近日,在 WAIC 2024 战 略合作伙伴商汤科技召开的「大爱无疆 · 向新力」人工智能论坛上, 中国工程院院士、清华大学车辆与运载学院教授李克强发表了一场演讲。
在为「车路云」提供新思路的同时,他也指出了关于单车智能发展、
AI
驱动所面临的一些问题。
RoboX
结合他在本次论坛以及
CICV
的演讲,进行了梳理总结。
大模型面临的两大挑战
李克强认为,迄今为止,智能汽车的技术路径主要还是以单车自主式智能为主。但通过实践,可以发现该方式还是有一系列的问题。
「自动驾驶领域的挑战,远远不像一般人所理解的那么简单。」

他指出,例如目前想做大模型的平台,存在两大问题:
一,数据体量有限,无法实现训练数据的海量性。
二,第二数据种类不全,保证不了数据的完备性——如果数据不具备完备性,就会出现训练不准的问题。
「例如,一家企业有十万名工人,一千名工程师。如果你统计出九万九千工人,把工程师统计为零;而我统计到八万工人,以及八百名工程师,那么显然我的数据会更加准确。」
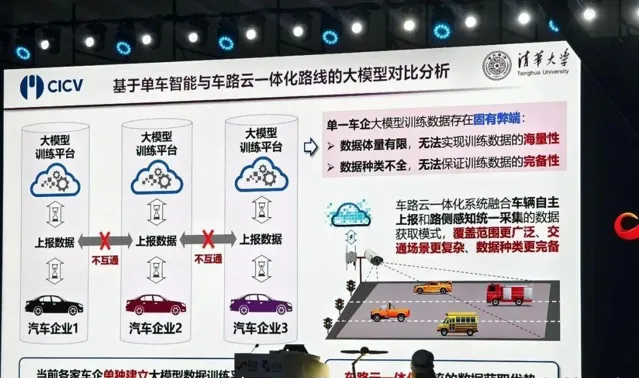
李克强表示,大模型的一个关键点在于数据训练 。 而 数据有三个要素:海量性、完备性和准确性。
如果由单一企业负责数据,那怕数据再多,也统计不全。只有通过车路云一体化的系统,才能真正覆盖各家车企的数据。
另外, 路侧相当于「上帝视角」,看得更远更全,数据覆盖更广泛。
在李克强看来,新一代的FSD已不再是传统的单车智能了,因为「影子模式」+「大模型」都是车和云之间的协同。
但即便如此,若只靠特斯拉自身来做, 没有路侧数据,再多的车端数据也无法补齐数据的完备性,训练也不会准确。

李克强称,基于这样的背景,智能网联汽车国家创新中心希望整合全行业共识,提出了「云控基础平台」的思路。
「所谓的云控基础平台,就是将竞争的分开,底座打通,以一个基础平台包含交通管理、出行服务、娱乐服务,包括自动驾驶。」
李克强认为,这样才能够真正做到众源数据的汇聚,海量信息的打通,以及时空连续对齐,对于实用化且符合高标准要求的自动驾驶AI大模型的构建、训练与迭代,都是至关重要的。
端到端不是「神经网络黑箱」
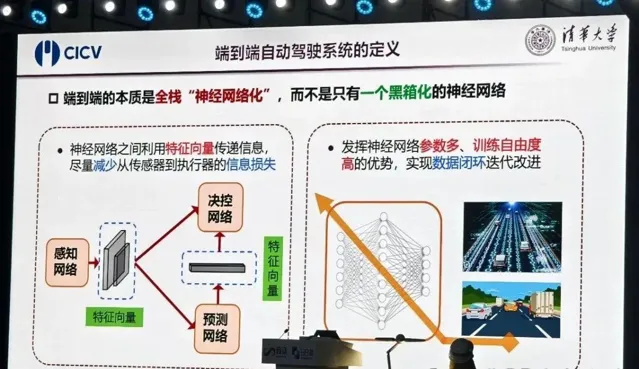
「端到端的定义,不是一个简单的黑箱化神经网络,而是全栈的神经网络化,仍然会有感知网络、决策网络、预测网络,只不过端到端采用了特征向量的方式,使得数据能够完整传递。」李克强说道。
他认为,端到端方案对于数据完备性的要求更高,同样只有实现车路云一体化,才能确保有效训练。
目前,在清华大学研究的端到端方案中,既有分块模型的预训练,也有模块集成微调。
「其中每个模块都是大模型,合起来也就是端到端。我们将按照这一逻辑来推进工作,并会率先在开放道路上进行验证。
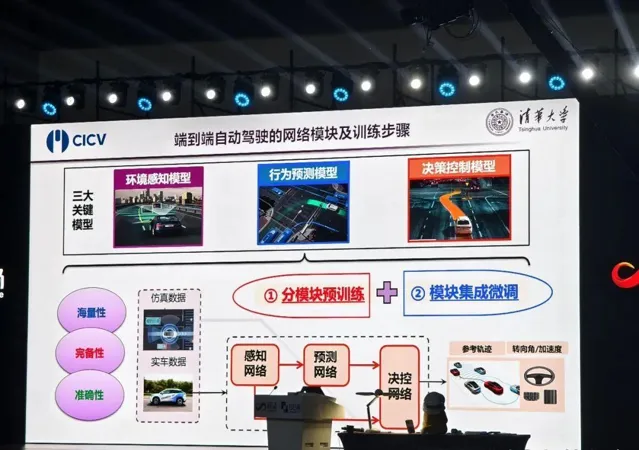
在李克强看来,端到端的重点是要推动主要功能模块的全栈神经网络化,以及数据闭环的训练。
清华团队的工作进展
据李克强表示,清华大学团队很早就开始在强化学习、类脑学习这些方面做探索。
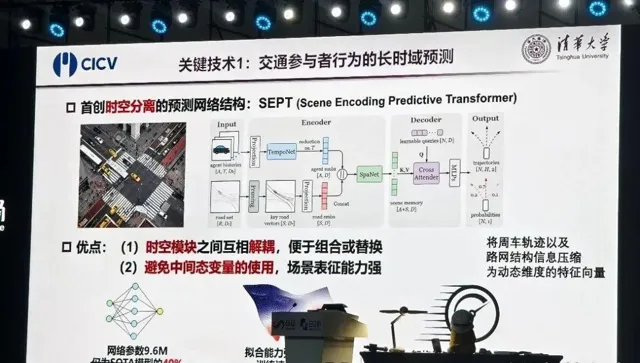
其中一项探索是 「关于交通参与者行为的长时域预测」 。
他介绍称,交通行为预测是自动驾驶决策控制的前提。然而,由于交通环境的复杂性,现有的预测方法存在一系列问题,如网络结构复杂、计算成本高、中间变量多以及信息损失大等。

针对这些问题,清华团队提出即时空分离的预测网络结构——将周车轨迹、路网结构信息压缩为动态特征量,并在此过程中实现时空模块之间的相互解耦,使得各模块更易于组合或替换,避免不必要的中间态变量,获得更强的场景表征能力。
该团队也将强化学习类脑智能运用在自动驾驶中:「‘强化学习求解’应用到工业控制中,有一个很大的挑战,就是所谓的‘过估计’。由于有贝尔曼算子,使我们的 算子在迭代过程中的误差累积增大。在自动驾驶这样复杂的控制系统里,这些问题尤其严重。 」
就此,清华团队提出了DSAC分布式的柔性的自动判断准则。根据SAC算法,看到强化学习算法中的最大化选择器在每次选择评估行动时都使用同样的Q值,将其增加到若干个分布式以后,它可以变成一个分布式贝尔曼算子。 该思路可以让 估计的误差得到一致。
「用了这套方法以后,我们可以在信息的实时性,包括准确性、估计偏差方面,相比现有的方法都取得了显著的提升。」
单车智能和车路云并不矛盾
「单车智能和车路云一体化完全不矛盾,我们只有把单车智能做好,才能往上发展,才能做到车路云一体化。」
李克强认为,单车智能是车路云一体化的基础,而车路云一体化是单车智能的升级。它们各有优势、各有结合。

他指出,单车智能之所以需要车路云一体化,是因为目前单车系统的自主决策、全局性能难以优化,但可以利用车路云一体化做到,避免单车智能的立体特征造成交通事故和拥堵。
另外,智能汽车的发展最终还是要拼算力,车载算力从成本、使用条件角度来看还是受到限制。
「我们可以把车载计算任务卸载,通过一体化的方式实现。」 李克强提出,单一企业很难做出真正意义上的大模型,主要原因还是上述的数据完备性问题。
用了车路云一体化的方式,可以从自主车辆和路侧获得更加完整的数据模式,能够覆盖更加广泛、交通场景更加复杂、数据种类更加完备,所以数据种类完备不是一家企业一种方式能够做的,而是协同式的,就是从各方获取的。
「我们都在谈BEV+Transformer。如果在未来,这样的模型训练不仅是车端,还有路侧,就更容易形成数据闭环中具有影子特征传递构建的自动驾驶端到端模型,扩展上限能力。」











