机器人是出色的人类模仿者,但大多离不开人类的帮助,比如一些预设的编程。
尤其是家用机器人,在面对复杂的家务劳动时,如果「大脑」中没有足够多的常识,就很难满足人类家庭的日常需求。
如今,在大型语言模型(LLMs)的驱动下,家用机器人已经可以掌握「常识性知识」,能够在没有人类的帮助下进行自我纠正,出色地完成复杂的家务劳动。
相关研究论文以「 Grounding Language Plans in Demonstrations Through Counterfactual Perturbations 」为题,以会议论文的形式已发表在人工智能(AI)顶会 ICLR 2024 上。

麻省理工学院(MIT)电气工程和计算机科学系博士 Yanwei Wang 为该研究论文的通讯作者。

他表示,模仿学习是实现家用机器人的主流方法。但是,如果机器人盲目地模仿人类的运动轨迹,微小的错误就会不断累积,最终导致执行过程中的其他错误。「有了我们的方法,机器人就能自我纠正执行错误,提高整体任务的成功率。」
让机器人掌握一点家务常识
从擦拭溢出物到端上食物,机器人正在学习如何完成越来越复杂的家务劳动。
实际上,许多家庭机器人都是通过模仿人类行为来学习的,它们被编程为复制人类指导它们完成的动作。
然而,由于以往的机器人不具备常识,除非人类工程师通过编程让它们适应每一个可能的碰撞和轻推,否则它们并不一定知道如何处理这些情况,就会从头开始执行任务。
或许,通过加入一些「常识性知识」,机器人可以在面对将它们推离训练轨道的情况时有所准备。
据论文描述,Yanwei 等人通过一个简单的日常任务验证了他们提出的方法的有效性。该任务看似非常简单,即从一个碗中舀出弹珠,然后倒入另一个碗中。

然而,在先前的方法中,为了让机器人完成这项任务,工程师往往会让机器人在一个流体轨迹上完成「舀」和「倒」的动作,并可能多次重复,让机器人模仿人类的一些示范动作。
问题是,虽然人类可能会一次性演示一项任务,但这项任务取决于一系列子任务或轨迹。例如,机器人必须先将手伸进碗里,然后才能舀水,在移动到空碗之前,它必须先舀起弹珠。如果机器人在这些子任务中的任何一个过程中受到推挤或犯错,那么它唯一的办法就是停下来,从头开始。
除非人类工程师明确标出每一个子任务,并为机器人编程或收集新的演示,从而让机器人从上述失败中恢复过来,在瞬间进行自我纠正。
「这种程度的规划非常繁琐,」 Yanwei 说。
于是,在这项研究中,Yanwei 及其团队将机器人的运动数据与大型语言模型的「常识性知识」联系了起来。
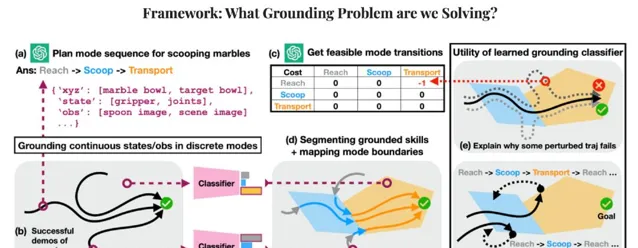
他们使机器人能够从逻辑上将许多给定的家务任务解析为子任务,并对子任务中的干扰进行调整。基于此,机器人就能继续前进,而不必返回并从头开始执行任务。而且重要的是,人类工程师也不必为每一个可能出现的故障编写详细的修复程序。
据介绍,这些深度学习模型可以处理大量的文本库,并以此建立单词、句子和段落之间的联系。通过这些联系,大型语言模型可以根据它所学到的上一个词后面可能出现的词的类型生成新的句子。
另外,除了句子和段落之外,大型语言模型还能根据提示生成特定任务所涉及的子任务的逻辑列表。例如,如果被要求列出将弹珠从一个碗中舀到另一个碗中的动作,模型就可能会产生一系列动词,如「够」、「舀」、「运」和「倒」。
「大型语言模型可以使用自然语言告诉机器人如何完成任务的每一步。人类的连续演示就是这些步骤在物理空间中的体现,」 Yanwei 说,「我们希望将两者联系起来,这样机器人就能自动知道自己处于任务的哪个阶段,并能自行重新规划和恢复。」
Yanwei 表示,他们的算法现在可以将远程操作系统收集的数据转化为强大的机器人行为,尽管有外部干扰,机器人仍能完成复杂的任务。
不足与展望
尽管这一方法能够使得机器人在没有人类的帮助下进行自我纠正,从而完成复杂的家务劳动,但也存在一定的局限性。
例如,虽然他们的方法不需要大量的人类演示,但它需要大量的试错和具有重置能力的环境,以便收集轨迹的任务成功标签。不过,研究团队表示,这种数据效率低下的问题可以通过主动学习来解决。











