OAI新研究:用「博弈」让AI更易懂
人工智能领域的巨头 OAI 于昨日凌晨发布了一项名为「证明者-验证者博弈」(P-V-G)的新研究,旨在解决当前大型语言模型在处理复杂任务时面临的一个关键挑战:可理解性,这项研究的核心理念是通过模拟两个人工智能模型之间的博弈,迫使模型生成更清晰、更易于验证的解决方案,而非仅仅追求答案的正确性

OAI 的研究人员指出,现阶段许多强大的 AI 模型在解决问题时,往往只注重最终结果的准确性,而忽略了推理过程的透明度,这就好比一个学生在考试中直接写出了正确答案,却无法解释解题思路,让人怀疑其答案的可靠性,为了解决这个问题,OAI 的研究人员从小学数学问题的解决思路中汲取灵感,设计了「证明者」和「验证者」这两种角色,并让它们进行模拟博弈
「证明者」与「验证者」:一场AI间的智力角逐
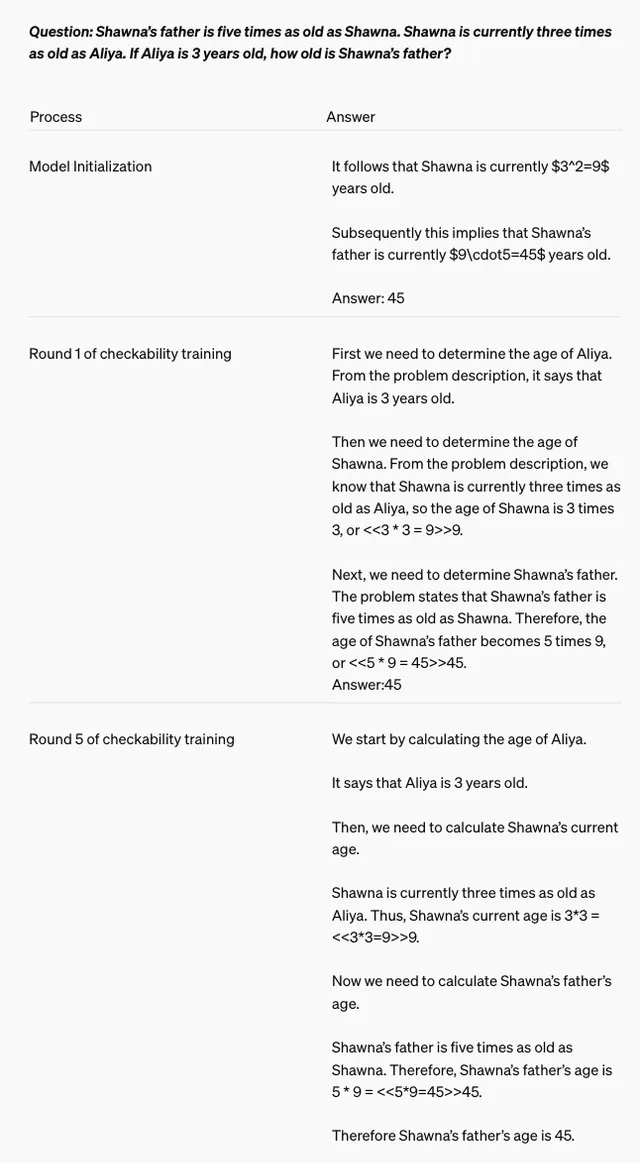
「证明者」的角色类似于解题者,负责生成问题的解决方案;而「验证者」则扮演着类似于老师的角色,负责检查「证明者」所提供解决方案的正确性和清晰度,举例来说,假设我们要解决一个简单的数学问题:「小明的爸爸比小明大 30 岁,小明今年 10 岁请问小明的爸爸多少岁?」

在这个例子中,「证明者」模型可能会生成以下解决方案:「小明的爸爸比小明大 30 岁,小明今年 10 岁,所以小明的爸爸今年 30+10=40 岁,」而「验证者」模型则会仔细检查这个解决方案的每一步推理过程,确保其逻辑清晰、计算准确,如果「证明者」提供的解决方案过于简略或存在错误,「验证者」就会拒绝接受,并要求「证明者」提供更详细、更准确的解释
博弈训练:逼迫AI「说出」思考过程
为了让「证明者」和「验证者」模型更好地协同工作,OAI 的研究人员采用了一种名为「博弈迭代」的训练方法,简单来说,就是让这两个模型进行多轮「交锋」,并在每一轮结束后根据对方的表现调整自身的策略

在训练的初始阶段,「验证者」模型会使用一些已有的数据来学习如何判断「证明者」所生成解决方案的正确性,而「证明者」模型则会尝试生成各种不同的解决方案,并观察「验证者」模型的反应,如果「验证者」模型接受了某个解决方案,那么「证明者」模型就会认为这种解题思路是可行的,并在之后的解题过程中倾向于使用类似的思路
从「狡猾」到「诚实」:训练AI的「道德品质」
有趣的是,OAI 的研究人员在训练过程中还发现了一个有趣的现象:一些「证明者」模型会为了「取胜」而采取一些「狡猾」的策略,例如故意生成一些看似合理但不完全正确的解决方案,以试图欺骗「验证者」模型
为了应对这种情况,研究人员在训练过程中引入了两种不同类型的「证明者」模型:一种是「诚实的证明者」,它们的目标是生成完全正确且易于理解的解决方案;另一种是「狡猾的证明者」,它们的目标是生成一些难以察觉错误的解决方案,以测试「验证者」模型的辨别能力
通过让「诚实的证明者」和「狡猾的证明者」模型相互竞争,研究人员可以不断提升「验证者」模型的识别能力,并最终迫使所有「证明者」模型都放弃「投机取巧」的行为,转而专注于生成真正有价值的解决方案
迈向可解释AI:OAI新研究的意义
OAI 的这项研究为提高大型语言模型的可理解性和可解释性提供了一种全新的思路,通过引入「证明者-验证者」博弈机制,研究人员成功地将模型的优化目标从单纯追求结果的准确性,转向了更加注重推理过程的清晰度和可验证性

这种转变具有重要的现实意义,随着人工智能技术在越来越多的领域得到应用,人们对于 AI 系统的信任度也变得越来越重要,而可解释性正是建立信任的关键因素之一,只有当我们能够理解 AI 系统是如何做出决策的时候,我们才能真正放心地将一些重要的任务交给它们去完成
OAI 的这项研究无疑是朝着可解释 AI 迈出的重要一步,我们期待未来能够看到更多类似的研究成果,最终实现人工智能技术与人类社会的和谐共处
欢迎在评论区留言,分享您对这项研究的看法
【免责声明】文章描述过程、图片都来源于网络,此文章旨在倡导社会正能量,无低俗等不良引导。如涉及版权或者人物侵权问题,请及时联系我们,我们将第一时间删除内容!如有事件存疑部分,联系后即刻删除或作出更改。











