(报告出品方/作者:国元证券,彭琦)
1. 24 年 Dram 行业「三点共振」,有望形成重构估值
2024 年是 dram 行业「三点共振」的交汇时点。三点共振指的是 Dram 行业经过了 2 年调整后,将在 24 年迎来大周期向上拐点,DDR5 在全球 Dram 市场渗透率从 23 年的 15%左右提升到 50%-60%的关键时点,以 及 AI+率先带动的 AI PC 需求,进而推动消费类 Dram 规格向服务器 Dram 规格靠拢的关键时间节点。
首先,我们认为的第一个共振点将是 24 年的 Q1,我们判断 Dram 行业在 24 年 Q1 进入被动去库存周期, 预示着新的大周期拐点即将来到。Dram 行业自 2021 年 Q3 进入见顶后,走了超过两年的行业下行周期,Dram 颗粒的价格在 23 年 2 季度跌到了底部。在 23 年 Q1 开始三星、海力士和美光等存储大厂采取了减产保价的策 略,通过降低供应量而稳定 Dram 颗粒的价格并见到成效。经过连续超过 3 个季度的快速去库存,目前从消费 电子、通信、工业、汽车、服务器等方向上主要客户的库存逐步恢复到正常水平,服务器客户的去库存预计在24 年上半年完成。 预计从 24 年 Q1 开始,行业将从主动去库存阶段进入被动去库存阶段,而三季度进入主动 补库存阶段,而期间价格将会呈现持续上升趋势。事实上,资讯机构 Trendforce 刚刚提升了对 24 年一季度 mobile Dram 和 Nand flash 的价格预期,mobile Dram 的价格的季涨幅从 8-13%提升到了 18-23%。由于 Dram 产品的半导体芯片中的特性,决定了一旦市场对 Dram 的涨价预期形成,将在很大概率上形成一定的追涨补货 的情况。所以即使我们判断在 23Q4 到 24Q1, 实际的终端需求或未那么快启动,库存水平也未完全到合理位 置,但渠道和系统厂的补货行为已经提前开始,进而将出现一段时间被动去库存和主动补库相叠加的时期,而 整体需求上行而带动全面补库存周期我们预计可能在 24Q2-Q3 出现。

第二个共振点则是 DDR5 的渗透率。根据我们的数据测算,在 23 年 Q4, DDR5 的实际渗透率或未达到市 场普遍预期的 20%,而是 15%左右,这主要是 DDR4 去库存进度影响。根据市场反馈,当前 DDR5 的需求主 要来自 LP DDR5 和服务器产品,且这两个方向的涨价意愿较为强烈。预计到 2024p 服务器去库存完毕以及 AI PC 出货拉动,DDR5 渗透率将能实现快速提升,在 Q4 达到 50-55%水平。而 DDR5 配套 RCD 价格,较 DDR4 RCD 预计上浮 80%以上,随着 DDR5 渗透率提升,将推动澜起科技在 RCD 上的营收增长,并推动整 体毛利率水平上升,这点在公司三季报中有一定体现。
相较于其他美系和日系竞争对手,我们测算公司在全球 Q3 和 Q4 的 DDR5 出货模组中,RCD 市占率取得 大幅提升,并实现对其竞争对手的超越。这一方面得益于公司在产品端研发带来的先发优势,另外一方面同其 以及构建完善的配套芯片体系和供应链有关,比如公司在 PMIC 以及 SPD Hub 上均形成了稳定的供应体系。 根据相关数据显示,随着 DDR5 渗透率提升,澜起科技主营业务芯片收入提升了 80%,而同期其竞争对手 Rambus 却下降 13%。我们有理由相信随着 DDR5 渗透率大幅提升的过程,公司市占率有望持续保持较高比 例的同时获得更大的业绩弹性。
随着产业对低延迟和高带宽数据传输需求的持续上升,相较于DDR4一个新平台平均24个月的迭代周期, DDR5 的平台迭代周期缩减到了 12 个月。 当前市场主流的 DDR5 一代是 4800MT/s 规格,是随着 intel Sapphire Rapids 和 AMD 的 Geona 平台发布而开始普及应用。而去年 12 月 15 日 Intel 的 Emerald Rapids 平 台已经发布,且开始进入量产阶段,这将带动 DDR5 第二代 5600MT/s 在 24 年进入普及阶段。在 24 年,intel 的 Granite Rapids 和 AMD 的 Turin 预计也会发布,将带动 DDR5 第三代 6400MT/s 进入普及。DDR5 平台世 代的更迭,一方面能够加快 DDR5 渗透率的快速提升,同时对于 DDR5 的整体价格也起到良好支撑作用。对应 的,公司作为 DDR5 接口芯片供应商,一方面能受益于 DDR5 渗透率提升带来的出货量提高,另外一方面也因 为 DDR5 世代更迭加快而形成较 DDR4 世代更好的利润回报。从供应生态维度看,DDR5 规格的提升以及云 厂对采购口径的简洁化对传统接口芯片供应商提出了新的要求。不仅要有 RCD 和配套 DB,还需要能够提供全 套芯片组,包括 PMIC, SPD Hub 和 TS(温度感应)在内的完整解决方案。这就要求接口芯片厂商需要有更长 的研发产品线和供应链管理能力。公司除了强化了在 PMIC 等核心产品线上的研发,在 SPD Hub 上也同国内 主要厂商形成战略合作,具备稳定的供应能力,在生态链上形成自己的护城河。
第三个共振点则来自于 AI 赋能到消费终端而带来的硬件规格升级。随着 24 年 Q3 AI PC 产品相关产品的 售卖,PC 将实现小型算力功能并具备一定的推理建模能力,这就要求 Dram 内存的规格开始向服务器靠齐。 对于澜起来讲,配置了公司 RCD 和 SPD hub 的内存条产品是较少用于通用型 PC 上,但随着 AI PC 的渗透率 提升,以及 DDR5 规格上到 6400MT/s,公司 RCD 等接口芯片的需求在消费级产品上开始得到广泛的应用, 进而打开了公司的市场空间。这点我们在本文第三部分也有进一步说明。 AI 赋能到消费终端对于公司的意义在于,公司的 RCD 产品将不再仅用于服务器的需求上,而是逐步开始 以 CKD 产品的形式在 PC 和 NB 或是其他具有一定 AI 功能的智能终端上应用,市场空间将大幅提升。
2. AI 技术趋势性发展,推动存储接口芯片供应商切入 AI 算力体系
公司在 AI 算力方面的成长逻辑,则由 AI 算力系统技术发展趋势所带来。
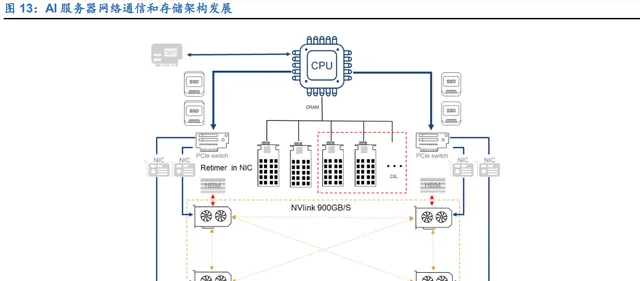
AI 服务器整体性能的提升,除了 GPU 算力为主的算力提升以外,如何实现更快网络通信和提升存储单元 的吞吐效率和降低「内存墙」的影响,是技术发展的重要方向。我们判断从 24 年开始,围绕网络通讯和存储单 元的技术升级,正在同步展开。
首先,PCIE 5.0 的 AI 服务器在 2024 年将成为主流。进入 PCIE5.0, 频宽将从 4.0 世代的 64GB/S 升级到 128GB/S,数据传输速率从 4.0 的 16GT/S 提升到 32GT/S;总线传输速度的成倍增长也带来了数据从 CPU 在 PCB板上向SSD或者其他组件传输过程中的杂讯和信号损失加大。PCIE retimer对于优化数据传输的稳定性, 以及提升 AI 服务器传输高精度,逐步从选配芯片成为标配。随着 PCIE 5.0 AI 服务器需求的持续上升,对于 PCIE 5.0 retimer 的需求也成快速增长态势。
其次,CXL2.0-CXL3.0 将在未来几年进入加速导入期。 尽管 PCIE5.0 的通道数据传输速率满足了当前市场绝大多数的需求。但应对数据 TB 级增长以及异构计算 发展的大趋势,PCIe 在内存使用效率、延迟和数据吞吐量等方面,已经面临压力。另外,随着系统 CPU 核数 的增加,「内存墙」问题进一步凸显,这使得业界开始加速推动 CXL(Compute Express Link)协议的发展,并形 成对 PCIE 的替代趋势。 CXL,是 Compute Express Link 的简称, 是一种高性能、开放式的通信互联协议,用于 CPU 与 GPU、 FPGA 或其他加速器,存储和其他 I/O 设备,以及内存之间提供高效的通信。由 intel 在 2019 年提出,捐献了 其在相关方向上的研究成果,并当时拉上 Google,Microsoft,HPE,华为等组成了 CXL 联盟。 CXL 让 CPU 与 GPU、FPGA 或其他加速器之间实现高速高效的互联,这就是英特尔推出 CXL 这种新的 开放性互联协议的初衷。CXL 是由 3 种介面形式互联(CXL.io、CXL.cache 和 CXL.mem),实现系统中各个组 件内存间的一致性,从而借着资源共享(内存池化),来达成更高效能、减少软件堆栈复杂性,从而降低整体系 统成本。随着 CXL 技术在服务器系统中广泛使用,业界就能够把工作重心放到运算的工作负载上,不需要在加 速器内存管理硬件上花费大量精力。 英特尔原计划以 CXL 来取代 PCIe,但由于 CXL 构建于 PCIe 逻辑和物理层级之上,且主流芯片产品的技 术推动需要 AMD,Nvidia 以及存储企业的共同支持,因此 CXL 作为 PCIe 物理层之上运行的一种可选协议仍 将与 PCIe 共存很长一段时间。
早期业界在 CPU 和 GPU 协同运算的协议上,并不只有 CXL,还包括 CCIX,Nvidia 自己的 NVlink,GenZ,AMD 的 infinity Fabric 以及 OpenCAPI 等。随着 2019 年 ARM 加入 CXL,再到 2021 年 Gen-Z 并入 CXL,以 及 2022 年 AMD、Xilinx、IBM 支持的 OpenCAPI 标准并入 CXL 标准规范内,使得 CXL 将成为市场最主流的 芯片互通设计标准。当前 CXL 联盟包含了 Intel、AMD、NVIDIA、Arm,三星、美光、Hynix,、Google、微软、 Meta、阿里巴巴,DELL、HP、思科及华为等,系统生态已经成型。
CXL 从 1.0-1.1 开始,产业早期应用启动并不快,直到 22 年 intel 的 sapphire rapids 有了支持 CXL1.1 标 准的总线后,CXL 的产业化推进速度开始逐步加快。支持 CXL2.0 的 Intel P-core 的 Emerald Rapids,E-core Xeon 处理器(Sierra Forest)在 2024 上半年交货,将大幅推动 CXL 进入 2.0 应用时期。而 25 年底发布的 Diamonds Rapids 平台将进入带动 CXL 进入 3.0 时代。 CXL 架构的推动,除了加速 CPU 和 GPU 等加速卡的互联通信以外,另外一个重要的点,是为了突破系 统「内存墙」的限制。所谓内存墙「Memory wall」 的问题,是指 微处理芯片的性能提升远大于 Dram 的性能 提升,所以处理器时常要等待从内存中提取数据,进而影响整体系统效率。而当 CPU 的内核数量大幅增加后, 这种性能之间的差异就会进一步放大。 为了降低这种差距,业界一般采取加快 DDR 的传输速率以及更多的内存通道数量达到更大的系统存储带 宽,但随着 CPU core 数量的持续大幅上升,平均到 core 的内存带宽能保持到 4Gb/s 以上都有一定压力。
随着 CPU 多核化,CPU 中每个 core 的内存容量也在 core 核数大幅增长情况下,也在持续下降。一般来 讲, 在单个通道中加入更大容量的 DIMMs 能提高系统的内存容量,但由于现在的 memory 的控制器不在是独 立在北桥上,而是集成到 CPU 里面,所以增加通道上的 DIMMs 容量进而增加了每条通道上的负荷,反过来会 降低系统 memory 的时钟频率,对本以存在压力的内存带宽进一步「雪上加霜」。 所以,CPU 朝着更高核数发展,势必要求系统的内存容量和单 core 的带宽能够有更大的升级空间,CXL 架构通过共享内存池和内存扩展,能有效缓解内存墙形成的问题。
比如到了 CXL2.0 阶段,CPU 与 AI 芯片或其他支持 CXL 或 PCIe 接口的装置之间,可运用 CXL 协议共享 内存资源,例如 CPU 的快取(cache)与 GPU HBM 内存可实现弹性共享,以降低 CPU 及 GPU 之间的运算或 传输延迟,进而提升服务器系统运算效能。而到了 CXL3.0,数据的交换方式从单层拓展成多层,可以形成网状 或环状的非树状结构,PCIE 升级到 6.0 支持 64Gb/s 的传输,更加庞大而具有弹性的存储资环共享,对于系统 算力效率提升,将起到关键性作用。
随着 CXL 架构的逐步推广, Dram 产业链条在整体 AI 算力系统中的话语权和重要性在持续提升。 从整个算力系统来看,HBM 技术的升级和应用激发了 GPU 的算力,并给存储厂商带来巨大商机和市场。 而 CXL 架构的发展,将通过存储容量延展和「内存池化」等方向上展开,突破系统的「内存墙」的限制,进一 步提升服务器的算力性能。 而服务器内存扩展和内存池化的趋势,也势必推动 Dram 产业链中涉及高速数据传输方面的供应商,如澜 起,Rambus 或是 Phison 等公司,从传统的 DDR 模组的接口芯片配套供应商, 往 AI 服务器系统内部发展,而 CXL2.0, 或 CXL3.0 retimer,redriver 亦或是 MXC 芯片,均是应对 AI 服务器技术生态的发展而顺势产生,形 成新的需求空间。 对于 CXL 架构带来的商机,主要包括 CXL extender,CXL pooling 和 CXL retimer 几个方向。目前公司在 这几个方向上均有产品布局。比如在 CXL extender/pooling 的控制器方向上,有 MXC8591。主要竞争对手包 括美国的 Astera Labs 和 Microchip。 而 CXL retimer 上,有支持 CXL 2.0 的 RT51632 等产品。主要竞争对手包括 Rambus,谱瑞和群联等。

从时间上看,24 年到 25 年是公司在高速介面芯片业务上取得重要进展的时间窗口。我们预测从 24 年 Q3 左右,公司 PCIE retimer 业务有望起量。而 MXC 有望在 24p 到 25 年进入批量供应期。根据美光预测,CXL 的市场空间在 2030 年有望超过 200 亿美金,我们假设 CXL controller/extender 芯片占比 10%,对于公司来 讲,有超过 20 亿美金的市场空间。
3. AI PC 正当时,CKD 有望带动业绩加速成长
从 AI PC 开始,24 年是整个电子产业进入到 AI 赋能电子终端阶段的元年。而 AI PC 作为具备独立离线 AI 推理能力的新型电脑,对单机系统性能需求到了一个新的高度。而与之配套的笔记本和台式机用 UDIMM 和 SODIMM Dram 模组上,规格上也将向服务器规格靠拢,在早期笔记本和台式机 DDR 模组传输速率在 3200MT/s 下,通常并不需要像服务器那样的高容量和复杂的内存配置,就不需要 RCD 或 CKD 芯片。但 AI PC 诞生,尤 其是 DDR5 的传输速率要求达到 6400MT/s,CKD 芯片作为类似于低配 RCD,则形成了标准配置。
随着上游 CPU 芯片商的计划放量生产。下游的电脑厂商也相应地推出一些列计划。AI PC 放量在即,我们预 测 CKD 业务会在 24 年给澜起科技带来较大的业务弹性。
我们对 CKD TAM 会伴随者 AI PC 的渗透率提到逐渐增长,预估 2027 年 PC 出货量 2.9 亿台,AI PC 78% 渗透率,我们测算 CKD27 年 TAM 约为 71 亿。我们预测 CKD 业务会在 24 年,25 年给澜起科技带来较大的 业务弹性。
4. 23Q4 盈利预测与估值
我们认为受到 DDR5 渗透率逐渐提高,澜起科技的芯片接口业务逐渐增长。随着 AI 服务器出货量增加, 存储商逐渐占据市场重要地位,澜起与之相关的配套芯片业务、Retimer 和 CKD 业务会迎来爆发式增长。我们 预计 23Q4 公司的互联芯片收入可实现 32%/160%的环比/同比增长,同时考虑到津逮服务器业务约 2 亿元的 减值影响,预计 23 年全年营收 22.84 亿元,归母净利润约为 4.75 亿元。
分业务来看,我们预计 23Q4 DDR5 RCD 业务板块随着 DDR5 渗透率进一步提高带动季度业绩上升,预 计 23 年 Q4 营收约为 7.6 亿元,环比增长 27%;净利润约为 2.65 亿,环比增长 52%。23 年全年营收 22.84 亿元,随着 DDR5 的出货量提高澜起科技的营收及净利润逐步上涨。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
精选报告来源:【未来智库】。未来智库 - 官方网站











