哈喽~,大家好,我是东哥,宝爸一枚,正努力探索AI,创富人生,目标帮助1000名志同道合的朋友一起提前退休!
你们记不记得EMO?
就是前两天阿里刚放出来那个,通过音频驱动图片唱歌的模型,到现在还没有开源使用,但已经有不少人通过这个噱头,让「亲人复活了」
这不,以抄xi。呃~不对,以研发著称的腾讯直接开源了全新大模型
,鬼畜评论区快要坐不住了啊
来看看坤坤这段说唱:
不得不说啊,不论从肌肉运动还是肢体的协调上,效果都是相当惊艳的,这以后生成口播视频是不是就......
其实早在2月份时候,阿里就公布出自己的图生视频大模型EMO,当时的效果也是相当炸裂。
一张照片,一段音频,就可以生成一段会说话或者唱歌的AI视频,表情,语速都可以一一对应。
还不知道的可以再来回顾一下:
时隔一个多月了,现在EMO的「开源」仓库依旧「整洁如初」
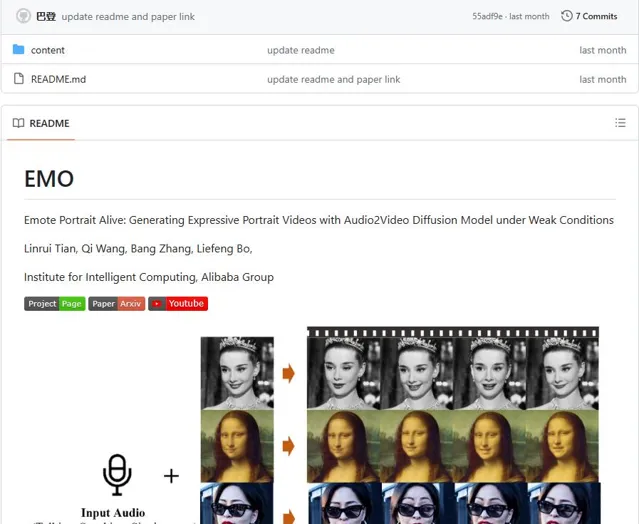
不禁感慨这波开源属实开了个寂寞,本来靠EMO赚足了噱头的阿里,这回真的要emo了
应了那句话,行动早,就是优势。
根据腾讯放出来的模型来看,有三种合成模式
1、自我驱动
意思就是可以指定头部姿势,或者选择预设的姿势配置,来控制生成动画中的头部动作,使动画效果更加自然和多样化,比如坤坤RAP和下面这个:
2、脸部再现
这个意思就是,咱们提供一段视频,AI通过分析和参考视频中的面部表情和动作,实现在图片上复刻,这个技术好
3、音频驱动
通过提供一段音频和一张头像图片,AI根据语音和节奏来控制人物的表情生成动画
这场AI领域的较量中,TX明显快一步,不亏是小马哥啊
但整体看下来,性能应该相差不大,毕竟哪哪都是EMO的味道
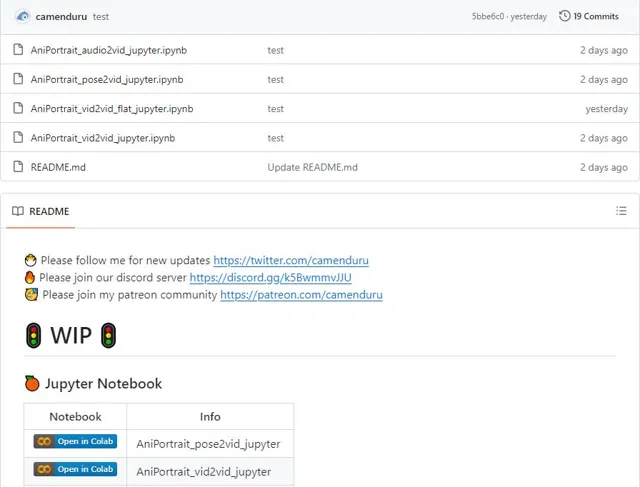
目前该项目的模型权重已经开放下载,感兴趣的伙伴赶紧去试试吧
老铁们如果觉得内容对你有帮助,就给东哥点个「关注」吧,据我所知点「赞」的老铁都好运缠身了
下载的地址我都整理好了,如果你懒得找可以找我领取











