大模型训推带动 AI 算力需求增长, GB200 等新一代算力架构将推出,算力产业链中的 AI 芯片、服务器整机、铜连接、 HBM 、液冷、 光模块、 IDC 等环节有望持续受益。
幻影视界 今天分享的是人工智能AI 算力 行业研究报告: 【AI算力「卖水人」系列(3):NVIDIA GB200:重塑服务器铜缆液冷HBM价值 】 。
研究报告内容摘 要 如下
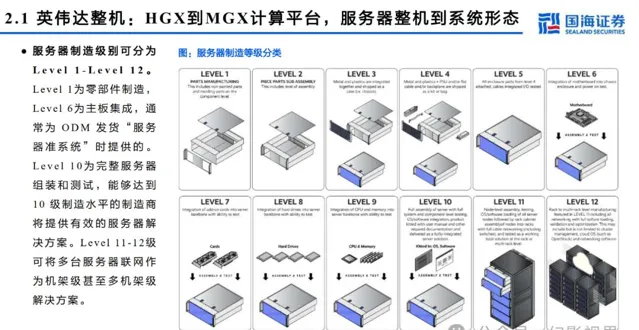
服务器细节拆分:主板从 HGX 到 MGX , GB200 NVL72 价值量提升
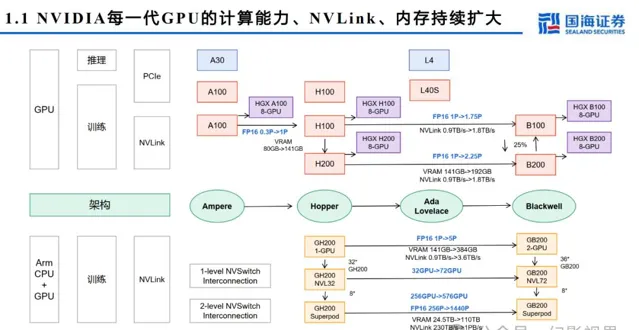
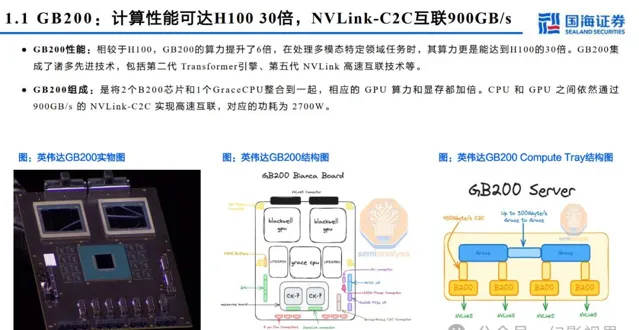
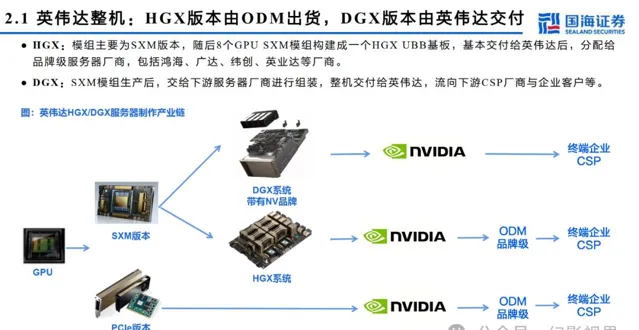
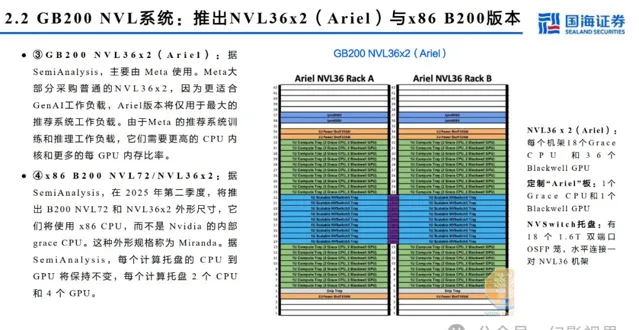
GB200主板从HGX模式变为MGX,HGX是NVIDIA推出的高性能服务器,通常包含8个或4个GPU,MGX是一个开放模块化服务器设计规范和加速计算 的设计,在Blackwell系列大范围使用。MGX模式下,GB200 Switch tray主要为工业富联生产,Compute Tray为纬创与工业富联共同生产,交付给英 伟达。据Semianalysis,有望带来机柜集成、HBM、铜连接、液冷等四个市场价值量2-10倍提升。

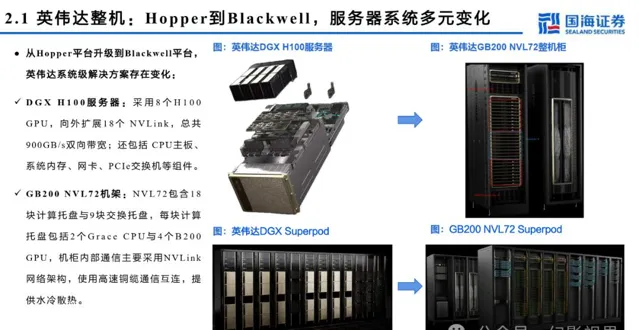
英伟达整机: GB2 0 0 NVL7 2 训练与推理能力倍数提升
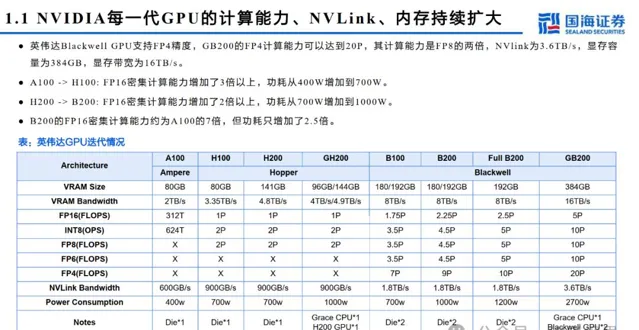
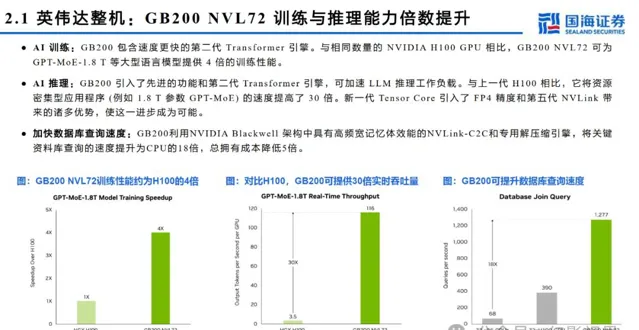
AI 训练: GB2 0 0 包含速度更快的第二代 Tr a n sf o rme r 引擎。与相同数量的 NVIDIA p 0 0 GPU 相比, GB2 0 0 NVL7 2 可为 GPT-MoE-1.8 T 等大型语言模型提供 4 倍的训练性能。
AI 推理: GB200 引入了先进的功能和第二代 Transformer 引擎,可加速 LLM 推理工作负载。与上一代 p00 相比,它将资源 密集型应用程序 ( 例如 1.8 T 参数 GPT-MoE) 的速度提高了 30 倍。新一代 Tensor Cor e 引入了 FP4 精度和第五代 NVLink 带 来的诸多优势,使这一进步成为可能。
加快数据库查询速度: GB200 利用 NVIDIA Bl ackwell 架构中具有高频宽记忆体效能的 NVLink-C2C 和专用解压缩引擎,将关键 资料库查询的速度提升为 CPU 的 18 倍,总拥有成本降低 5 倍。

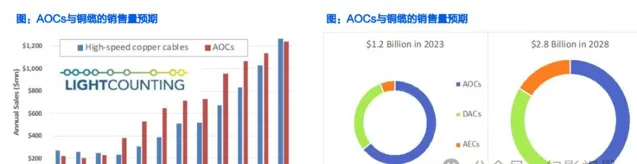
铜连接: DACs 市场较快增长, GB200 NVL72 需求较大
据 LightCounting ,受益于服务器连接以及分解式交换机和路由器中的互连需求提升, 预期高速线缆的销售额预计在 2023-2028 年将增加一倍以上,到 2028 年将达到 28 亿美元 。有源电缆 (AECs) 将逐步抢占有源光缆 (AOCs) 和无源铜线 (DACs) 的市场份额。 AECs 的传输距离更长,而且比 DACs 轻得多。
DACs 将保持较快增长, NVIDIA 需求较高。 新的 100G Se rDe s 使 100G / l ane 设计的无源铜缆的覆盖范围比预期的要长,包括 400G 、 800G 和 1.6T DACs 。据 LightCounting ,预计 2024 年底开始发货的 200G Se rDe s 表现出色,这将使 DACs 扩展到每通道 200G 的设计,由于 DACs 不需要电,因此它是努力提高电力效率的数据中心连接的默认解决方案。最小化功耗对 AI 集群来说是 最关键的。 Nvidia 的策略是尽可能多地部署 DACs ,只有在必要的情况下才使用光模块。
冷板式液冷较为成熟, GB200 NVL72 采用液冷方案
AI大模型训推对芯片算力提出更高要求,提升单芯片功耗,英伟达B200功耗超1000W、接近风冷散热上限。液冷技术具备更高散热效率,包括冷板式与 浸没式两类,其中冷板式为间接冷却,初始投资中等,运维成本较低,相对成熟,英伟达GB200 NVL72采用冷板式液冷解决方案。
幻影视界整理分享报告原文节选如下:


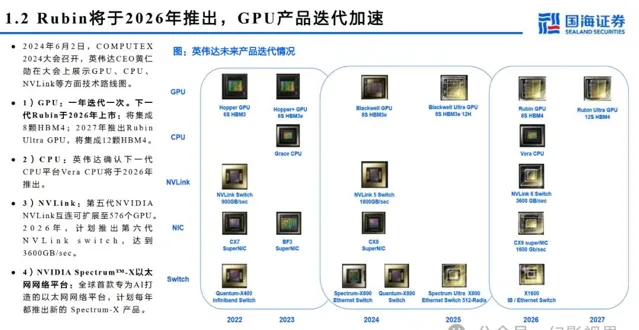
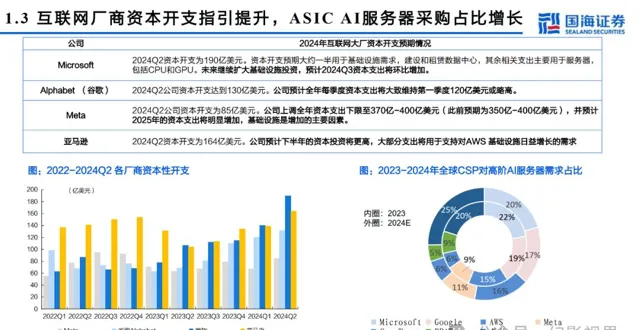
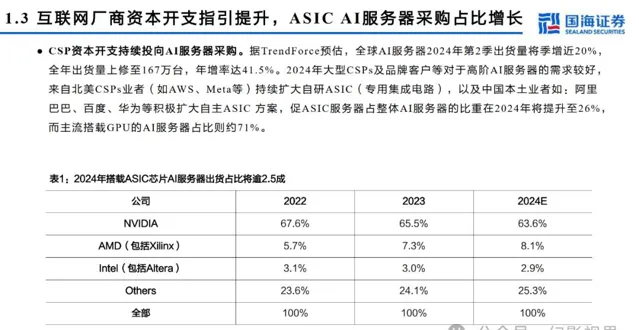
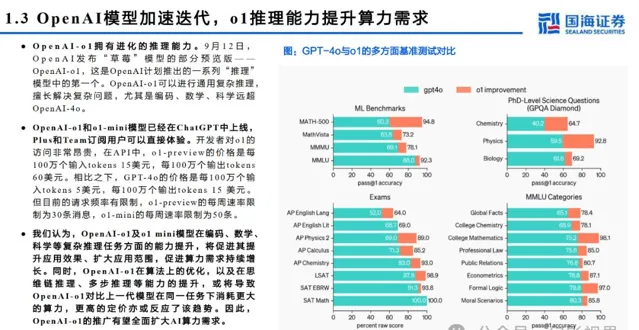




本文仅供参考,不代表我们的任何投资建议。 幻影视界 整理分享的资料仅推荐阅读,用户 获取的资料 仅供个人学习,如需使用请参阅报告原文。











