作者丨Haoqiang Fan@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/686616390
编辑丨极市平台
相信很多人和我一样都是从「古典深度学习」时代一路走来的,面对当今「LLM才是AI「的时代,有着很多的不适应症状。看着那么多的新论文里的算法,想从头开始撸一遍发现要学习一大堆有的没的的东西,然后 paper 里提到的实验条件还吓人的高,似乎这个喧嚣的新世界和自己有点遥不可及。
那么,有没有什么办法能在「一无所有」的状态下做点啥呢?
首先,进入新时代了,要更新好自己的思想,放心大胆的当「调包侠」。而现在的确有很多很科学的包!
其中以 hugging face 的 transformers 为集大成者。实际上,从自娱自乐的 toy example,到一系列还挺有影响力的项目比如 Vicuna,LLAVA,翻开代码库,都能看到那行金光闪闪的
import transformers
甚至,翻遍整个repo,都找不到「网络结构」写在哪里,只有一行
from transformers import LlamaForCausalLM
在等着你。
而在 2024 年了,这些包的安装也没那么「阴间」,直接 pip install 回来的 transformers,accelerate,就是亲测能用的(当然,假设你已经把 pytorch、CUDA 的安装和修bug搞定了)。反正我在玩的时候真就是装了就能用,没啥玄学。
对于模型训练 ,官方文档并没有一个「最小集」的样本,不过对着文档琢磨一下还是很容易写出来的:
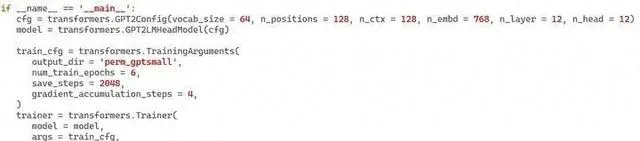
嗯,是的,一共就16行,配好两个对象,然后 Trainer.train() 就成了…… 我第一次用的时候没配 save_steps 导致跑完了不知道模型存哪了,查了一下文档才搞明白。
其中,dataset对象 就是 torch.utils.data.Dataset,要实现 __ len __ 和 __ getitem __ 的接口,这个自己搞搞就好了。
而要使用一个训练好的模型,直接
import transformersmodel = transformers.GPT2LMHeadModel.from_pretrained(ifname)
都不用自己去手工维护模型的超参数列表,这个库在 checkpoint 文件夹里已经自己按约定存好了。
然后肯定有人会提出质疑了,这么直接搞真的严肃么?
不过,让我们回想一下为啥 CV 类的模型的训练代码都那么「复杂」,然后就能发现现在的这种搞法的「科学」之处了:
transformers 里的 Trainer 集成了一些很科学的默认行为,例如定期存 checkpoint 放到实验名的文件夹下面,把各种曲线信息同步到 tensorboard、clearml、wandb 等监控软件,啥参数都不传也是可以接受的选择。
而如果你就是要调参,在 TrainingArguments、Trainer、GPT2Config 等地方一共有 138 个可以传的参数,以及大量通过调方法来填的参数,能满足不少的需要。比如,可以传一个 fp16 = True 来「一键」加速训练,而它背后是 apex.amp 这种库在支撑。
所以来说,把「靠谱」的库「集成」在一起,暴露出一组带有合理默认参数的接口,这个方法论在 2024 年来看的确还是可行的。当层层调用的这些库不「炸」的时候,使用体验相当的丝滑。
然而,如果「炸」了,或者想搞一些比较深度的 hack (比如定制某个算子在训练的时候触发一个神奇的行为),就会发现,在一行看似无辜的网络定义之上,还摞着层层叠叠的 加速库、优化库、分布式库、混合精度库等等,想去「一层层debug」就成了一件恐怖的事情。
好不容易(?)学会了序列建模这个技能(又称:transformers 库的安装与使用),不整点啥活似乎没意思。
于是,我用我的笔记本电脑(带3060显卡)训练了一个 GPT2-small 级别的模型来做 C++ 代码的补全。
我从 github 上找了一些经典的 c/c++ 的 repo(如,linux kernel,gcc,cpython,等),收集了 1G 多的 .zip,从里面找出所有的 c类源文件,形成了一个 2.2 GB 的训练集。
不做tokenization,23万步,长度 512,批大小 4,训练大概需要不到一天。
然后搞了一个贪心的补全推荐的方法,试了试,好像也不是完全不能用:
训练出来的语言模型压缩率大概是 0.7 bits / byte,比 xz -9 还是要强一点的。
考虑到实现出这样的效果,从搜索库名字到实现出来只需要一天,这还是挺惊人的了。
当然,一旦想从这个 baseline 开始提升效果,那么 language model 里各种考量的的「洪流」就要来了:
这就是一个很深很深的坑了,而 copilot 之类就是「登峰造极」之后的产物。想往这方面卷,就会一步步走入「去哪融资,去哪买卡,国产半导体何时崛起」的无尽焦虑中。
不过好的一面在于,如果我们不把自己当做一个 「训 LLM」 的人,而是当一个 「用 transfomers 库进行序列建模」 的,就会发现事情也没那么坏。虽然几十M的「小」(对 vision 来说其实不小了)模型并不会表现出「大」模型的一些独特能力,但是也已经可以做一些很有意义的事情了(我还真没试过用 CNN 硬怼上面的这个 demo 是什么效果……)。
刨开训练 transformer 类模型的一些新的技巧,当前这个时代其实最关键的问题就变成了: 手头有啥好的问题,可以表达成一个序列建模吗?
如果有,或者原来的某些「老」问题可以这么表示,那不妨用 transformer 们来试一试,也许就有全新的可能。
新的时代,就应该去拥抱新的方法。
最后,附代码补全demo的全套代码:训练
train.py
解释import transformersimport numpy as npimport torchimport osimport randomimport hashlib class CodeDataset(torch.utils.data.Dataset): def __init__(self, name, ctxlen, totalnum): super().__init__() self.name = name fname = './data/codes.txt' self.content_len = os.path.getsize(fname) self.fin = open(fname, 'rb') self.ctxlen = ctxlen self.length = totalnum def __len__(self): return self.length def __getitem__(self, index): key = int(hashlib.md5((self.name + str(index)).encode('utf8')).hexdigest()[-16:], 16) rnd = random.Random(key) while True: idx = rnd.randrange(self.content_len - self.ctxlen + 256) self.fin.seek(idx) buf = self.fin.read(self.ctxlen + 256) j = 1 while j < 256 and buf[j - 1] != (b'\n')[0] and buf[j-1] != (b'\xff')[0]: j += 1 if j >= 256: continue buf = buf[j:j + self.ctxlen - 1] if b'\xff' in buf[:-1]: continue break vec = np.frombuffer(b'\x00' + buf, dtype = 'uint8').astype('int64') vec = torch.from_numpy(vec) return {'input_ids' : vec, 'labels' : vec}if __name__ == '__main__': import argparse parser = argparse.ArgumentParser( prog = 'train', description = 'train on dataset', ) parser.add_argument('--n_embd', dest = 'n_embd', type = int, default = 768) parser.add_argument('--n_layer', dest = 'n_layer', type = int, default = 12) parser.add_argument('--n_head', dest = 'n_head', type = int, default = 12) parser.add_argument('--bsize', dest = 'bsize', type = int, default = 4) parser.add_argument('--ctxlen', dest = 'ctxlen', type = int, default = 512) parser.add_argument('--accstep', dest = 'accstep', type = int, default = 1) parser.add_argument('--compute', dest = 'compute', type = int, default = 10000) args = parser.parse_args() cfg = transformers.GPT2Config(vocab_size = 256, n_positions = args.ctxlen, n_ctx = args.ctxlen, n_embd = args.n_embd, n_layer = args.n_layer, n_head = args.n_head) model = transformers.GPT2LMHeadModel(cfg) nparam = sum([np.prod(i.shape) for i in model.parameters()]) print('nparam', nparam) model = model.cuda() name = 'code_%dM_%dT_c%d_l%d_e%d_h%d_b%d_a%d'%(nparam // 1000000, args.compute, args.ctxlen, args.n_layer, args.n_embd, args.n_head, args.bsize, args.accstep) print(name) total_train_ops = 10 ** 12 * args.compute total_train_steps = total_train_ops // (nparam * args.bsize * args.accstep * args.ctxlen) print('steps', total_train_steps) train_ds = CodeDataset('train', args.ctxlen, 1048576) eval_ds = CodeDataset('valid', args.ctxlen, 1024) train_cfg = transformers.TrainingArguments( output_dir = name, num_train_epochs = total_train_steps * args.bsize * args.accstep / len(train_ds), save_steps = total_train_steps // 10, gradient_accumulation_steps = args.accstep, per_device_train_batch_size = args.bsize, per_device_eval_batch_size = args.bsize, evaluation_strategy = 'steps', eval_steps = (total_train_steps // 10), logging_strategy = 'steps', logging_steps = (total_train_steps // 100), report_to = 'none', ) trainer = transformers.Trainer( model = model, args = train_cfg, train_dataset = train_ds, eval_dataset = eval_ds, ) trainer.train()
演示
demo.py
解释import transformersimport hashlibimport randomimport torchimport numpy as npdef sugguest_from_model(model, prefix): with torch.no_grad(): predicts = '' past_key_values = None cum_prob = 1 best_len = 0 best_sugguest = '' while len(predicts) < 32: if len(predicts) == 0: last_choice = np.int64([0] + [ord(i) for i in prefix])[None, :] ret = model.forward( input_ids = torch.from_numpy(last_choice), past_key_values = past_key_values, use_cache = True ) past_key_values = ret.past_key_values logits = ret.logits.cpu().numpy()[0, -1] prob = logits - logits.max(axis=0, keepdims = True) prob = np.exp(prob) prob = prob / np.sum(prob, axis = 0, keepdims = True) cur_predict = prob.argmax() if cur_predict == 10: break last_choice = np.int64([[cur_predict]]) cur_prob = prob[cur_predict] predicts = predicts + chr(cur_predict) cum_prob *= cur_prob if len(predicts) * cum_prob > best_len: best_len = len(predicts) * cum_prob best_sugguest = predicts if min(len(predicts) + 8, 32) * cum_prob < best_len: break return best_sugguestif __name__ == '__main__': import getch import termios ifname = './code_85M_40000T_c512_l12_e768_p2_b4_a1/checkpoint-228040/' model = transformers.GPT2LMHeadModel.from_pretrained(ifname) def demo_type(): print('loaded') attr = termios.tcgetattr(0) old_attr = attr[:] attr[3] = attr[3] & ~ (termios.ECHO | termios.ICANON) termios.tcsetattr(0, termios.TCSANOW, attr) lines = [] cur_line = '' sugguest = '' try: while True: c = getch.getch() if len(sugguest) != 0: print(' '*len(sugguest) + '\b' * len(sugguest), end = '', flush = True) if ord(c) == 27: break if ord(c) == 127: if len(cur_line) > 0: if cur_line[-1] == '\t': print('\b'*8, end = '', flush = True) else: print('\b \b', end = '', flush = True) cur_line = cur_line[:-1] elif c == '\n': print() lines.append(cur_line) cur_line = '' elif c == '\t' and (cur_line.replace('\t','') != ''): cur_line = cur_line + sugguest print(sugguest, end = '', flush = True) else: print(c, end = '', flush = True) cur_line += c def get_suggest(): ctx = cur_line i = len(lines) - 1 while i >= 0 and len(ctx) + len(lines[i]) + 1 < 200: ctx = lines[i] + '\n' + ctx i -= 1 return sugguest_from_model(model, ctx) sugguest = get_suggest() if cur_line.replace('\t','') != '': pass elif cur_line == '' and ord(c) != 127 and len(lines) > 0 and lines[-1].startswith('\t'): tabs = '' for j in range(len(sugguest)): if sugguest[j] == '\t': tabs = tabs + sugguest[j] else: break cur_line = tabs print(tabs, end = '', flush = True) if len(tabs): sugguest = get_suggest() else: sugguest = '' else: sugguest = '' print('\033[0;38;5;248m\033[0;48;5;223m' + sugguest + '\b'*len(sugguest) + '\033[0;0m', end = '', flush = True) except KeyboardInterrupt: pass termios.tcsetattr(0, termios.TCSANOW, old_attr) if len(cur_line): lines.append(cur_line) print() for line in lines: print(line) demo_type()











