Excel里面就不太适合做多项式回归了,虽然可以通过散点图进行添加趋势线拟合结果,但是无法判定模型参数的好坏,以及如何选择项数。所以就最好使用编程语言来实现。昨天使用Python实现了,今天补充R语言版本。
多项式回归是一种回归分析方法,它通过使用多项式函数来拟合自变量(输入)和因变量(输出)之间的关系。在多项式回归中,假设自变量和因变量之间的关系可以用一个多项式函数来近似表示。多项式回归的一般形式如下:
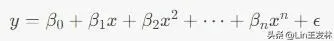
其中,y是因变量,x是自变量,β0,β1,…,βn 是回归系数,ϵ 是误差项。
【多项式回归的优点和缺点】
优点:
- 灵活性:可以拟合复杂的数据模式,包括非线性关系。
- 易于理解和实现:多项式回归模型相对简单,易于解释和实现。
缺点:
- 过拟合风险:高阶多项式可能导致模型在训练数据上过度拟合,而在新数据上表现不佳。
- 计算复杂度:随着多项式阶数的增加,计算复杂度增加。
【使用R语言进行多项式回归模拟】
首先进行数据的生成,为了使用方便,这里就直接在软件里面模拟数据了↓
# 设置随机数种子以确保可重复性set.seed(21)# 生成自变量xx <- runif(100, min = -10, max = 10)# 生成因变量y,假设y与x的关系为二次多项式y <- 2 + 3*x - 0.5*x^2 + rnorm(100, mean = 0, sd = 5)# 将数据存储在数据框中data <- data.frame(x = x, y = y)
先简单绘制一下图形,看一下整体的分布情况↓
# 绘制数据分布图plot(data$x, data$y, main = "广告支出 vs 销售额", xlab = "广告支出", ylab = "销售额", pch = 19, col = "blue")
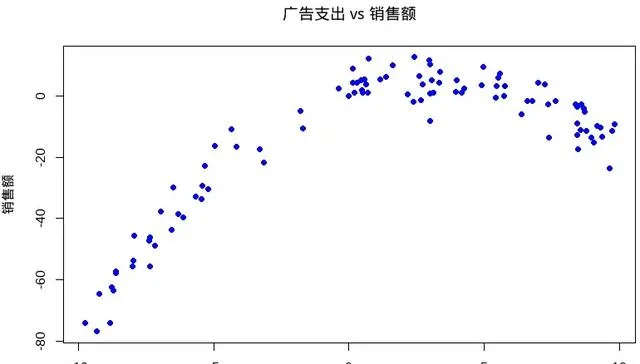
从图形上看,不是直线的相关关系,所以不能直接使用一元线形回归。然后是模型的拟合,还是使用ml函数就行,只是参数需要改成多项,我们这里不知道实际情况的情况下,先使用3次项看一下结构↓
# 拟合二次多项式回归模型model <- lm(y ~ poly(x, 3), data = data)# 查看模型摘要summary(model)
Call:lm(formula = y ~ poly(x, 3), data = data)Residuals: Min 1Q Median 3Q Max -13.4946 -3.2138 0.0554 3.6756 9.0921 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -13.6000 0.4906 -27.719 <2e-16 ***poly(x, 3)1 166.6193 4.9063 33.960 <2e-16 ***poly(x, 3)2 -149.2056 4.9063 -30.411 <2e-16 ***poly(x, 3)3 6.8565 4.9063 1.397 0.165 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 4.906 on 96 degrees of freedomMultiple R-squared: 0.9559, Adjusted R-squared: 0.9545 F-statistic: 693.4 on 3 and 96 DF, p-value: < 2.2e-16
【关键评估参数】
残差标准误差(Residual Standard Error): 这是模型残差的均方根误差,用于衡量模型预测值与实际观测值之间的平均差异。值越小,表示模型拟合越好。这里只有4.096,模型拟合效果还不错;
Multiple R-squared: 决定系数,表示模型解释的变异占总变异的比例。值介于0和1之间,越接近1,表示模型解释能力越强;这里是0.9559,已经是非常好的效果了;
Adjusted R-squared: 调整后的决定系数,考虑了模型中参数的数量。当添加不重要的变量时,R-squared可能增加,但Adjusted R-squared可能减少。这里结果是0.9545,仍然是非常好的结果;
F-statistic: 用于检验模型整体显著性的统计量。如果p值(Pr(>F))小于显著性水平(通常为0.05),则拒绝原假设,认为模型整体显著。这里p值是2.2e-16,模型整体显著;
Coefficients: 模型中每个参数的估计值、标准误差、t值和p值。t值用于检验参数是否显著不为零,p值用于判断参数的显著性。通常,p值小于0.05表示参数显著。这里截距,1,2项都非常显著,但是3项不显著,模型参数还有待调整。
【确定最佳多项式次数】
确定最佳多项式次数通常涉及交叉验证或使用信息准则(如AIC或BIC)。以下是使用交叉验证确定最佳多项式次数的代码↓
# 使用交叉验证确定最佳多项式次数library(boot)# 定义交叉验证函数cv_error <- function(formula, data, deg, K = 10) { model <- glm(formula, data = data) return(cv.glm(data, model, K = K)$delta[1])}# 计算不同多项式次数的交叉验证误差cv_errors <- sapply(1:10, function(deg) { formula <- as.formula(paste("y ~ poly(x,", deg, ")", sep = "")) return(cv_error(formula, data, deg))})# 找到最小交叉验证误差对应的多项式次数best_deg <- which.min(cv_errors)# 打印结果print(paste("Best polynomial degree is", best_deg))
"Best polynomial degree is 2"
最后模型在1-10项之间,得出的结果是2,这也和我们模拟的次数是一样的。为了更直观,我们把每一次拟合的结果都存下来↓
# 创建一个数据框来存储每个多项式次数的模型参数coefficients_table <- data.frame(Degree = integer(0), Coefficients = character(0))# 计算不同多项式次数的交叉验证误差和模型参数for (deg in 1:10) { formula <- as.formula(paste("y ~ poly(x,", deg, ")", sep = "")) model <- glm(formula, data = data) # 获取模型参数 coefficients <- coef(model) coefficients <- coefficients[2:(deg + 1)] # 去除截距项 # 存储结果 coefficients_table[deg, "Degree"] <- deg coefficients_table[deg, "Coefficients"] <- paste(round(coefficients, 2), collapse = ", ")}
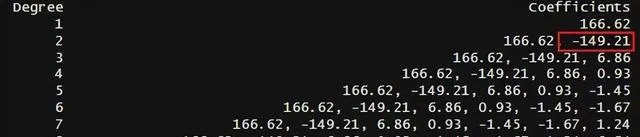
结果就是2次项的时候最优,然后进行可视化展示,把10次结果都进行拟合看一下↓
par(mfrow = c(2, 5)) # 设置图形布局为2行5列for (deg in 1:10) { formula <- as.formula(paste("y ~ poly(x,", deg, ")", sep = "")) model <- glm(formula, data = data) x_pred <- seq(min(x), max(x), length.out = 100) y_pred <- predict(model, newdata = data.frame(x = x_pred)) plot(x, y, main = paste("Degree =", deg), xlab = "x", ylab = "y", col = "blue", pch = 19) lines(x_pred, y_pred, col = "red", lwd = 2)}
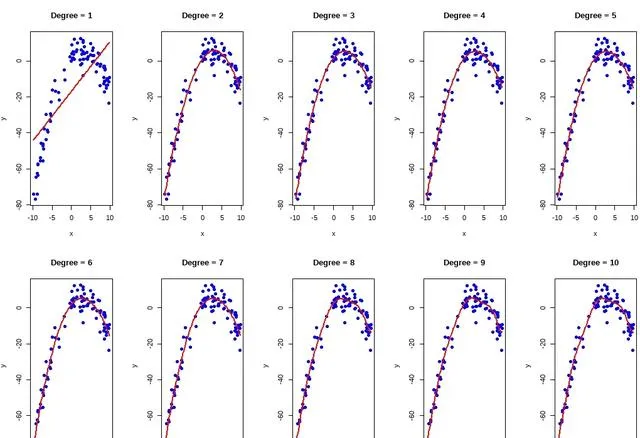
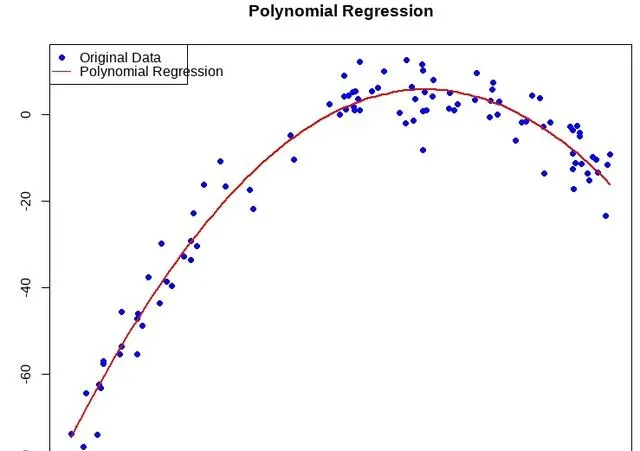
最后可以对新的数据进行预测,并绘制预测结果图↓
# 生成x的预测值x_pred <- seq(min(x), max(x), length.out = 100)y_pred <- predict(model, newdata = data.frame(x = x_pred))# 绘制原始数据和模型预测值plot(x, y, main = "Polynomial Regression", xlab = "x", ylab = "y", col = "blue", pch = 19)lines(x_pred, y_pred, col = "red", lwd = 2)legend("topleft", legend = c("Original Data", "Polynomial Regression"), col = c("blue", "red"), pch = c(19, NA), lty = c(NA, 1))
链接是我使用PowerBI整合的历史文章,按类型分类,可以根据需求查询:Microsoft Power BI↓
https://app.powerbi.com/view?r=eyJrIjoiNjI2NWQ3NjktYjU0ZC00ZWZhLTgzMDgtMGI4ZTk1ZDlkODM3IiwidCI6IjI3NDQ3MWQ0LTM4ZDQtNDVlZS1hMmJkLWU1NTVhOTBkYzM4NiJ9
End











