
人工智能:GPU如何塑造计算与AI领域的变革
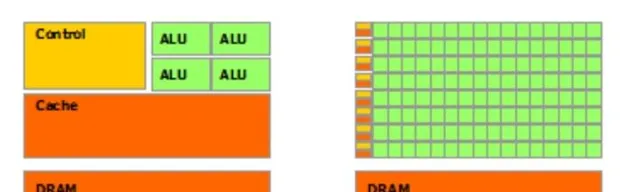
在人工智能的时代,一位默默无闻的英雄正在改变数据处理的格局,那就是图形处理单元(GPU)。即使你不是科技从业者,作为游戏爱好者,你也可能体会到GPU在提升游戏体验方面的强大作用。如今,NVIDIA凭借其强大的GPU技术在科技界占有一席之地。这些处理器可以同时进行成千上万的操作,在训练和运行大型语言模型(LLM)以及各种AI算法中发挥着重要角色。值得关注的是,GPU究竟是什么?它是如何运作的?又为何对人工智能如此重要?
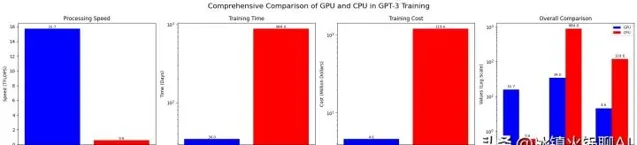
尽管GPU在处理复杂计算上表现出众,我们依然需要它们来训练大型语言模型。为了更好地理解GPU的强大之处,我们来看看一个实际案例:训练GPT-3这一先进语言模型,大约需要34天的时间。如果是使用传统的CPU,时间会更漫长,你能想象大约要多久吗?(答案是无比久!)

作为一名人工智能领域的研究者,我决定深入探讨GPU对AI的影响,并与大家分享我的发现。请随我一起解答这些问题,探索这些小硅片如何在重塑人工智能的未来。
GPU的历史与AI的结合


在GPU普及之前,AI模型主要是通过CPU运算。使用CPU的方法不仅浪费电力,还存在时间上的巨大消耗。CPU核心数量有限,无法高效地处理大型复杂模型。为此,GPU作为新型芯片应运而生。随着AI模型的日益复杂,对并行计算的需求显著增加,研究者们意识到GPU凭借其独特的并行架构和数千个处理核心,可以更胜于CPU。

进入2000年代后期,利用GPU来加速AI模型的训练已成为一种趋势,结果显示这些芯片能极大地缩短训练时间。但最基本的问题依然存在,GPU与CPU的区别到底在哪里,为什么GPU在AI领域表现更为优异?

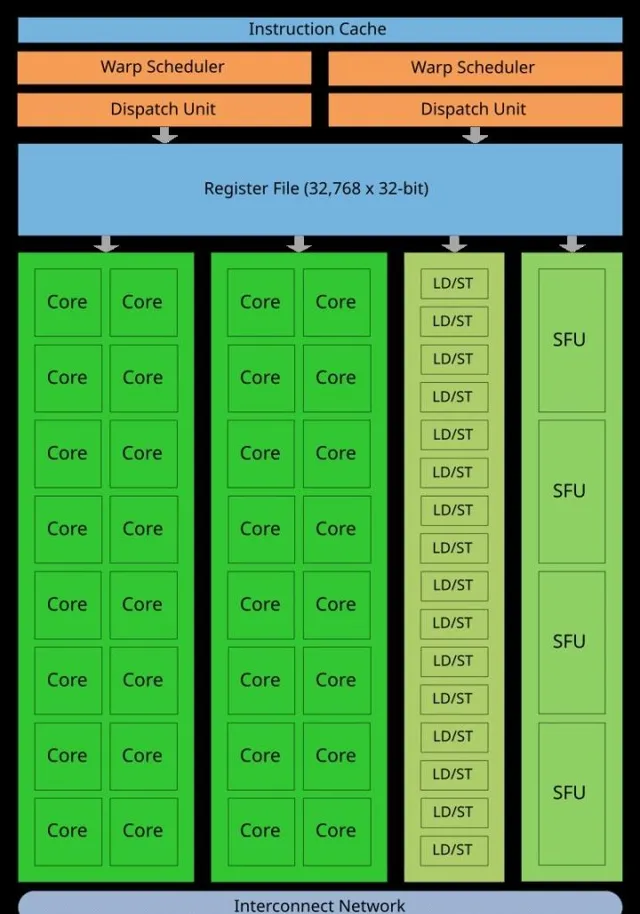
两者之间的差异,首先体现在设计上。CPU(中央处理器)和GPU(图形处理器)都是计算机系统的核心组成部分,但二者被设计的初衷截然不同。CPU适合处理复杂而多变的任务,通常核心数量在2到16之间,专注于顺序处理。而GPU则拥有更多的小型核心,通常在数千个左右,善于并行处理任务。因此,GPU能够高效地执行多项任务,尤其在图形渲染和科学计算中表现出色。
为深入理解GPU和CPU的差异,以下数据或许能揭示一二。如果我们以训练GPT-3为例,该模型的训练需要10,000个NVIDIA V100 GPU,并且大约耗时34天。这一过程的成本约为460万美元,而整个计算量大约为3.14E23次浮点运算。相对来看,一个NVIDIA V100 GPU每秒能执行约15.7万亿次浮点运算,而CPU的速度则低得多。在这情况下,若换用CPU进行训练,所需时间几乎会翻倍,达到884天,训练成本更是可能膨胀至约1.2亿美元。
GPU的演变与创新
图形处理领域的发展起源于20世纪80年代。1986年,德州仪器推出了首批可编程图形处理器,随后的1999年,3Dlabs推出了专门用于3D渲染的GPU,成为行业里程碑。进入21世纪后,NVIDIA不断推出新产品,使GPU逐渐从图形领域扩展至通用计算。2006年,NVIDIA发布了CUDA并行计算平台,改变了科研和数据处理的游戏规则。
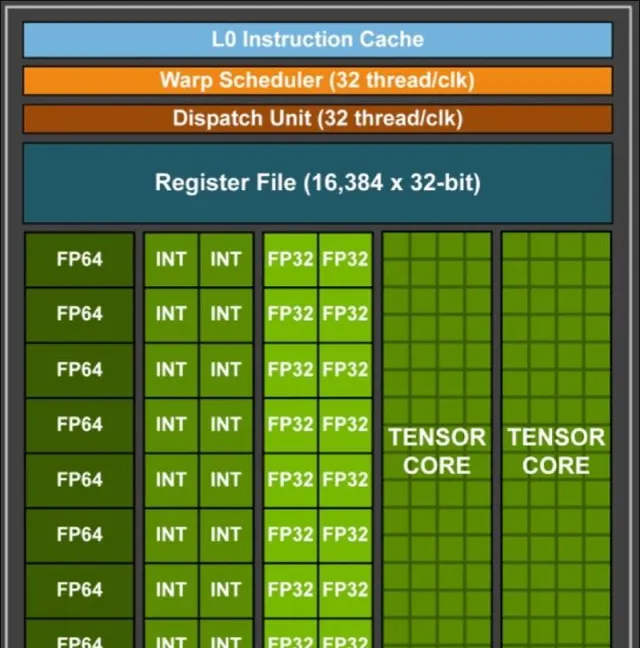
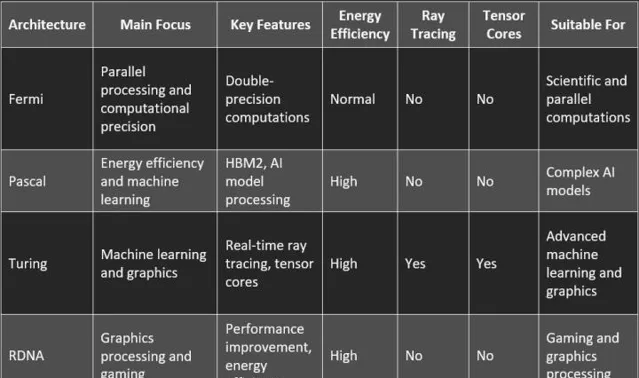
伴随着计算技术的进步,NVIDIA在2010年代推出了以Fermi架构为基础的GeForce 400系列,进一步提升了AI计算的处理速度。之后的每一次升级,都是在不断向更高效、大规模处理能力迈进。英伟达的Blackwell架构就涵盖了2080亿个晶体管,既确保了出色的处理能力,又提升了AI模型的训练效率。
结语
本文探讨了GPU在现代计算、特别是在AI领域的重要性。随着处理能力的提升,像OpenAI的o1模型等的性能也大幅增长。GPU的未来将通过神经形态芯片的发展进一步扩展智能机器的潜力,而深度学习计算的需求也将促使新的创新不断涌现。随着每一次技术的迭代,我们正在一步步接近智能机器像人类一样学习和推理的未来。











