今天分享的是算力专题研究二:【从训练到推理:算力芯片需求的华丽转身】, 幻影视界整理分享摘要内容如下:
一、 如何测算文本大模型 AI 推理端算力需求
推理算力市场已然兴起, 24年AI 推理需求成为焦点。 据 Wind 转引英伟达FY24Q4 业绩会纪要,公司 2024 财年数据中心有 40%的收入来自推理业务。
放眼国内,IDC 数据显示,我国 23p 训练工作负载的服务器占比达到 49.4%,预计全年的占比将达到 58.7%。随着训练模型的完善与成熟,模型和应用产品逐步投入生产,推理端的人工智能服务器占比将随之攀升,预计到 2027 年,用于推理的工作负载将达到 72.6%。
英伟达
FY2024数据中心推理与训练占比
中国人工智能服务器负载及预测

如何量化推理算力需求?与训练算力相比,推理侧是否具备更大的发展潜力?我们整理出 AI 推理侧算力供给需求公式,并分类讨论公式中的核心参数变化趋势,以此给出我们的判断。

需要说明的是,本文将视角聚焦于云端 AI 推理算力,端侧AI 算力主要由本地设备自带的算力芯片承载。基于初步分析,我们认为核心需要解决的问题聚焦于需求侧——推理消耗的数据规模如何测算?而供给侧,GPU 性能提升速度、算力利用率等,我们认为与 AI 训练大致无异。
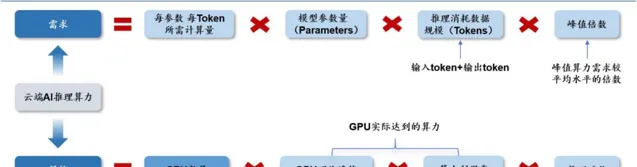
文本大模型云端 AI 推理算力供给需求公式
二、 Scaling Laws& 长文本趋势:推理需求的核心驱动力
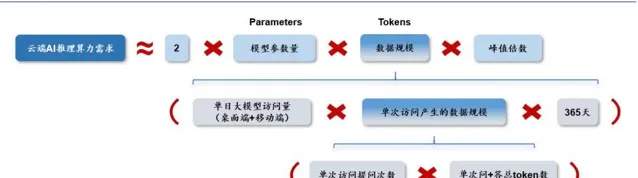
根据 OpenAI【Scaling Laws for Neural Language Models】,并结合我们对于推理算力的理解, 我们拆解出云端 AI 推理算力需求 ≈2× 模型参数量 × 数据规模 × 峰值倍数 。
云端 AI 推理需求公式拆解

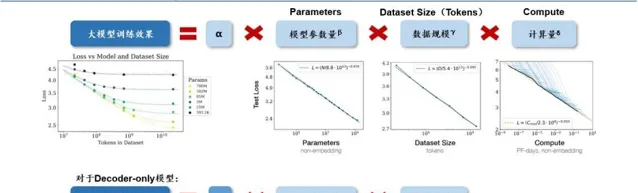
模型的最终性能主要与计算量、模型参数量和数据大小三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。如下图所示,对于计算量、模型参数量和数据规模,(1)当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系。(2)如模型的参数固定,无限堆数据并不能无限提升模型的性能,模型最终性能会慢慢趋向一个固定的值。
因此,为了提升模型性能,模型参数量和数据大小需要同步放大。
Scaling Law
仍然是当下驱动行业发展的重要标准
。
大模型训练的 Scaling Law
过去几年来
AI
大模型参数量呈现快速增长。
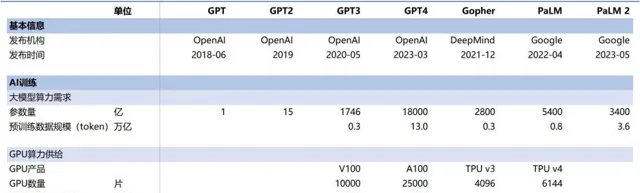
以 OpenAI 为例,GPT-3 到 GPT-4 历时三年从 175B 参数快速提升到 1.8T 参数(提升 9 倍)。目前国内主流 AI 大模型也逐步突破了千亿参数大关,乃至采用万亿参数进行预训练。
海外主流
AI 大模型训练侧算力供给需求情况
国内主流 AI 大模型训练侧算力供给需求情况

云端 AI 推理需求公式进一步拆解
从大模型访问量来看, 我们认为需要覆盖到不同流量入口的访问量之和,包括(1)桌面端,(2)移动端。由于 Similarweb 数据统计了桌面端+移动端所有流量之和,我们以此为基础测算推理应用产生的 token 数据规模。
文本大模型网站访问量周度数据(单位:万次)文本大模型网站访问量周度数据(单位:万次)
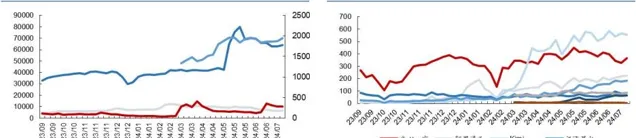
从单次访问产生的数据规模来看,运算公式可以拆解为单次提问的问题与答 案所包含的 token 数总和乘以单次访问提出的问题数,其中单次问答所包含的 token 数取决于字数&每个字对应的 token 数。
(1)字数:单次问答所包含的字数或多或少会受到大模型上下文窗口(Context Window)的限制。随着上下文窗口瓶颈的快速突破,长文本趋势成为主流。以 OpenAI 为例,从 GPT-3.5 升级至 GPT-3.5-Turbo,上下文窗口从 4k 升级为 16k;而 GPT-4 版 本时隔一年后升级为 GPT-4-Turbo,也将上下文窗口从 32k 提升至 128k。而以长文本 能力成为「顶流」的 Kimi,2023年10月上线时支持无损上下文长度最多为20万汉 字,24年3月已支持200万字超长无损上下文,长文本能力提高10倍。按照AI领 域的计算标准,200万汉字的长度大约为400万token,在全球范围内也属于领先的标准。
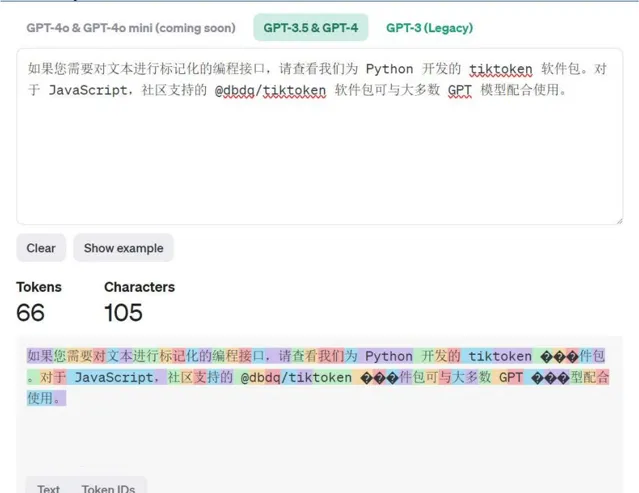
(2)每个字对应的 token 数:不同的大模型均有各自的分词器设计,以 OpenAI 为例,1000 个 token 通常代表 750 个英文单词或 500 个汉字。以其官网 Tokenizer 计 算工具结果来看,基本与此结论相契合。
OpenAI Platform Tokenize r
三 、 文本大模型云端 AI 推理对 GPU 的需求量如何求解?
本文按第一章所示「文本大模型云端 AI 推理算力供给需求公式」,逐步拆解计算过程。首先,测算 AI 大模型推理所需计算量,随后通过对单 GPU 算力供给能力的假设,逐步倒推得到 GPU 需求数量。我们发现当前 OpenAI 在全球范围内的访问量仍然断层领先,由此我们推断 OpenAI 在全球推理算力需求中占据较大比重,因此本文测算以 OpenAI 为例。
1. 云端 AI 推理算力需求
1.1每参数每 token 所需计算量:根据 OpenAI【Scaling Laws for Neural Language Models】,并结合我们对于推理算力的理解,我们拆解出云端 AI 推理算力需求≈2× 模型参数量×数据规模×峰值倍数,即每参数每 token 推理所需计算量为 2 Flop。
1.2大模型参数量:根据我们此前外发报告【如何测算文本大模型 AI 训练端算 力需求?】,我们认为 Scaling Law 仍将持续存在,大模型或将持续通过提升参数量、 预训练数据规模(token 数)带动计算量提升,进而提升大模型性能,我们按过往提 升速度大致推断未来增长情况。
1.3数据规模(tokens):从大模型访问量来看,我们以 Similarweb 统计的访问 量数据为测算基础,通过趋势的判断,以及对 AI 推理能力提升带动 AI 应用渗透趋 势的信心,我们预计 24-26 年 OpenAI 访问量有望同比增长 60%/50%/30%。
需要说明 的是,由于 OpenAI 在 Similarweb 统计的访问量数据中以断层优势处于领先地位,我 们认为 OpenAI 在全球 AI 推理需求中占据相当大的比重。从单次访问产生的数据规 模来看,运算公式可以拆解为单次提问的问题与答案所包含的 token 数总和乘以单次 访问提出的问题数,其中单次问答所包含的token数取决于字数&每个字对应的 token 数。
(1)首先,我们假设 23 年大模型单次访问的问答次数为 5 次,随着大模型的使 用频率提高,用户粘性增强,该次数有望稳步提升。
(2)我们假设单次提问一般对 应 30tokens 左右,另外我们取 23 年一次问答实验中 12 次回答的平均字数(523 个汉 字)作为假设,基于 1:2 的换算比例,得到 23 年单次问答产生的 token 数为 1077 字 节。我们假设 24-26 年单次问答产生的 token 数有望跟随大模型上下文窗口的长文本 化趋势,而呈现爆发式增长。
1.4峰值倍数:我们假设 1、推理需求在一日之内存在峰谷,算力储备比实际需 求高,2、随算力应用的进一步泛化,峰值倍数有望逐渐下降。
2. 云端 AI
2.1 GPU 计算性能:根据我们此前外发报告【如何测算文本大模型 AI 训练端算力需求?】,我们假设未来英伟达新产品的 FP16 算力在 Blackwell 架构的基础上延续过往倍增趋势。此外,我们假设训练卡供不应求,由此推断推理需求的实现相较于训练需求的实现或延迟半代,AI 推理侧或以英伟达新一代及次新一代 GPU 为主,我们假设二者各占50%,以其平均 FP16 算力作为计算基准。
2.2 训练时间&算力利用率:我们假设推理应用需求在全年 365 天是持续存在的, 由此假设全年推理时间为 365 天。根据我们此前外发报告【如何测算文本大模型 AI 训练端算力需求?】,我们假设算力利用率在 30-42%区间,逐年提升。
四 、 结论: 若以英伟达当代&前代 GPU 卡供给各占 50%计算,我们认为 2024-2026 年 OpenAI 云端 AI 推理 GPU 合计需求量为 148/559/1341 万张。
OpenAI 云端 AI 推理算力需求-供给测算

综上,我们首先根据前述逻辑测算得到 AI 大模型推理所需要的计算量,随后通过单 GPU 算力供给能力、算力利用率等数值的假设,逐步倒推得到 GPU 需求数量。若以英伟达当代 & 前代 GPU 卡供给各占 50% 计算,我们认为 2024-2026 年 OpenAI 云端 AI 推理 GPU 合计需求量为 148/559/1341 万张。
本文仅供参考,不代表我们的任何投资建议。 幻影视界 整理分享的资料仅推荐阅读,用户 获取的资料 仅供个人学习,如需使用请参阅报告原文。











