
机器人的新脑袋
有研究者提出将「虫子」脑袋装进机器人里,这一概念在移动机器人领域引起了热议。近几年大模型时代的浪潮下,谷歌的Transformer架构已成为行业主流。然而,一家名为Liquid AI的初创公司,正是由MIT计算机科学与人工智能实验室的前研究人员创建,他们的目标则是突破生成式预训练Transformer(GPT)模型的局限。Liquid AI推出的多模态AI模型「Liquid Foundation Models」(LFM)为此而生,这是一种全新的生成式AI模型,其1B、3B和40B版本在多种条件下都能展现出顶尖的性能,同时显著减少内存占用和提高推理效率。
LFM的惊艳表现
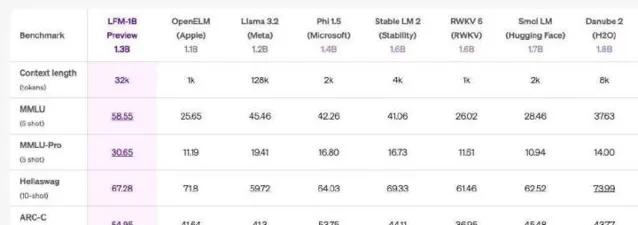
Liquid AI的后训练主管Maxime Labonne在社交媒体上表达了对LFM的自豪感,认为其核心优势在于可以超越传统的Transformer模型,而内存占用则相对较少。这让不少人感到惊喜,有人甚至评论LFM是Transformer的「终结者」。LFM系列中的LFM-1B规模在多项基准测试中表现斐然,获得了最高分,成为同类产品中的佼佼者。
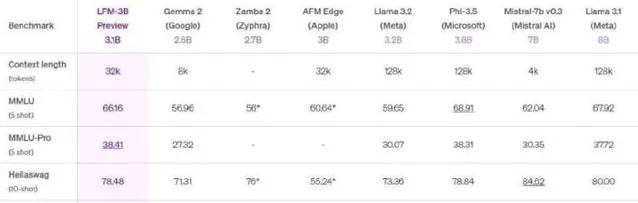
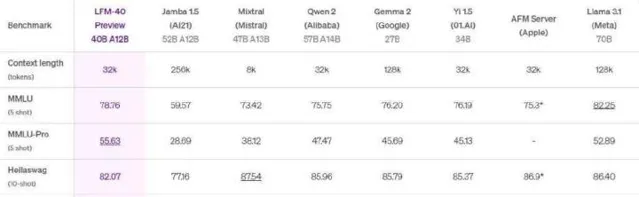
在与Meta的Llama和微软的Phi模型的对比中,LFM 1.3B展现出强大的性能,位居第三方基准测试的顶峰。LFM-3B同样表现优异,在与其他标称为3B的Transformer、混合模型和RNN模型的对比中,表现排名第一。为了适应移动设备及其他边缘文本应用,LFM-3B成为了理想选择,能够在功耗更低的情况下实现更高的效率,而LFM-40B模型则在大小和输出质量之间创造了新的平衡。
内存效率的优势
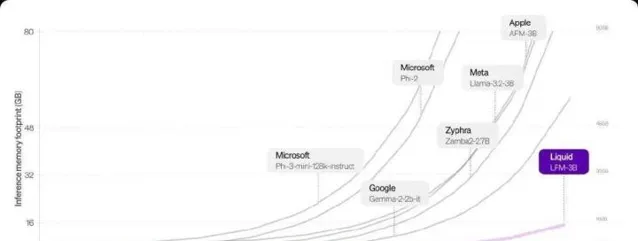
LFM模型在内存占用上显示出显著优势,尤其是在处理较大的输入时。在基于Transformer的模型中,长度越长的序列,内存需求呈线性增长,但LFM通过高效压缩输入可以在硬件上处理更长序列。以LFM-3B为例,它的内存需求仅为16GB,而Meta的Llama-3.2-3B则需要超过48GB。
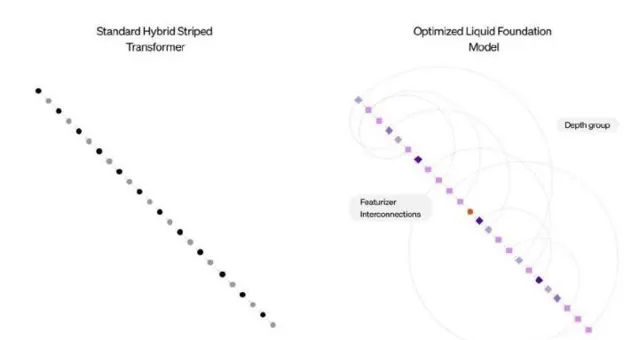
这种内存的高效利用让LFM在长上下文任务中的表现愈发出色。对于开发者来说,这意味着更多的应用场景,比如文档的分析与摘要、与聊天机器人更深入的交互等。Liquid AI的模型不仅在性能基准上与传统模型竞争激烈,同时在操作效率上也为各种应用提供了完美的解决方案。


Liquid AI的颠覆性技术
Liquid AI的发展得益于一系列全新的计算单元,这些单元的设计根植于动态系统理论以及信号处理的基础上。研究显示,传统的深度学习模型往往依赖数千个神经元来完成复杂任务,而Liquid AI的液态神经网络(LNN)证明较少的神经元也能实现相似的效果。LFM保留了这种灵活适应的优势,让推理过程中的调整变得更加高效。
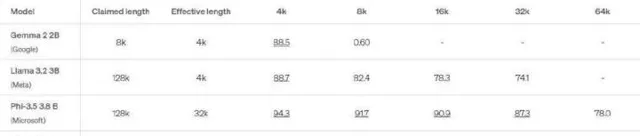
尤其是在处理多达100万个token时,LFM-3B在内存使用上的表现优于不少著名的AI模型。其他模型在处理长上下文时,内存消耗迅速上升,但LFM-3B却保持在较低水平,因此非常适合需要大量顺序数据处理的场景,比如聊天机器人和文档分析。
从线虫到创新
Liquid AI这一创业公司自2023年成立以来,便与OpenAI等其他语言模型公司展开竞争。其创始人之一Daniela Rus是MIT CSAIL的主管,借助其科研背景,团队致力于开发基于生物神经机制的创新技术。秀丽隐杆线虫这一生物模本的研究为Liquid AI打下了基础。
线虫虽然大脑简单,但在复杂行为的学习和适应环境上表现优于现有许多AI系统。受此启发,Liquid AI研发了液态时间常数网络,将神经元工作原理与数值计算结合,形成更为高效的计算模型。这种模型不仅在多个领域展现出其潜力,更因其较小的规模和更高的可解释性而被广泛关注。
小结
Liquid AI的崛起标志着AI领域的一次重要创新,将复杂的生物神经结构与计算机技术相结合。新的液态神经网络在处理效率和内存占用上的优势为未来的应用提供了更广阔的可能性。虽然当前模型尚不完美,但通过持续的优化和用户反馈,它有望在基础模型领域发挥重要作用。希望未来这条来自小虫子的道路能够带来更加惊艳的科技成果!











