机器之心报道
机器之心编辑部
谷歌在人工智能领域又一次取得了重大进展。
在最新发表的一篇论文中,研究者创建了一个神经网络,可以在不使用传统游戏引擎的情况下为经典射击游戏【毁灭战士】生成实时游戏画面。
这个名为 GameNGen 的系统标志着人工智能领域向前迈出了重要一步,它在一个芯片上以每秒 20 帧的速度生成可玩的游戏画面,每帧画面都由扩散模型进行预测。
可以说,这是第一个完全由神经模型驱动的游戏引擎,可以高质量地在长轨迹上与复杂环境进行实时交互。
这一成就标志着人工智能首次完全模拟了一款复杂的视频游戏,GameNGen 运行在单个张量处理单元 (TPU)(谷歌定制的人工智能加速器芯片)上,能够以惊人的效率处理【毁灭战士】复杂的 3D 环境和快节奏的动作,而且完全不需要游戏引擎的常规组件。
随着这项研究的发布,大家的讨论居高不下。

要知道,2018 年的画面还是模糊不清的:
现在无论从画面质量还是流畅度,都表现的更好:
很多人认为这项研究简直不可思议:

致力于将生成式人工智能集成到游戏引擎中的开发人员表示:「人们可能还不明白这有多疯狂,这项研究是构建虚拟事物的基础,他们现在有了一条清晰的技术路径,可以使用对世界的模拟来实现连贯、交互式的长篇生成。将来,这项技术可以推广到能够获取数据的任何视频游戏。随后很可能为尚不存在的游戏生成数据。因此会有新游戏诞生。这将变得更加疯狂。」
「未来,游戏中的每一个像素都将是生成的,而不是渲染的。」

「这太疯狂了,即使以目前的发展速度,我也没有预料到这一切会来得如此之快。」

不过,面对一众的好评,还是有人提出了相反的观点,比如这位网友表示:「虽然这项研究很有趣,但并没有解决任何问题。它没有创造任何新东西,它并不比其他任何研究更有效率,可以说是一个很好的实验,但你基本上不能用它做任何事情。」
不论大家对 GameNGen 的评价如何,这项研究具体如何实现的,我们接着往下看。
论文介绍
游戏想在电脑上运行起来,要跑通这个循环:(1)收集用户输入(2)更新游戏状态(3)渲染为屏幕像素。这个高帧率运行的游戏循环为玩家创造了一种交互式虚拟世界的体验。
我们玩的游戏大多是在普通的电脑上运行的,虽然现在也有人能用计算器玩【原神】,效果也很不错。然而,无论这些设备多么先进,它们实际上只是在做一件事情:按照游戏开发者事先编写的指令来运行游戏。此外,虽然游戏行业采用不同的引擎来制作游戏,但这些引擎在工作时,比如刷新游戏里 NPC 的位置,都在遵照开发者预设的代码或配置。
近年来,生成模型在图像和视频方面取得了重大进展,比如 Stable Diffusion、Dall-E。我们可以想象,模拟电子游戏的交互世界似乎与视频生成类似。然而,交互世界模拟不仅仅是非常快速的视频生成,还要求在整个生成过程中以可用的输入动作流为条件,这打破了现有扩散模型架构的一些假设。
因此,人们自然会问:神经模型能否高质量地实时模拟复杂游戏?
本文,来自谷歌、特拉维夫大学的研究者给出了肯定的答案。
具体来说,他们展示了一款复杂的视频游戏【DOOM】(毁灭战士),可以在神经网络上(Stable Diffusion v1.4 的增强版本)实时运行,同时实现与原始游戏相当的视觉质量。虽然不是精确的模拟,但神经模型能够执行复杂的游戏状态更新,例如计算弹药、攻击敌人、破坏物体、打开门等。

人类玩家在 GameNGen 上以 20 FPS 的速度玩【毁灭战士】。
研究者提出了 GameNGen,这是第一个完全由神经模型驱动的游戏引擎,能够在长轨迹上高质量的与复杂环境进行实时交互。GameNGen 可以在单个 TPU 上以每秒 20 帧以上的速度交互模拟经典游戏【毁灭战士】。下一帧预测实现了 29.4 的 PSNR,与有损 JPEG 压缩相当。
GameNGen 的训练分为两个阶段:(1) RL 智能体学习玩游戏并记录训练过程;(2) 训练扩散模型以根据过去帧和动作的顺序生成下一帧。条件增强功能可在长轨迹上实现稳定的自回归生成。

论文地址:https://arxiv.org/pdf/2408.14837
项目主页:https://gamengen.github.io/
论文标题:DIFFUSION MODELS ARE REAL-TIME GAME ENGINES

视频链接:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650931999&idx=1&sn=9f5126384e7d3ca7e8ec0b93d1bc5cbb&chksm=84e7c761b3904e776c3a18d411e95fbceddd96e1626fd51e3096be4a38e162f34962fe2ba98e&token=1390133831&lang=zh_CN#rd
方法介绍
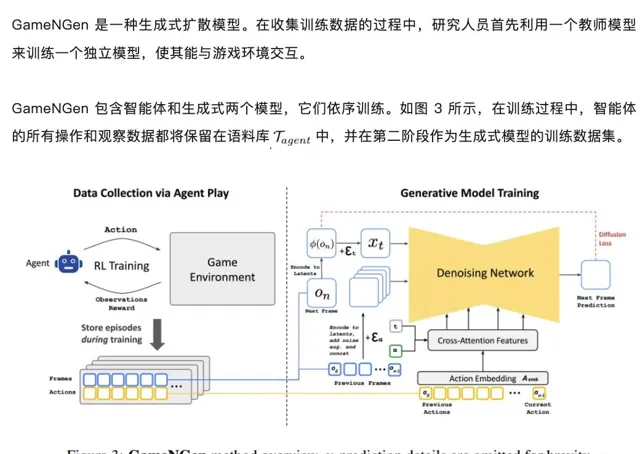
训练生成式扩散模型

使用噪声增强减轻自回归偏差
如图 4 所示,训练时使用了教师强制与自回归采样两种方法。然而,这两种方法的转换不可避免地引发了误差累积,进而导致样本质量迅速下降。为了避免这种偏差,研究人员在训练时向编码帧添加了不同量的高斯噪声来破坏上下文帧,同时将噪声水平作为输入提供给模型。
为了做到这一点,他们均匀地采样了一个最大值内的噪声水平 α,将其离散化,并针对每个噪声区间训练一个嵌入向量。这种方法能让模型学会如何在有干扰的情况下,如何纠正之前帧中的错误信息。在推理过程中,可以控制输入的噪声水平,达到最优的训练效果。在推理阶段,通过调节输入的噪声水平,可以优化模型输出的质量。值得注意的是,即便在不添加额外噪声的情况下,这种方法也能显著提升结果的表现。

微调潜在解码器
由于 Stable Diffusion v1.4 的预训练自动编码器会将 8x8 像素块压缩成 4 个潜在通道,导致模型在预测游戏帧时会产生伪影。这些伪影会让一些小细节变得不够完美,比如游戏界面底部的那些小图标。针对这个问题,研究人员仅对自动编码器的潜在解码器部分进行了微调,采用 MSE(均方误差)作为目标帧像素的损失函数。
值得注意的是,这个微调过程完全独立于 U-Net,且不会对自回归生成过程产生影响。研究人员的操作仅限于潜在变量层面,而非像素层面。
实验
总体来说,就图像质量而言,本文方法在长轨迹上实现了与原始游戏相当的模拟质量。

图像质量:图 5 显示了模型预测的图像和相应的真实图像之间的对比。

视频质量:如图 6 所示,预测的轨迹在内容和图像质量方面与实际游戏相似。
人类评估:研究者向 10 位人类评分员提供了 130 个随机短片(长度分别为 1.6 秒和 3.2 秒),并将模拟的游戏与真实游戏并列播放。评分员的任务是识别真实游戏。在这些测试中,评估者选择真实游戏而非模拟的比例分别为 58% 和 60%
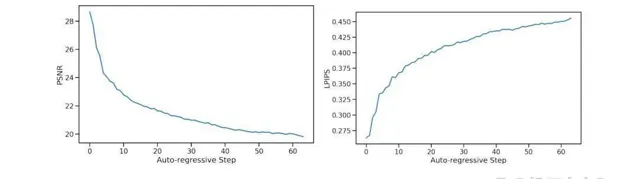
为了消除噪声增强的影响,该研究训练了一个没有添加噪声的模型。图 7 中报告了每个自回归步骤的平均指标值,总共 64 帧。












