近年来,人工智能技术迅猛进步,其在不同领域的应用及性能表现引发了人们的广泛关注,特别是在数学领域,人工智能的应用尤为显著。在这样的背景下,MathEval评估平台的推出成为了一个备受瞩目的焦点,它为大模型在数学解题能力方面的评估提供了一个权威且可靠的衡量标准。这一平台的出现,不仅为评估各类大模型的性能提供了有力的支持,也有助于推动人工智能技术在数学领域的深入应用。

在最近一次MathEval评估中,30种不同的大模型接受了严苛的测试。为了确保评测结果的精准无误与公平公正,评估团队引入了GPT-4这一前沿大模型技术,负责答案的精准提取与匹配工作。这一创新举措有效规避了传统的评测方法可能带来的误差,使得评估结果更具说服力。
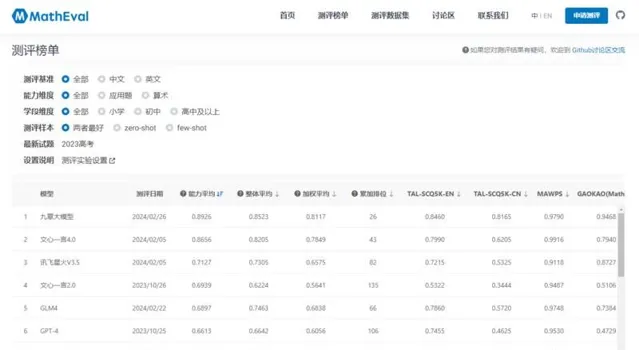
评估结果揭晓,学而思精心研发的九章大模型、百度的文心一言4.0版本以及科大讯飞的星火V3.5版本脱颖而出,荣获前三甲的佳绩。其中,九章大模型的表现尤为亮眼,不仅在中英文处理能力上展现出了卓越的实力,而且在解答不同教育阶段的数学问题上也游刃有余,成为本次评测中耀眼的明星。
MathEval这一平台的出现,源于对数学领域大模型能力评估的迫切需求。随着我国大模型发布数量的激增,目前已超过200个,这些大模型在数学领域的应用日益广泛,涉及数学题目解答、数据分析、学术探索及教育辅导等多个方面。然而,如何准确评估这些大模型在数学领域的具体能力,成为了一个亟待解决的问题。
目前,市面上的评估方法多侧重于模型的通用能力,如推理和自然科学知识等方面,而对于数学能力专门的评估体系却尚未完善。在这样的背景下,由国家智慧教育新一代人工智能开放创新平台携手暨南大学、北京师范大学、华东师范大学、西安交通大学及香港城市大学共同发起的MathEval应运而生,填补了行业空白。
MathEval平台的建立,为大模型在数学解题能力方面提供了一个专业的基准。它不仅关注模型在基础算术方面的表现,更延伸至高级数学问题的处理,从而全面评估大模型在数学领域的综合能力。

自2010年起,MathEval平台已经精心汇聚了19个备受推崇的数学测评数据集,这些宝贵的资源均源自ACL、AAAI、ICLR等众多国际知名人工智能会议的公开数据。这些数据集涵盖了广泛的学段、题型、文本格式以及难度级别的数学问题,为大模型在数学解题能力方面的评估提供了丰富而全面的素材。
这一重要成果的取得,标志着我国在大模型技术应用于数学领域的研究与开发方面迈出了坚实的步伐,彰显了国产大模型在数学问题解决能力上的卓越潜力。展望未来,随着技术的不断进步和优化,相信国产大模型将在更多领域展现其强大的应用价值,成为推动人工智能事业发展的重要力量。











