCHA的使用大大减少了人工手动转录文献的工作量。
目前已有约5万个网站在使用它进行身份验证,每天帮助转录超过1800万个单词。世界头部互联网档案馆(Internet Archive)每天使用reCAPTCHA来数字化多达1000本书籍、报纸和其他文档;【纽约时报】也利用reCAPTCHA来数字化其自1851年以来的档案。
和传统的OCR技术相比,reCAPTCHA在处理旧文档时的准确率高达99%,远远优于OCR在处理19世纪前出版书籍时高达20%的错误率
。
这个方法一开始效果还不错,但随着技术的进步,机器人也慢慢地学会了识别这些扭曲的文字。
于是reCAPTCHA也跟着进化,从简单的文字识别变成了我们今天看到的「请点击所有有交通灯的图片」之类的图片识别任务,以及让用户勾选「我不是机器人」的方式来完成验证。
谷歌在2009年收购了reCAPTCHA后,把这种技术用到了谷歌书籍和Google Maps等项目,用来改进文字识别和地理数据处理。
(顿悟原来我每次呕心沥血完成验证,都在充当Google的人工标注劳动力

)
那么,reCAPTCHA究竟是如何判断你是人类还是机器人的?
03
验证背后的实现原理
当你点击这个「我不是机器人」的方框时,reCAPTCHA就会根据你的点击行为判断你是否是一个真实的人类。
点击行为分析背后是非常有趣的领域:人机交互(HCI)与行为生物识别(Behavioral Biometrics):通过大量的行为数据分析,从用户的日常操作中提取出生物行为特征,与机器人的行为对比。
识别的关键并不在于你是否能在框中完成点击,而在于
你
点击的动作。
reCAPTCHA通过分析你点击的速度、鼠标的轨迹,以及你在页面上的一些小动作来判断你到底是不是人类。
人在操作鼠标时,手指总是会有些许抖动的。移动路径可能会有一些小弯曲或停顿、速度时快时慢、点击前随着阅读思考有小片刻停顿,或是在点击后追加一些惯性动作。这些微小的变化通常会比机器人更自然。
而机器人则趋向于完美的直线和精准的点击。
大量行为数据分析发现,机器人虽然能快准狠地点击目标,但它们的动作太「完美」,不像人类的随意:鼠标的移动路径通常是最短的直线,点击速度也十分一致。
这种差异是用来识别人类和机器人的关键。
(原来我胜出是因为菜…)

04
人类vs机器的移动轨迹
Castle(一家专注做账户安全和欺诈检测的公司)的研究员Johan Brissmyr通过记录鼠标在网页上的位置,展示了人机两种截然不同的移动轨迹:包括瞬间跳跃、直线移动和贝塞尔曲线:
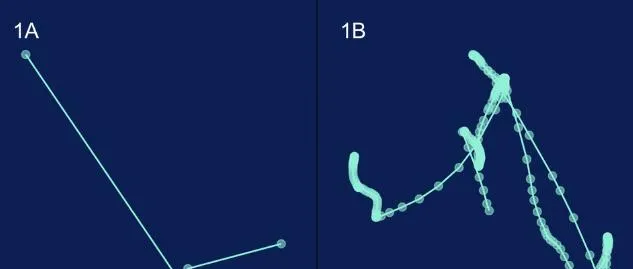
可以看出,模拟生成的自动化程序通常会通过直接指定坐标的方式移动鼠标,导致不自然的轨迹,如瞬间跳跃或直线移动(1A)。
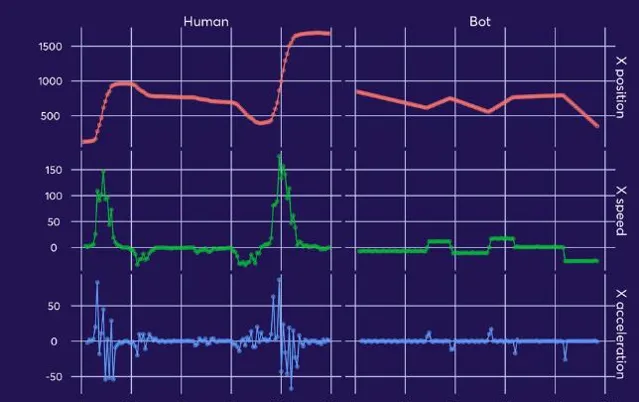
通过移动速度和加速度的分析比对,也可以发现机器人轨迹中的加速度通常接近于零
,这是识别人机的关键。
人类日常点击鼠标时,随着手腕手指的发力,鼠标的移动轨迹会产生加速度变化。而自动化程序的鼠标移动通常是以恒定速度沿直线完成,加速度接近零。
针对行为分析的结果,系统会为每个用户生成一个「信誉评分」(score)。这个评分从0.1到1不等。分数越高,说明系统越相信你是个真真切切的人类;分数越低,系统就会更加警觉,甚至可能要求你进行进一步验证。
05
多模态验证:运动轨迹+图像识别
当用户点击太快或轨迹过于「机器人」时,系统给出的低分会触发更复杂的视觉验证,比如让用户选择含有摩托车或街灯的图片,或甚至语音、视频的验证。
系统展示的验证图片一般会具有一定的模糊性或复杂性,这种多角度的物体识别对自动程序来说挑战比较大。因为物体从不同角度看,轮廓、光影会发生变化,会导致识别难度大大增加。
而电脑程序主要根据平面图像来理解三维物体,如果训练数据不够全面,就可能无法准确识别在特定角度下的物体。人类的大脑则天然擅长处理这些变化,
即使图片质量不高或角度怪异,也能迅速识别出目标物体。
06
不停歇的攻防战:reCAPTCHA的持续进化
道高一尺,魔高一丈。
随着人工智能技术的迅猛发展,机器人不仅能执行点击任务,也能逐渐通过复杂的算法模仿人类行为。防御与攻击相互推动,像一场无休止的猫鼠游戏。每一步都要求防御系统不断进化,以应对愈加精巧的对抗性AI。
end
参考文献:
(上下滑动可浏览)
1. Google Developers. (n.d.).
https://developers.google.com/recaptcha
2. Google Security Blog. (2018).
https://security.googleblog.com/2018/10/introducing-recaptcha-v3-new-way-to.html
3. Cloudflare. (n.d.).
https://blog.cloudflare.com/a-brief-history-of-recaptcha/
4. TechCrunch. (2017, March 9). :
https://techcrunch.com/2017/03/09/googles-invisible-recaptcha/
5. The Verge. (2018, October 29).
https://www.theverge.com/2018/10/29/18037354
6.
Brissmyr, J. (2020, December 9). Castle Blog: https://blog.castle.io/author/johan/
来源:DataCafe
原标题:am I a robot? 机器人验证背后的原理
编辑:ArtistET











