Transformer是一种基于注意力机制(attention mechanism)的序列到序列(sequence-to-sequence)模型,由Google在2017年提出。相比传统的递归神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN),Transformer使用了全局信息进行编码和解码,避免了RNN难以并行化和捕捉长期依赖问题,也规避了CNN卷积核大小限制的问题。
Transformer的核心思想是「自注意力机制」,即通过编码器将输入序列转换为一个高维向量表示,然后通过解码器将这个向量转换为输出序列。这里的关键是如何在编码器和解码器之间建立起联系。

Transformer使用了多头注意力机制,将待处理的信息分成多个头部并分别进行注意力计算,获取不同角度的特征表示,从而增强模型表达能力。
另外,为了进一步提高Transformer的表现,许多变种模型被提出,包括BERT、GPT、XLNet等。这些变体利用预训练技术来训练更强大的语言模型,可以应用于更广泛的自然语言处理任务中。
背景
从RNN->Seq2Seq->attention,模型结构在不断的优化,针对这三种模型,我们做一个简单的介绍,具体attention介绍可以参照attention漫谈。
RNN
RNN是用于处理序列数据的神经网络,对于文本中的每一个词,都会被看做一个时序,RNN中每个时序都是一个前馈神经网络,隐藏层中当前时刻的输入,不仅包含了当前的输入,还包含了前一时刻的隐藏层的输出。

Seq2Seq
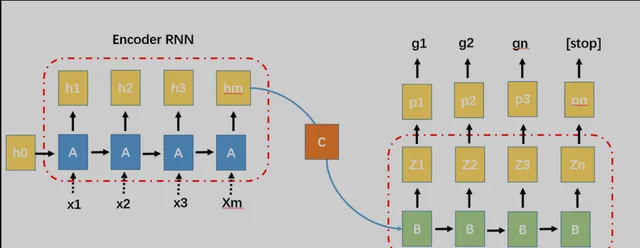
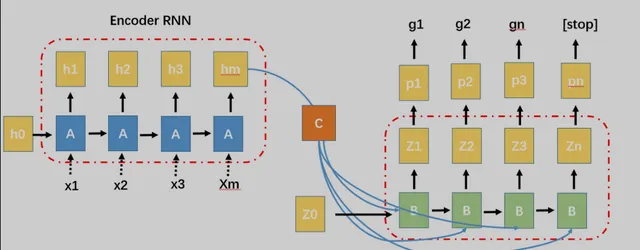
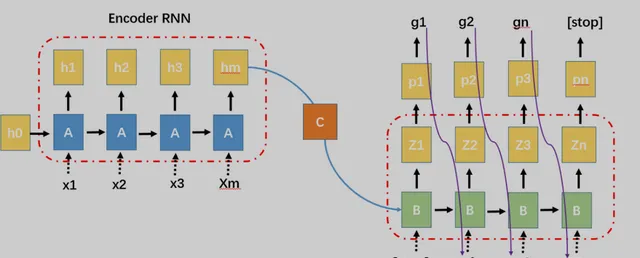
Seq2Seq模型过去常用于生成式对话、机器翻译和文本摘要等任务,简单来说,其主要由encoder和decoder组成。通过encoder编译器将输入,编译为一个状态,再通过decoder解析为另一种状态。以下是Seq2Seq的三种结构,
attention
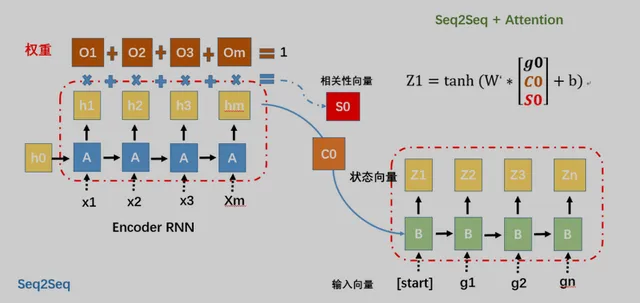
Attention帮助Seq2Seq每次会回顾Encoder中所有神经元的状态信息,并计算相关性,从而使得翻译更加的准确,Encoder原本遗忘的问题,也会被大大降低。
Transformer
Transformer 模型通常用于序列到序列的任务,如机器翻译、语音生成、文本摘要等。下面以机器翻译为例,介绍一下 Transformer 模型的具体实现。
具体来说,Transformer 模型包括了一个编码器Encoders和一个解码器Decoders,其中编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都基于自注意力机制,其中自注意力机制用于计算当前位置与其他位置之间的相似度,并根据相似度对其他位置进行加权求和。
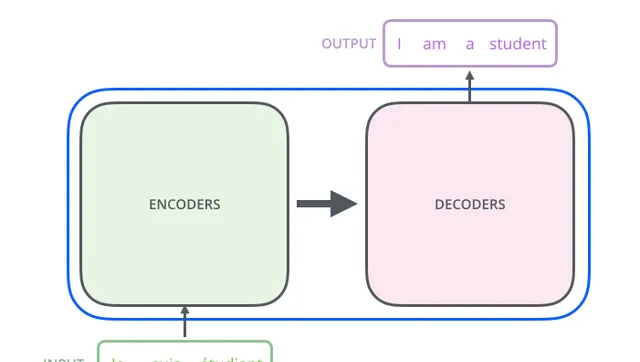
编码器和解码器的 具体实现如下:
- 输入嵌入层:模型首先将输入的单词编号转换成对应的词向量表示。
- 位置编码层:由于 Transformer 模型中不采用循环神经网络(RNN)等传统序列模型,因此需要引入位置编码层,用于处理词语的位置信息。
- 编码器层:编码器由多个相同的层级组成,每个层级包括以下几个步骤:
- 自注意力层:计算当前位置与其他位置之间的相似度,并根据相似度对其他位置进行加权求和,得到自注意力向量。
- 正向传播网络(Feed Forward Network)层:将自注意力向量作为输入,进行线性变换和非线性变换,以获得更为丰富的语义特征。
- 层归一化(Layer Normalization)层:对输入进行归一化处理,以防止梯度消失或爆炸。
- 解码器层:解码器与编码器类似,不同之处在于解码器需要引入一个多头注意力机制和一个编码器-解码器注意力机制,用于处理当前时刻的输出和上下文信息之间的关系。具体来说,解码器层包括以下几个步骤:
- 多头注意力层:计算当前位置与其他位置之间的相似度,并根据相似度对其他位置进行加权求和,得到多个注意力向量。
- 编码器-解码器注意力层:计算当前位置的输出和编码器各个位置的输出之间的相似度,并根据相似度对编码器各个位置的输出进行加权求和。
- 正向传播网络层:将两个注意力向量作为输入,进行线性变换和非线性变换,以获得更为丰富的语义特征。
- 层归一化层:对输入进行归一化处理。
- 输出层:输出层接收解码器层的输出,进行线性变换和非线性变换,最终输出预测结果。
需要注意的是,由于 Transformer 模型中的每一个位置都会与其他位置相互交互,因此模型的计算量较大,通常需要进行一些优化。比如,可以采用 1x1 的卷积来降低计算量,或者使用注意力机制时采用 K-Means 等聚类算法来近似计算。
Transformer中的Encoder和Decoder并不是一个,论文中采用了6个Encoder和6个Decoder,这个数量可以根据需要来设定。
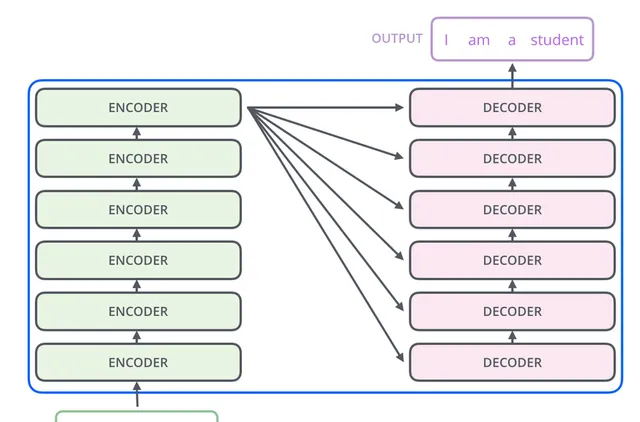
下面是Transformer的网络结构,可以先有一个印象。
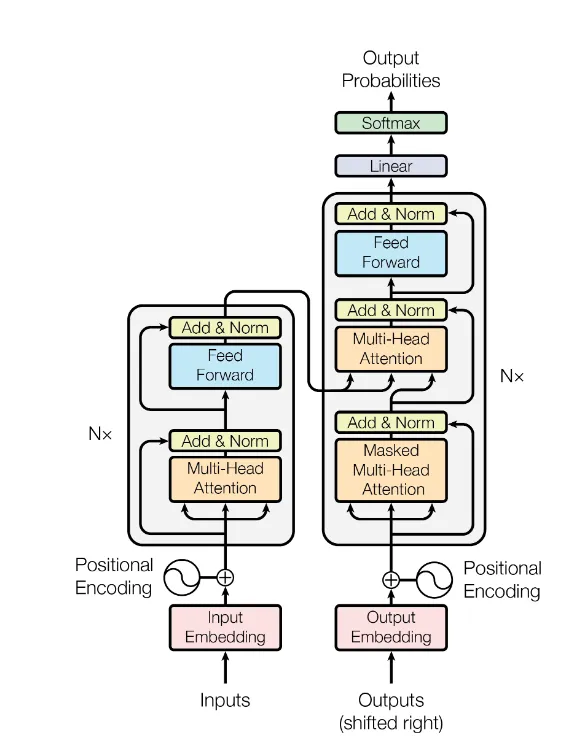

总之,Transformer 模型通过自注意力机制,能够有效捕捉序列中的关系,并取得很好的效果,目前已经成为自然语言处理领域中最为先进的深度学习模型之一。上面的处理过程,听起来可能有些蒙,下面我们将一步一步拆解说明。
Encoder
每个Encoder都有相同的结构,但是权重并不共享,每个Encoder拥有两层结构,如下所示:

编码器Encoder的输入首先会经过self-attention层,在对词汇进行编码时,self-attention可以帮助词汇能同时关注到输入句子中的其他词汇。
self-attention的输出会输入到前馈神经网络(feed forward),前馈神经网络结构会在后续的encoder都会被使用。
我们以NLP作为实例进行说明,在对Encoder输入时,我们需要对每个词汇进行编码,编码算法可以参考, embedding algorithm.假设我们已经完成了编码,如下所示,每个词汇变编码为512维,我们用4个方块表示。

当词汇经过enbedding之后,会经过上面介绍的两层网络,如下所示。

在词向量输入self-attention时,每个词向量输入有特定的位置,是相互依赖的关系;但在feed forward中没有这种依赖关系,因此在流入feed forward时,可以并行处理。
Encoder接收词向量,经过self-attention处理后,进入feed forward处理,处理后的结果,进入下一个Encoder。

Self-Attention
假设当我们要对「The animal didn't cross the street because it was too tired」进行翻译时,「it」具体指代什么,是street还是animal,对于人来说很容易判断,但对于算法来说并不容易。
当算法在处理「it」时,self-attention会帮助「it」关注「animal」。
当模型处理每个单词(输入序列中的每个位置)时,self-attention允许它查看输入序列中的其他位置,以寻找有助于对该单词进行更好编码的线索。
下图展示的是利用self-attention处理之后,「it」与各词汇的关系,其中颜色越深表示关系越密切。

下面将对self-attention如何得出相互之间「关系」进行说明。
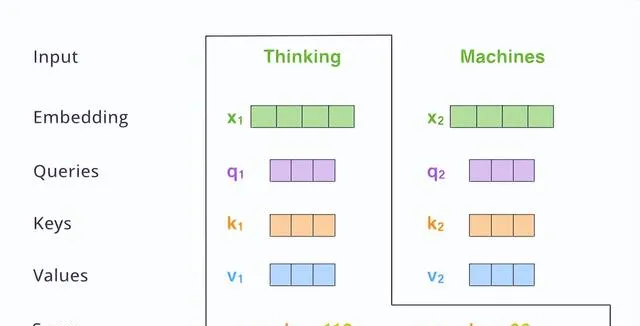
Self-Attention作为重要部分,我们将单独进行介绍。 我们会为每个词向量创建一个Query verctor(用q表示)、Key vector(用k表示)、Value vector(用v表示)向量 。其中q、k、v是词向量与矩阵Wq、Wk、Wv相乘获得,其中Wq、Wk、Wv是模型训练中获得。
上述向量都是要远小于词向量维度,论文中词向量有512维,q、k、v都是64维。也没有必要将q、k、v设置的很小,64维在后续multiheaded attention也是适用。

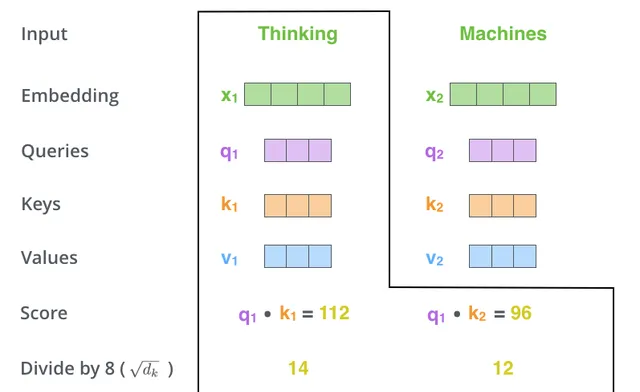
我们以上述「Thinking」为例进行说明,我们需要对输入句子中的每个单词与这个单词进行评分。该分数表示了词汇之间的「关系」密切程度。
假设我们输入了两个词汇,分别是「thinking」和「machines」。 分数是通过q和k相乘得到 。其中q1*k1表示「thinking」与「thinking」的关联程度;其中 q1 * k2表示「thinking」 和 machines的关联程度。 即将该词对应的q与不同词对应的k1、k2......相乘,即得到该词与各词的分数 。下图是计算「thinking」与其他词分数的过程。
假设q1与k1、k2相乘后,得到socre分别为112、96。
将q与k相乘得到的分支,除以8(论文中Key vector使用的是64维,取其开方即8),这样可以使得梯度更加稳定。也可以除以其他的值,这里是默认值8为例进行说明。上式中Score将会变为14、12
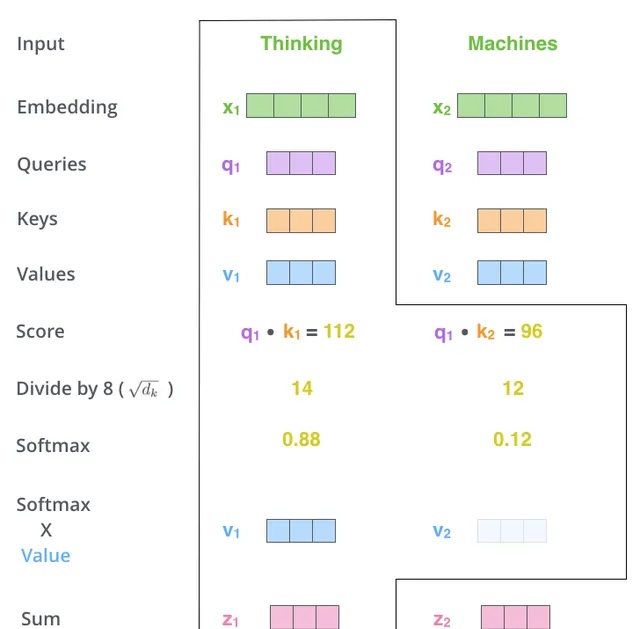
将上述q1与所有k相乘后的分值,通过softmax进行归一化,这样保证了总和为1。softmax 分数决定每个词在这个位置上会被表达多少。通常,自身位置的分值会最高,例如下面的0.88,但也要注意与其他单词的分值。
第五个步骤是将每个值向量乘以 softmax 分数(为了第六步进行求和的准备工作)。这里的直观想法是保留我们想要关注的单词的值,同时淹没不相关的单词(例如通过将它们乘以像 0.001 这样的小数字)。
即将上述的values乘以softmax,得到新的v1。

第六步是对加权值向量求和,即v1 + v2 + ...。这就产生了self-attention 在这个位置的输出(对于第一个单词)。
通过上述六步,完成了self-attention的计算, 得到的结果会被输入到feed-forward网路中。实际的计算并不是一个一个的计算,是通过矩阵的方式来计算,下面将以矩阵的形式进行介绍。
Matrix Calculation of Self-Attention
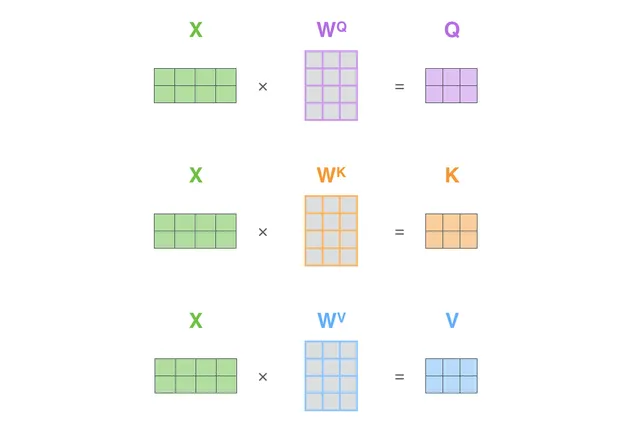
- 将输入的词表示embedding矩阵,表示为X,与Wq、Wk、Wv矩阵相乘,得到最终的Query、Key和Value。
- 将上述的第二步到第六步合并,得到最终的self-attention向量输出。
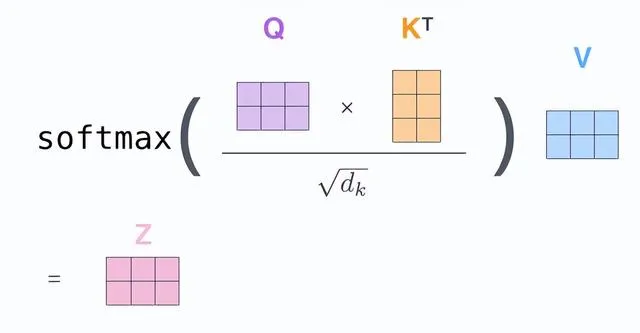
论文中self-attention采用了「multi-attention」,即多头注意力机制,该方法,带来了attention两方面的提升 :
- 可以使模型关注不同位置,上述示例中z1也包含了其他位置的信息,但更多的是被自身所主导。例如当我们需要翻译「The animal didn’t cross the street because it was too tired」,multi-attention可以更好的帮助我们将「it」关联到更加相关的词。
- multi-attention提供了多个「representation subspaces」,multi-attention不仅有一组,是有多组Query/Key/Value(transformer中使用了8组,因此在每个encoder/decoder中有8组)。每组attention都是随机初始化,在训练之后,每组attention可以将输入的embedding映射到不同的子空间中。
以2组attention为例进行说明。

如果我们使用相同的self-attention,仅是8组不同的权重矩阵,我们最终也会得到8组不同的Z 矩阵。如下所示。

feed-forward网络中不需要8组矩阵,只需要一组矩阵作为输入,因此,我们需要想办法将八组矩阵合并为一组。
我们需要将8组矩阵拼接,与额外的权重矩阵Wo相乘,得到最终一组Z矩阵 。
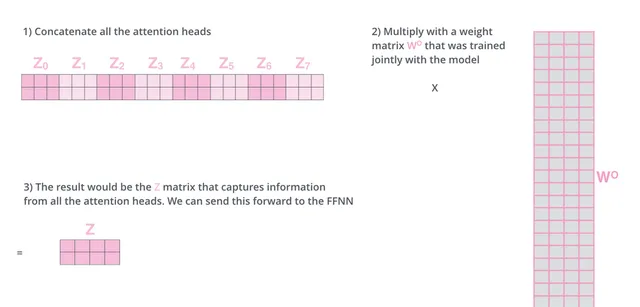
以上便是multi-attention计算的全部过程,我们将上述所有步骤合并起来,方便大家回顾一下计算过程。
下面是multi-attention中,不同attention中it关联了不同的词语,黄色代表的attention中it与animal关联;绿色代表的attention中it与tire关联 。
Representing The Order of The Sequence Using Positional Encoding
到目前为止,缺少对输入信息中位置信息的表示。为了解决这个问题,transformer为每个输入的embedding添加了一个vector,这有助于它确定每个单词的位置,或者序列中不同单词之间的距离。直觉是,将这些值添加到嵌入中,一旦它们被投影到Q/K/V向量中,并且在点积attention期间,嵌入向量之间就会有意义的距离。
如果输入的embedding是4维,则位置信息可能如下所示:
下面我们将对位置信息进行说明,每行对应一个向量的位置编码,所以第一行就是我们要添加到输入序列中第一个单词的嵌入的向量。假设有20个单词,每行包含512个值,每个值在1到-1之间。我们用颜色标记了它们,这样图案就清晰可见了。
上图中,20个单词(行)的位置编码的真实示例,嵌入大小为512(列)。你可以看到它似乎从中心一分为二。这是因为左半部分的值是由一个函数(使用正弦)生成的,右半部分是由另一个函数(使用余弦)生成的。然后将它们连接起来形成每个位置编码向量 。
位置信息如何生成?
可以在get_timing_signal_1d()中看到生成位置编码的代码。这不是位置编码的唯一可能方法。然而,它的优点是能够扩展到看不见的序列长度(例如,如果我们训练的模型被要求翻译一个比我们训练集中的任何句子都长的句子)。
上面是transformer中transformer2transformer的采用的位置编码信息,但实际论文中是采用另一种方法,而是将两个信号交织在一起,大概示例如下,具体可以参照 Here’s the code to generate it:
残差连接Residual Connections
在encoder中有一个细节,每个encoder中,self-attention和ffnn周围都有一个residual connection网络结构,之后是 layer-normalization step。网络结构如下所示:
我们在上面的途中加入向量,让这个计算过程,看起来更加清晰。
上述过程同样适用于Decoder,假设transformer仅有2层encoder和decoders,则网络结构如下:
什么是 layer-normalization
Layer normalization(层归一化)是一种用于神经网络的归一化技术,旨在解决梯度消失和梯度爆炸等问题。与批归一化(Batch Normalization)不同,它是在每个样本的每个特征维度上进行归一化,而不是在批次维度上进行归一化。
Layer normalization的目标是通过对每个样本的特征维度进行归一化,使得每个特征维度的均值为0,方差为1。这样可以使得不同样本在不同特征维度上具有相似的分布,有助于提高模型的泛化能力。
具体而言,对于输入的特征向量x,Layer normalization的计算公式如下:
mean = mean(x)
std = std(x)
output = (x - mean) / std
其中,mean表示特征向量x的均值,std表示特征向量x的标准差。通过减去均值并除以标准差,可以将特征向量归一化为均值为0,方差为1的分布。
Layer normalization通常被用于深度神经网络中的每个层,以帮助网络更好地学习输入数据的表示。它可以提高模型的收敛速度,并且对于不同样本和不同特征维度的变化具有鲁棒性。
Decoder
Decoder中使用了与Encoder相同的网络结构,但是在self-attention和feed forward中间,新增了encoder-decoder attention,该网络结构主要专注于encoder的输入,避免相关信息被遗忘(类似于seq2seq中attention的作用)。
下面我们将整个流程组合起来进行说明 。
编码器首先处理输入序列。然后,顶部编码器的输出被转换为一组注意力向量K和V。这些向量将被每个解码器在其"编码器-解码器注意力"层中使用,该层帮助解码器集中于输入序列中的适当位置。
下面的步骤会重复这个过程,直到达到一个特殊的符号,表示 Transformer 解码器已经完成其输出。每个步骤的输出被提供给下一个时间步的底部解码器,并且解码器会像编码器那样上升其解码结果。就像我们对编码器输入所做的那样,我们也会对这些解码器输入进行嵌入并添加位置编码,以表示每个单词的位置。
在encoder和decoder中attention使用方面具有一定差异 。
在decoder中,attention只允许关注输出序列中较早的位置。这是通过在自关注计算的softmax步骤之前屏蔽未来位置(将它们设置为-inf)来实现的。
The Final Linear and Softmax Layer
decoder输出一个浮点数向量。我们怎么把它变成一个词?这是最后一个线性层的工作,然后是一个Softmax层。
Linear是一个简单的全连接神经网络,将decoder产生的向量投影到一个更大的向量中,这个更大的向量被称为 logits 向量。
假设我们的模型知道 10,000 个独特的英文单词(即模型的「输出词汇表」),这些单词是从训练数据集中学习到的。这将使得 logits 向量的宽度为 10,000 个单元,每个单元对应一个独特单词的分数。这就是我们如何解释模型输出经过线性层后的结果。
然后,softmax 层将这些分数转换为概率(所有概率都为正,且总和为1.0)。选择具有最高概率的单元,并将其关联的单词作为该时间步的输出。











