大模型芯片轰向HotChips顶会!
人工智能芯片的崛起:RNGD如何撬动生成式AI的未来
人工智能的前景广阔,但其发展历程却并非一帆风顺。从计算能力的瓶颈,到能耗问题层出不穷,业界对于实现AI的可持续发展一直在不懈探索。然而,最近一家名为FuriosaAI的初创公司悄然崛起,凭借其创新的张量收缩处理器(TCP)架构,推出了一款名为RNGD的AI芯片,有望突破行业僵局,为生成式AI注入新的活力。
RNGD芯片的亮眼表现绝非偶然。它不仅在性能上大幅领先业内知名的英伟达和AMD等GPU,更在能效方面实现了质的飞跃,可谓是真正实现了AI计算的高性能与高能效的完美平衡。这种创新成果的背后,是FuriosaAI团队多年潜心研究和迭代的结果。
RNGD的成功绝非一日之功。FuriosaAI成立于2017年,创始团队由三名来自AMD、高通、三星等芯片巨头的资深工程师组成。他们在硬件和软件领域积累了丰富的经验,洞见了AI计算发展的痛点所在。为此,他们开启了对新型芯片架构的研发,最终孕育出了RNGD这一代表性产品。
那么,RNGD究竟有何独特之处,能够成为颠覆性的AI计算硬件?其背后的技术创新又是什么?未来它又将如何引领AI计算的可持续发展?让我们一起去探寻这位"AI芯片新星"的崛起之路。
引领AI计算新时代的RNGD

AI计算正在掀起一场前所未有的革命。从图像识别到语音交互,再到智能决策,AI技术正在深入渗透人类生活的方方面面。伴随着模型规模的不断扩大,对计算性能的需求也呈指数级增长。但是,当前的计算硬件难以应对如此巨大的计算需求,不仅存在性能瓶颈,能耗问题更成为制约行业发展的沉重负担。
RNGD的出现,无疑为解决这一问题带来了新的转机。这款由FuriosaAI研发的AI芯片,在性能、能效以及可编程性等方面都展现出了出色的表现,引发了业界广泛关注。
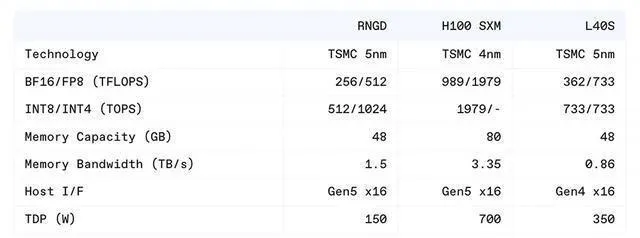
首先,在性能方面,RNGD可以轻松运行Llama 3.1等大型语言模型,单卡可提供每秒2000~3000个token的吞吐量。与英伟达的p00和L40S相比,RNGD的每瓦性能分别高出2.7倍和4.1倍。这一成绩来自于其创新的张量收缩处理器(TCP)架构。
与传统的矩阵乘法不同,TCP架构采用更加通用的张量收缩运算,能够在单个操作中组合多个维度上的元素,从而减少计算开销,实现更广泛的并行性。与此同时,通过采取聪明的数据重用策略,RNGD大幅降低了芯片与内存之间的数据传输,进而显著提高了能效。
以RNGD运行Llama 3.1模型为例,其功耗仅为150W,相比同类产品要低得多。这得益于其出色的能效表现。FuriosaAI团队表示,对于所有芯片架构来说,在DRAM和处理单元之间传输数据,所消耗的能量可能高达计算能量的10000倍。为此,RNGD通过精心设计的数据重用策略,最大限度地减少了数据移动,从而大幅降低了能耗。

那么,如何实现这种数据重用呢?关键在于RNGD采用的张量收缩架构。与传统的二维矩阵乘法不同,RNGD的基本数据结构是张量,这使得它能够在执行计算之前,就充分利用张量固有的多维性质来实现更广泛的并行性。
同时,RNGD的架构还包含一个强大的编译器,能够将整个AI模型视为单一融合操作,实现自动部署和优化。这大大提升了RNGD的可编程性,使其能够灵活适用于快速变化的AI模型。这与GPU动态分配资源、难以准确预测性能的特点形成鲜明对比。
RNGD在性能、能效和可编程性三大方面的出色表现,无疑为生成式AI的应用注入了新的动力。它不仅能够轻松运行Llama 3.1等大型模型,而且还可以在数据中心环境中实现高性能和低功耗的兼备,从而大幅降低企业的使用成本。这对于推动AI技术的可持续发展,意义重大。
FuriosaAI的艰辛历程
RNGD的成功并非一蹴而就。它背后是FuriosaAI多年孜孜以求的研究与实践成果。从创立之初,这家初创公司就坚持走自主创新的道路,聚焦于AI计算硬件的技术突破。

FuriosaAI成立于2017年,由三名资深芯片工程师联合创办。他们曾在AMD、高通、三星等业界巨头工作多年,积累了扎实的硬件和软件经验。正是凭借这些宝贵的积累,他们洞见了当前AI计算领域存在的痛点,决心开发一款能够真正满足生成式AI需求的芯片产品。
在创立之初,FuriosaAI首先花费几年时间来和验证其自主研发的TCP架构背后的理念。这并非一项容易的工作,需要反复论证、修正和迭代,才能最终奠定未来产品的技术基础。
完成这项基础工作后,FuriosaAI于2021年开始与三星和华硕合作,推出了第一款基于TCP架构的Vision NPU作为商业产品。这一款面向计算机视觉的NPU,凭借出色的性能表现,成功在业界引起了广泛关注。事实上,FuriosaAI还是唯一一家向行业标准MLPerf推理基准提交结果的AI芯片创企,结果显示其第一代Vision NPU在视觉任务中的表现优于英伟达A2芯片。
有了Vision NPU的成功验证,FuriosaAI团队开始着手研发面向生成式AI的新一代芯片RNGD。这一过程同样并非一帆风顺。从2022年5月收到台积电交付的第一批硅片样品,到6月初运行Llama 3.1模型,再到7月向早期客户交付并进行大语言模型演示,整个研发周期仅用了不到3个月的时间。这种高效的研发节奏着实让业界刮目相看。
FuriosaAI之所以能够实现如此高效的研发周期,首先要归功于其对TCP架构的深入理解和持续优化。有了坚实的技术基础,公司的工程师团队得以快速将新的设计方案从概念转化为成熟的硅样品。
同时,FuriosaAI还采取了一种特殊的产品开发策略,即专注于快速迭代和产品交付。这不仅体现在研发周期的缩短上,也反映在公司的整体产品定位和营销方式上。
相比行业内一些以炒作和大胆承诺为主的做法,FuriosaAI更多关注实实在在的技术创新。正如公司高管所说,Furiosa95%的人员都是工程师,营销并非首要考虑。他们更看重的是如何通过不断的迭代优化,尽快推出真正能解决用户痛点的产品。
这种"低调"的产品策略,也反映了FuriosaAI的团队文化。他们并不过多地关注外界的炒作,而是专注于技术创新本身。这种与众不同的做法,恰恰成为了推动RNGD快速发展的内在动力。
从愿景到实践:Furiosa如何破解AI计算难题
RNGD的出众表现,源于FuriosaAI团队对AI计算领域痛点的深入洞察。

长期以来,AI计算在性能、能耗和可编程性等方面一直面临着诸多挑战。即使是当下最先进的GPU,也难以完全满足高性能、高能效和高可编程性的苛刻要求。
FuriosaAI的创始团队深知这一现状。他们认为,要实现AI的广泛普及和真正落地,关键在于开发一款能够兼顾这三大要素的创新型芯片。这也正是RNGD诞生的初衷。
在性能方面,RNGD凭借其创新的TCP架构,能够针对大型AI模型提供非常出色的计算能力。如前所述,单张RNGD卡就可以在Llama 3.1等大语言模型上提供每秒2000~3000个token的惊人吞吐量,远超业界最佳水平。
这种性能优势,主要得益于TCP架构的两大特点:广泛并行和高效数据重用。相比传统的矩阵乘法,TCP通过张量收缩的方式,在单个操作中组合多个维度上的元素,从而大幅减少计算开销,实现更广泛的并行性。
同时,RNGD还采用了一系列聪明的数据重用策略。它将中间激活结果直接用作下一层的输入,无需额外的DRAM访问,大幅降低了内存访问开销。这一创新使得RNGD在运行Llama 3.1等大型模型时,能耗仅为150W,远低于业界领先的GPU。

在可编程性方面,RNGD同样展现出了出色的表现。与依赖动态资源分配的GPU不同,RNGD搭载了一个"强大的编译器",能够将整个AI模型视为单一融合操作,实现自动部署和优化。这大大简化了部署新模型的难度,使RNGD能够更好地适应快速发展的AI技术创新。
正是这些创新性的设计,使得RNGD在性能、能效和可编程性三方面实现了难得的平衡。这一成果,也充分诠释了FuriosaAI团队提出的"AI计算普及"愿景。
正如公司首席技术官Hanjoon Kim所言,AI硬件除了能够并行执行多项计算之外,还必须提供可编程性与能效这两大关键功能。只有做到这两点,AI技术才能真正实现广泛应用。
正是基于这样的认知,FuriosaAI团队历经多年潜心研发,终于在RNGD芯片上取得了突破性进展。这款面向数据中心的AI芯片,不仅在性能上超越业内领先产品,更在能效和可编程性方面实现了全方位提升,无疑为AI计算的未来发展指明了新的方向。
当前,即便是最先进的GPU,在大规模部署高性能生成式AI模型时,也面临着难以承受的经济和环境成本。企业不仅要承担昂贵的硬件采购费用,还需投入巨额资金用于复杂的液体冷却系统建设,以及耗费高昂的电费。这无疑大大限制了这些技术在实际应用中的普及程度。

相比之下,RNGD凭借其出色的能效表现,能够大幅降低这些成本负担,为广泛部署提供可能。有了它,企业无需再投入巨资建设高能耗的GPU集群,数据中心也无需进行复杂的基础设施改造,就可以轻松运行高性能的生成式AI模型,大幅节省开支。
这种以用户需求为中心的创新思路,正是FuriosaAI团队的一大亮点。他们不满足于单纯的技术创新,而是将目光放在产品的实际应用前景上。正是瞄准了数据中心对高能效AI计算的迫切需求,RNGD才得以脱颖而出,成为当下最具影响力的AI芯片之一。
未来展望:RNGD如何引领AI计算的可持续发展
毋庸置疑,RNGD的出色表现,必将为生成式AI的未来发展注入新的动力。这款芯片不仅在性能、能效和可编程性上达到了业界顶尖水平,更重要的是,它与当前AI计算领域的实际痛点高度契合,或将成为推动行业可持续发展的关键推手。
当前,随着AI模型规模的不断扩大,对硬件计算能力的需求正呈现出爆发式增长。但传统的GPU架构,由于性能瓶颈和能耗问题,已
当前,随着AI模型规模的不断扩大,对硬件计算能力的需求正呈现出爆发式增长。但传统的GPU架构,由于性能瓶颈和能耗问题,已难以满足日益严苛的计算需求。RNGD的突破性表现,无疑为解决这一难题带来了新的希望。
这款由FuriosaAI研发的AI芯片,在能效和可编程性上达到了令人瞩目的高度。其单卡功耗仅150W,相比目前市面上的GPU节能效果可谓"碾压"级别。同时,RNGD搭载的强大编译器,能够自动部署和优化AI模型,大幅提升了可编程性,使其能够轻松适应快速更新迭代的AI技术。
这种出色的综合性能,必将大幅推动生成式AI在数据中心的落地应用。我们不难想象,有了RNGD这样的高性能、高能效、高可编程的AI芯片作为支撑,企业部署和运行大型语言模型的门槛将大幅降低。从前需要耗费巨额资金建设复杂的GPU集群,如今只需几台RNGD服务器就能轻松应对。这必将加速生成式AI在各行各业的实际应用,让人工智能技术真正进入千家万户。
同时,RNGD出色的能效表现,也必将为行业带来重大的环境效益。当前,GPU在数据中心大规模部署过程中所产生的巨额碳排放,一直是业界关注的痛点。但有了RNGD这样的低功耗AI芯片作为替代,企业无需再为高能耗而头疼,不仅可以大幅节省电费支出,还能为地球贡献一份力量,为可持续发展注入新动能。
我们相信,RNGD必将成为推动AI计算可持续发展的关键力量。它不仅在性能和能效方面达到了前所未有的高度,更通过可编程性的大幅提升,满足了企业对AI技术灵活部署的需求。这种兼顾了性能、能效和可编程性的全面创新,无疑将为生成式AI注入新的活力,加速其在各行各业的广泛应用,为人类社会的发展贡献新的动力。
文章描述过程、图片都来源于网络,此文章旨倡导社会正能量,无低俗等不良引导。如涉及版权或者人物侵权问题,请及时联系我们,我们将第一时间删除内容!如有事件存疑部分,联系后即刻删除或作出更改。











